Roadmap
This is a glimpse into what we're working on and what we're planning to work on.
In progress
Autoscaling for dedicated PostgreSQL clusters
Access and work in your own configurable PostgreSQL cluster, complete with autoscaling support. Sign up for the early access program.
JSON column editor
Replacing the current text editor with a JSON editor that provides syntax highlighting, validation, and more.
More zero-downtime schema migrations
Integrate the PostgreSQL tool pgroll into Xata and extend operation support for zero downtime migrations to include constraints, type changes and more.
Planned
Data privacy with custom filters for data copying
Users will have the option to apply custom filters and mark specific columns as private, when copying data from production to development branches.
Data copying on all branches
Currently, the ability to automatically copy data is limited to preview branches. We plan to expand this functionality to enable data copying across all branches.
Database-level access keys
Secure data at the database level, not just the workspace. This update allows you to assign unique access keys to each database, providing an easier way to manage user permissions and restrict access as needed.
Edge caching
Dramatically speed up repeated queries by caching them on the edge. Enable with a simple parameter passed to the API and get end-user response times as low as 15 milliseconds.
Enhanced OAuth 2.0 scopes
Xata's OAuth 2.0 support will extend beyond admin:all to incorporate more granular scopes aligned with our permission model.
Query insights and optimization
Gain detailed observability into query performance with clear recommendations for optimization.
Self-service backup and restore options
Create daily backups and restore data, with the option for point-in-time recovery (PITR).
Real-time webhooks and triggers
Call a webhook in real-time or trigger a serverless function instantaneously when a record matching specified criteria is created, updated, or deleted.
Changelog
A list of all the small and big changes we've made to the platform at a weekly clip.
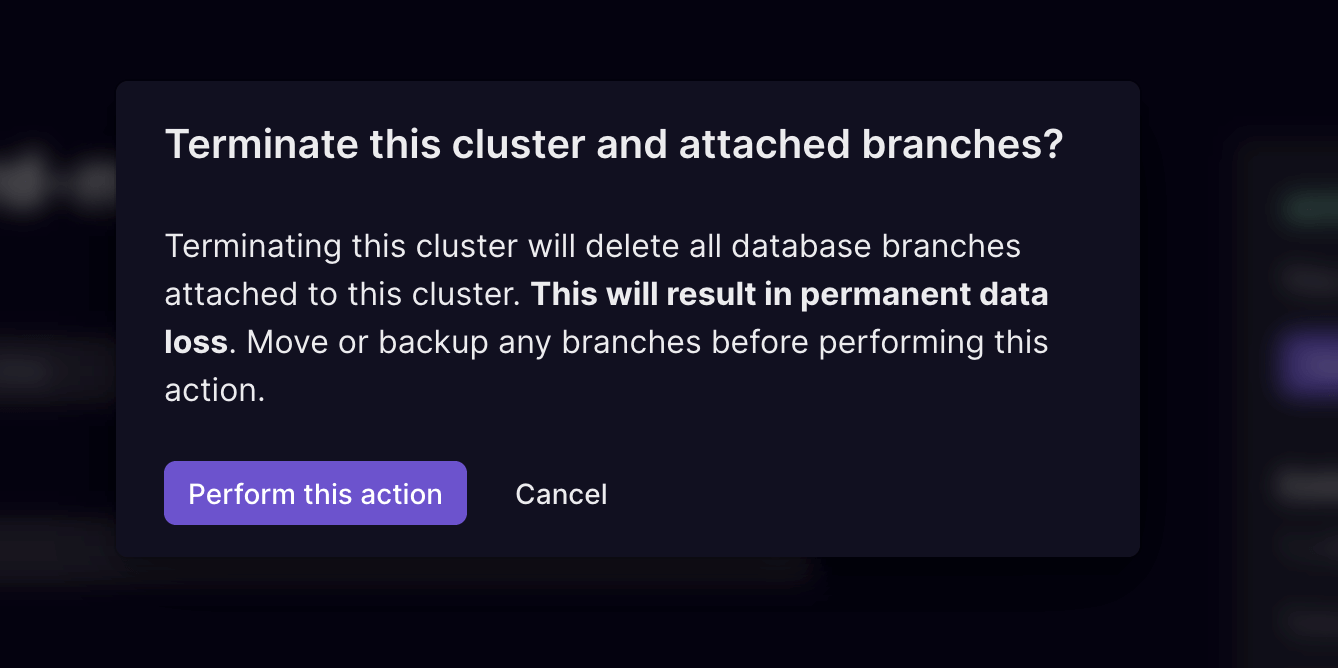
Dedicated clusters improvements
- Added support for terminating clusters via the UI.
Postgres compatibility improvements
- Added support for
NOTIFY,LISTEN, andUNLISTENcommands. - Added partial support for pl/pgsql
DOblocks. - Added support for most of the binary string functions.
- Allow users to set the identity columns for a table after the table was created.
- Better support for comments on columns.
- Added support for connection-time parameters. This is deprecated but still in-use, for example, in
psycopg2. - Added support for renaming constraints.
Blog Posts
- Guide to developing a travel application: Xata, Next.js, Tailwind CSS, & Vercel
Learn how to create a travel dashboard application using Xata, Next.js, Tailwind CSS, and Vercel to help you track your adventures and organize your travel experiences. Blog post by community member Teri Eyenike. - Simplifying critical heart transplant waitlist data with Xata
A community spotlight featuring Daniel Reale a QA engineer who used Xata to create an application for personally tracking his son's position on the Philadelphia heart transplant waitlist.
UI improvements
The UI Playground now supports running multiple SQL statements at once. This was a highly requested feature that will make it easier to run scripts in the Playground.
Other UI improvements:
- The branch selector got an upgrade and now works better with looooong branch names.
- Fixed using
now()as a default value for date columns.
Postgres compatibility improvements
Also the past couple of weeks we've seen a ton of improvements to our compatibility with the Postgres wire protocol:
- Improved compatibility with more tools that use the Postgres wire protocol, including JetBrains DataGrip.
- Added support for several system info functions.
- Allow locking clauses in SELECT statements. For example, the following is now supported:
SELECT * FROM table1 WHERE name = 'John' FOR UPDATE. - Improved compatibility and fixed issues when running Ghostfolio with Xata.
- Reduced clutter and errors during pg_restore runs.
- Added support for
SHOW session_replication_role.
Extensions!
We added support for the first extensions on shared clusters. To use them, make sure you enable direct access to Postgres.
- Added support for pgvector. You can now use either pgvector or the Xata vector implementation based on Lucene.
- Added support for the uuid-ossp extension. You can use its functions to generate different UUID flavours.
Dedicated clusters
We've worked on improving the stability and usability of dedicated clusters, currently in private alpha, but quickly moving towards public beta:
- Better validation for cluster names to prevent a common source of errors.
- Added support for terminating clusters.
- Added support limited support for DO blocks. More improvements coming soon.
Data API
Also our API, more specifically the SQL over HTTP part, got an important update:
- Support batching multiple SQL commands in a single request over the HTTP API.
- Accelerating app development with Xata as the data layer
Putting the spotlight on Mathias Eriksson (aka Matzie), founder of Matzielab, a company that has nearly perfected the app development process.
New left hand navigation
We introduced a new navigation model that explicitly separates tables from other functionality Xata provides on top of your database. This will open the door for new workflows in the coming months.
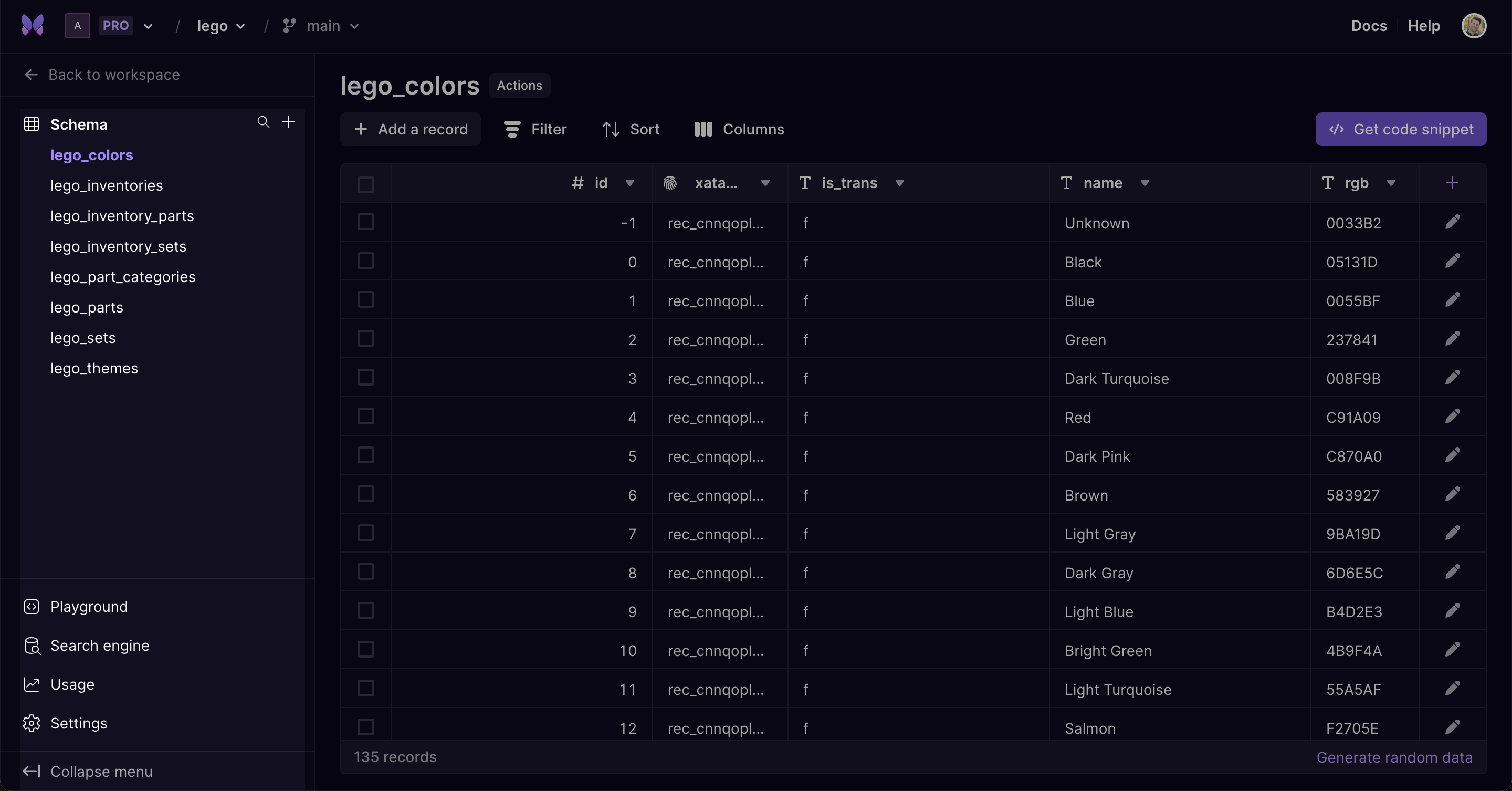
Branch usage metrics
In our last launch week, we introduced workspace usage metrics. We received a considerable number of customer requests for a more granular view, and you can now view usage metrics for every branch you have within your workspace.
Beautified empty table state
Our empty state for a new database got a makeover. Looking pretty good, eh?
- v0.6.0 was released 🎉
- 🪝 Add support for 'hooks' so that users using
pgrollas a Go module can customize its behaviour (#290, #335) - 🚥 Backoff and retry DDL and DML operations on
lock_timeouterrors (#353) - 🔗 Run all DDL operations before running any DML (data backfills) during migration start (#289)
- ✖️ Support changing multiple column properties in one
alter_columnoperation (#338) - 🖊️ Support rewriting or rejecting user-defined SQL using transformers when using
pgrollas a Go module (#329, #332). - 🫱 Allow changing column default values (#346)
- 📛 Support for renaming constraints. (#293)
- ✅ Allow raw SQL migrations to be run on migration completion instead of start (#280).
- 🔑 Allow setting the
ON DELETEbehavior of foreign key constraints (#297)
- 🪝 Add support for 'hooks' so that users using
- Export
OpAlterColumn.IsRenameOnlymethod #357
Applications usingpgrollas a module may need to test if an alter column operation is only a column rename operation without having to duplicate the logic of checking the fields of theOpAlterColumnstruct. - Support create/drop index with uppercase names #356
Fixes #355. Postgres stores index names with uppercase characters in thepg_indexcatalog using the quoted version of the name. This makes it necessary to strip quotes from index names when retrieving them from thepg_indexcatalog when building the internal schema representation. - Make
downSQL in rename column operations use the new name of the column #354
Ensure that 'alter column' operations that rename a column and also specify down SQL (such as those that alter some other column attribute at the time of the rename) must use the new name of the column in the down SQL. - Dont duplicate
CHECKconstraints andDEFAULTs when altering column type #349
Fixes #348. This PR changes column duplication to ignore errors onDEFAULTandCHECKconstraint duplication that look as though they are caused by a change of column type. - Retry on
lock_timeouterrors #353
Fixes #171. This PR retries individual statements (like the DDL operations run by migration operations) and transactions (used by backfills) if they fail due to alock_timeouterror. The retry uses an exponential backoff with jitter.
- fdw: init submodule with helpers to implement foreign data wrappers #52
Implementfdw.Optionsrelated types and helper to validate options. When implementing a foreign data wrapper one should implement a handler that returns a list of callbacks and a validator function that validates the settings FDW SQL statements will accept. So far the module only implements helpers for the validator. - fmgr: Make error return optional in exported SQL functions #51
Allow Zig based SQL functions to not return a Zig error. Now you can write:fn myfunc() void { ... } - elog: Add hints and details #50
Add support to report additional hints and details when erroring. - List: add iteratorFrom #49
AdditeratorFromandreverseIteratorFromto create an iterator directly from a list type declaration. - C: add more headers #48
Added headers foraccess/reloptions.h,catalog access, foreign data wrappers
- Club Xata reunion: teamwork across borders
Amidst breathtaking views of the Portuguese hilly landscape and early summer sun, we recap our Spring 2024 offsite in Evora for connecting and collaborating with our colleagues. - Simplifying license management and reducing costs with AWS and Xata
Putting the spotlight on Ilia Gandelman, who significantly improved a cumbersome software license management system for smart rehabilitation therapy devices using Xata and AWS. - Geographically distributed Postgres for multi-tenant applications
Documenting a pattern for making multi-tenant applications global by distributing the data, using only standard PostgreSQL functionality. - Developing a personalized mood enhancement service
Putting the spotlight on Dr. Ndubuisi Ekwueme (aka Dr. Dubz), who recently launched Moodly, a service that aims to brighten its users moods.
- We continued to improve the Postgres wire compatibility with more clients and ORMs:
- Improved the extended wire protocol by supporting flows not starting with a
Syncmessage. - Added support for the
DEALLOCATEstatement. - Added support for
current_user,current_role,session_user, anduserfunctions. - Added support for
GREATESTandLEASTfunctions. - Correctly handle
CommandCompleteandEmptyQueryResponsemessages in the Postgres wire protocol. This fixes a bug where the client would hang in particular situations. - Added support for
information_schema._pg_expandarrayover the Postgres wire protocol. - Clarified error message on failed internal authentication.
- Improved the extended wire protocol by supporting flows not starting with a
- We also continued to improve Dedicated Clusters, currently in private alpha:
- It's now possible to enable extensions (
CREATE EXTENSION). - Backend support for self-service cluster termination, frontend coming soon.
- Email notifications for cluster events.
- It's now possible to enable extensions (
- The admin UI also got a nice set of improvements:
- Add support default, unique, and not null constraints on all column types in the UI schema editor.
- Nicer "branch not found" error page.
- Copy button in the Edit record dialog for the disabled fields.
- Fixed last calendar month view in the Usage page.
- Fixed email column type validation to match the backend.
- Fixed bug when editing columns of type "multiple".
- Fixed error when filtering by a File column being NULL.
- Fixed scrolling issues on workspace pages.
- The
xata schema editCLI command now works with Postgres wire protocol enabled branches.
- #341 Allow rename-only
alter columnoperations on unbackfillable columns. Rename operations don't require backfills so there is no reason to impose such a restriction. - #344 Add a
set commentsub-operation toalter column. The intention is that this can be combined with achange typesub-operation if there is some column metadata that should be updated as part of the type change. - #345 Support setting table and column comments to NULL. Without this change it was impossible to remove a comment from a column using the
set commentsub-operation - #346 Add a
set defaultsub-operation toalter column.
-
We have continued to improve the SQL compatibility with Postgres for our shared clusters:
- Allow sub-queries in INSERT/UPDATE statement
- Allow
server_version_numsetting - Allow
SET CONSTRAINTScommand
-
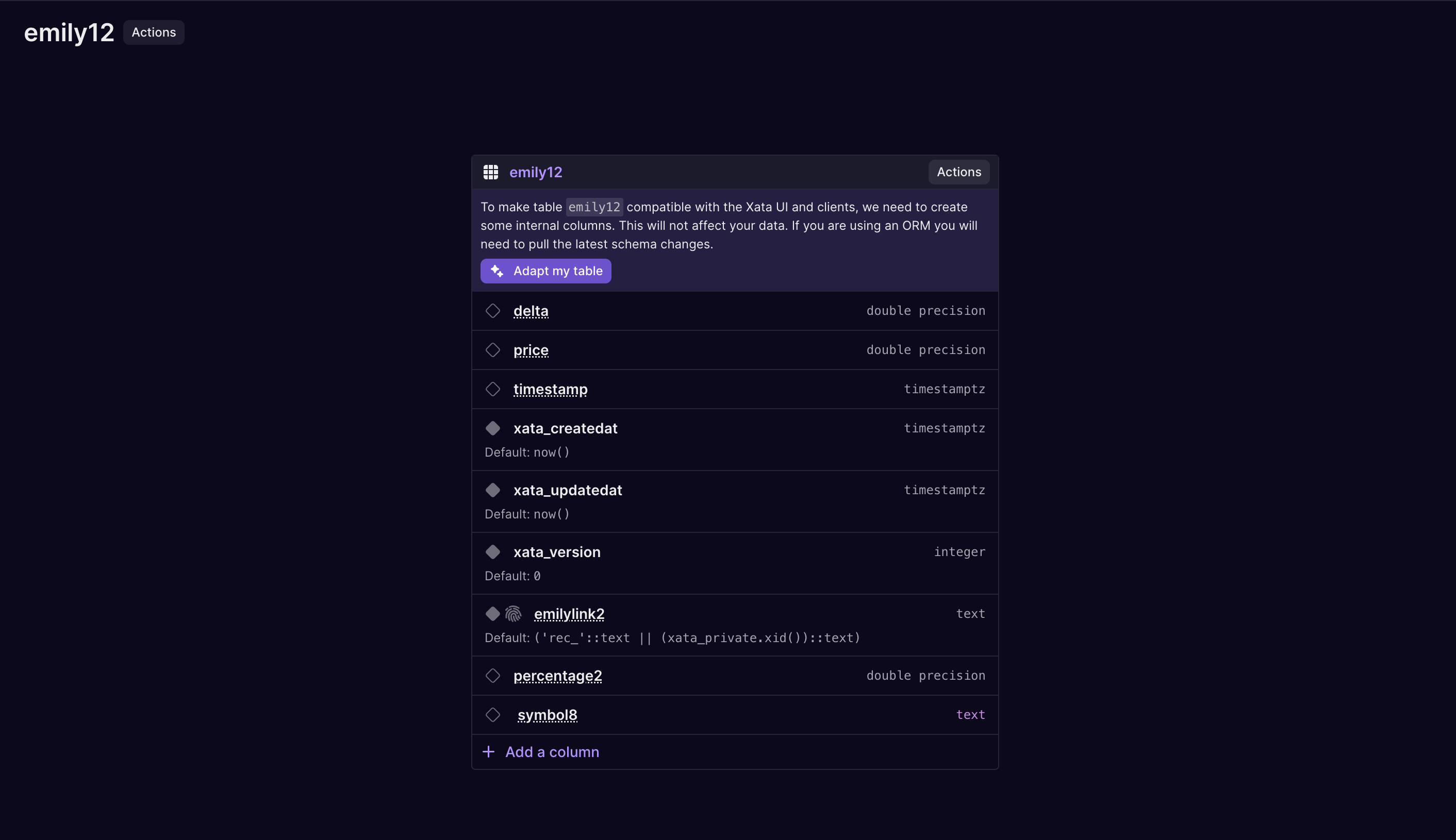
Improved the message ORM users see after adapting a table schema. Because "adapt" adds a few columns, it is important to pull/introspect the schema after making changes to the table.
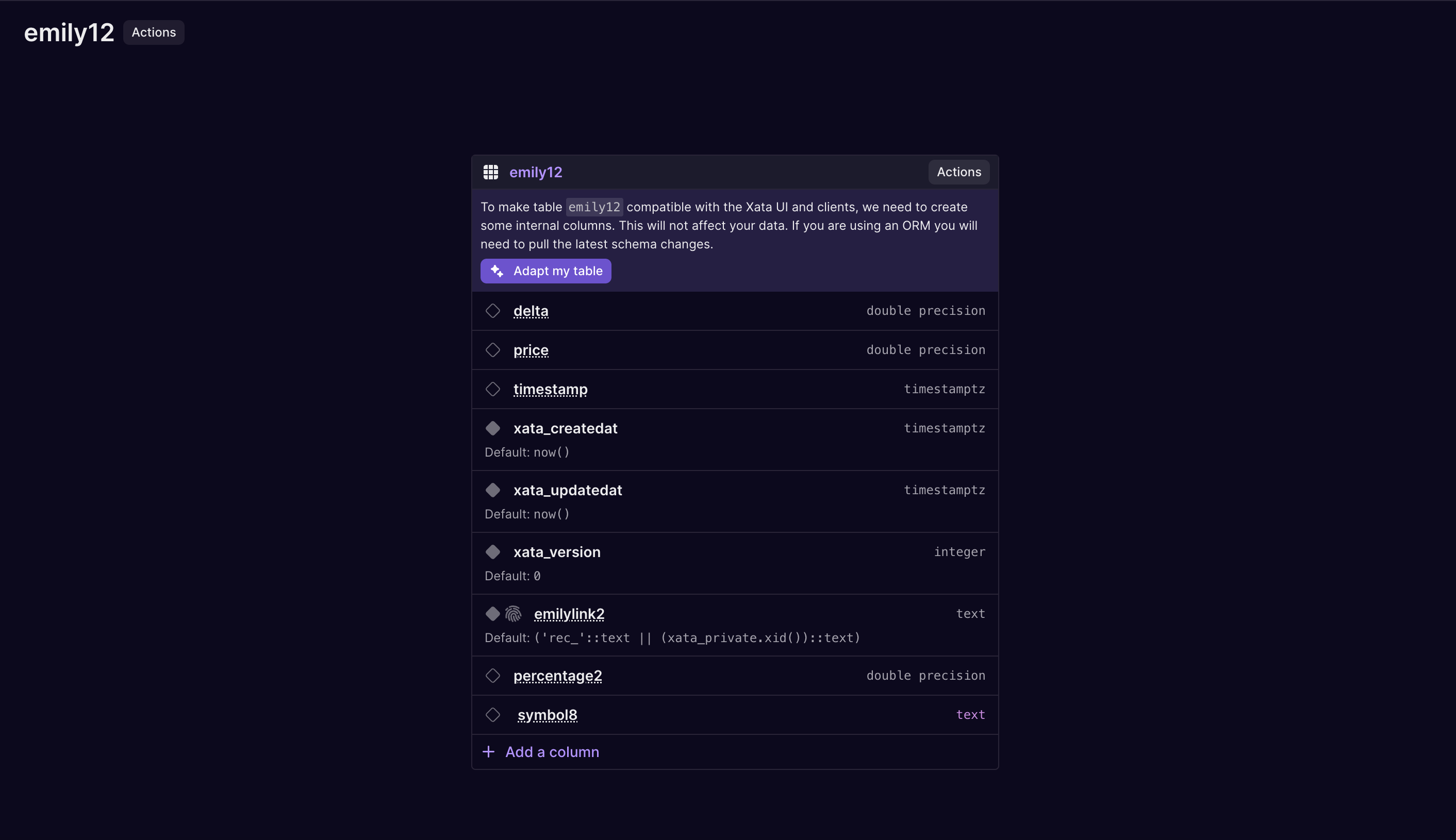
Adapt message for ORMs -
File Attachments: Return all file object properties in upload response. This can simplify your code when using upload URLs.
-
If you don't specify a branch name in the Postgres wire connection string, we will default to the
mainbranch. -
Fix: Close Postgres wire connection when a database branch is deleted.
-
Fix: Improve retry logic for outdated query plans errors.
-
Improved error handling: if we get a 400 from Elasticsearch, we will now return a 400 to the client.
- #342 Restrict the search path of the connection used by the state package to only the state schema (the schema that contains the migrations table). This ensures that any column types that might reside in other schema are always qualified with the schema name in the internal schema representation.
- #338 Support multiple
ALTER COLUMNsub operations in a single migration. - #335 Add complete phase hooks.
- #40 Improved SPI support and added an SPI example extension.
- #39 libpq improvements: Use correct types in C helpers instead of
void*. This also improve the Zig code as we do not have to cast between types and opaque pointer types. - #38 Collection hashtable: add valuesIterator
- Build authenticated and paywall pages with Stripe and Xata by Rishi Raj Jain - This tutorial shows you how to build protected and paywall pages using using Astro, Stripe, Lucia Auth, Xata and Vercel.
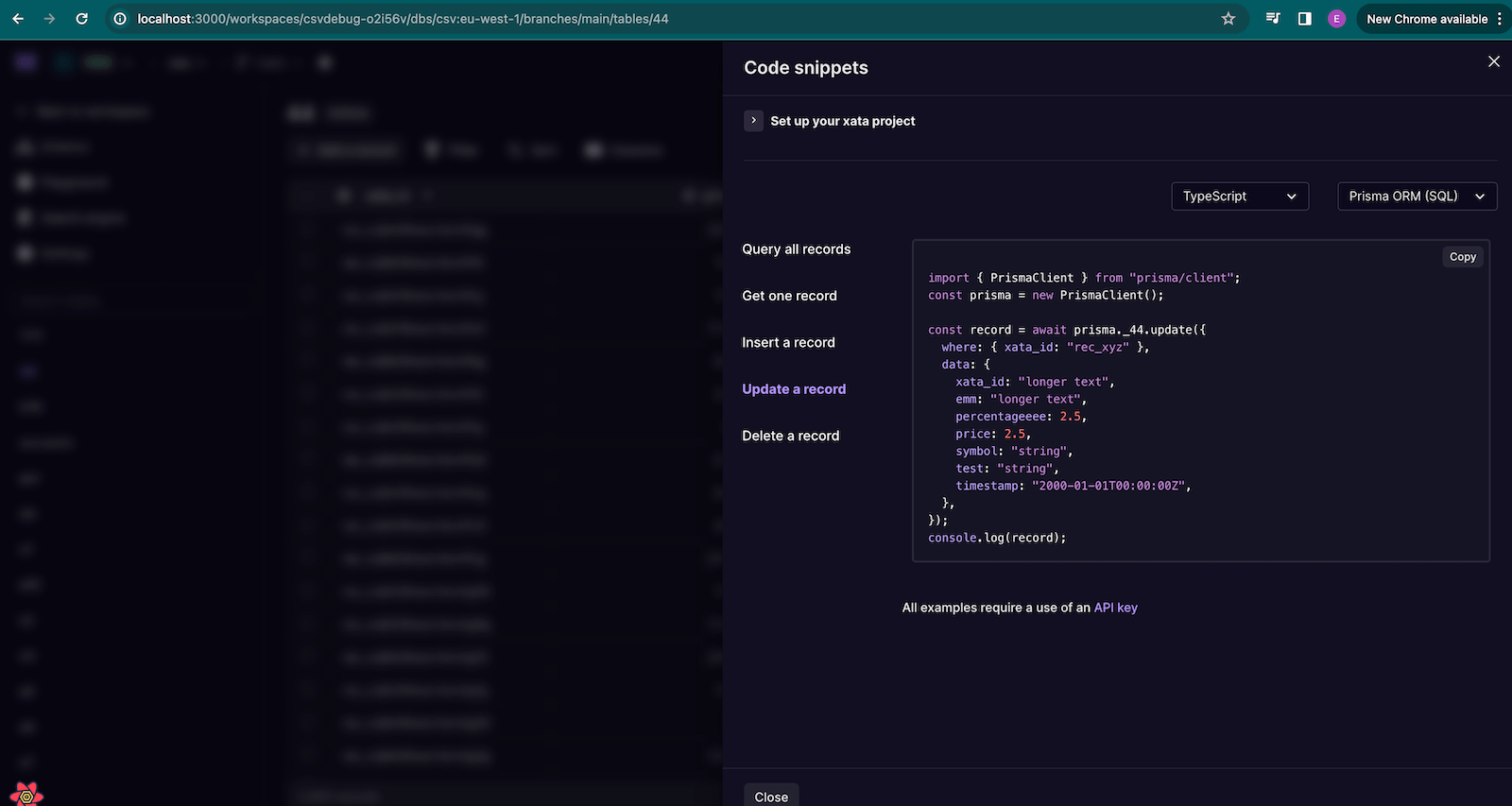
-
Added Prisma ORM sample code snippets to the drawer, automatically matching your project and the current view in the table.
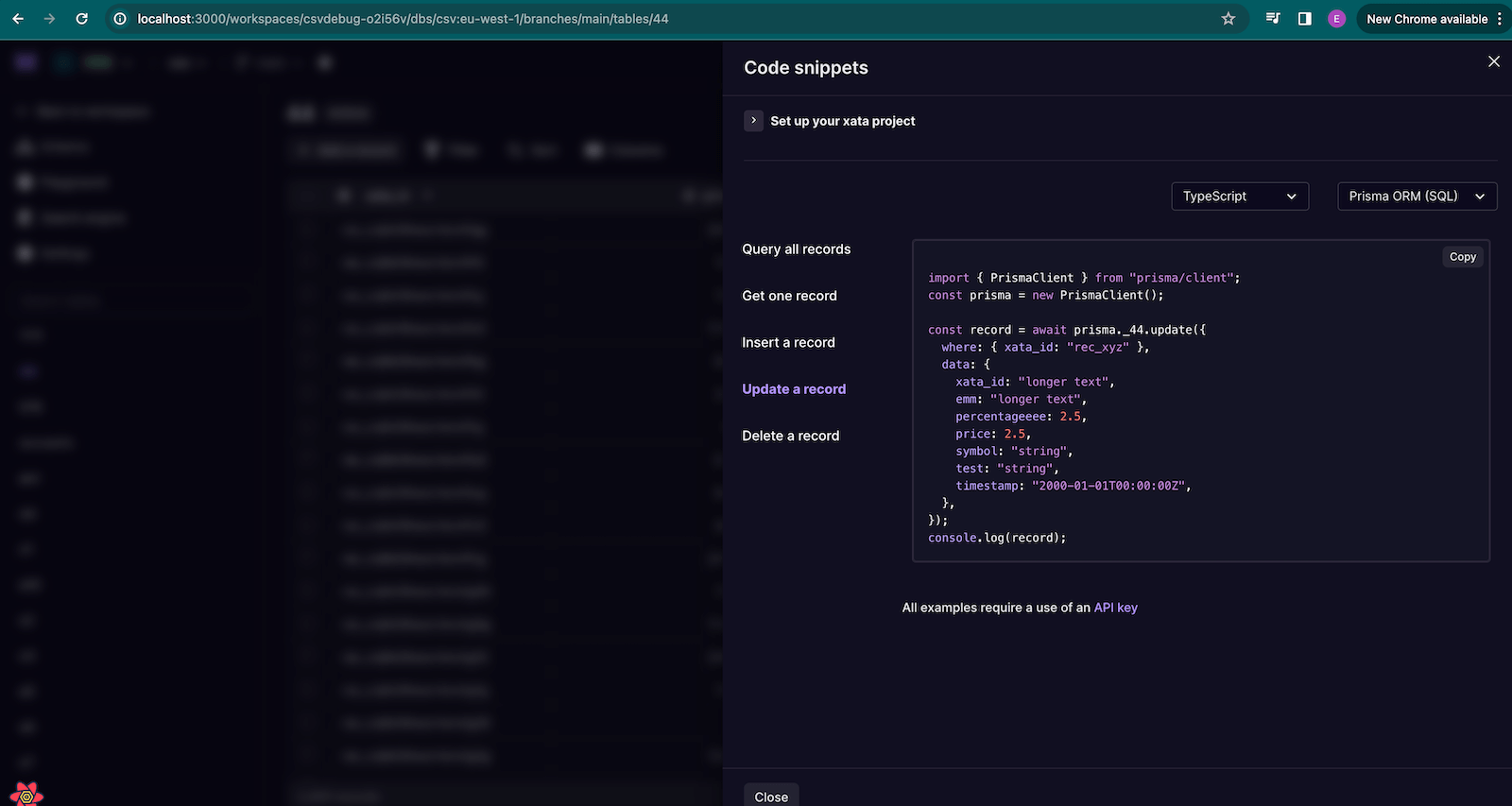
Prisma code snippets -
SQL-compatibility improvements over the wire protocol:
- Allowed more SQL functions to be executed over the wire protocol, including
get_random_uuid,pg_try_advisory_lock,pg_describe_object, andpg_stat_get_numscans. - Added support for
CREATE SEQUENCEand sequence functions. - Added support for creating views.
- Added support for
INSERT FROM SELECTstatements. - Added support for
CREATE TYPE. - Better support for identity columns.
- Allowed more SQL functions to be executed over the wire protocol, including
-
UI: Left side nav is now sticky on long pages.
-
UI: Improvements for the mobile navigation.
-
Usage monitoring: Fix storage metric collection for columns of type File that were using mixed case.
-
Dedicated clusters Early Access Program: various fixes.
-
Website: Added the ability to filter blog posts by authors and tags. For example see this filtered query.
Here is what we announced each day:
- Day 1: Xata as a serverless Postgres platform, currently in beta. You can now connect over the Postgres wire protocol and use Prisma, Drizzle, Django, Rails or anything else that supports Postgres.
- Day 2: pgroll is now integrated into Xata, opening the door for painless, zero-downtime, reversible schema migrations
- Day 3: Usage monitoring. Get analytics for your database. Also updates to our Prisma and Drizzle integrations.
- Day 4: pgzx, open source project for building Postgres extensions with Zig.
- Day 5: Dedicated clusters, currently in private alpha, they offer better isolation, security, and cost efficiency at scale.
- Day 6: Xata website refresh. We've updated our website to reflect the new features and offerings.
You can find links to all of the announcement blog posts on the Launch week page.
-
We have added a way to disable search on your database. This is a good way to reduce cost if you aren't using any of the search functionality (search, aggregation, vector search). By disabling search, you won't be paying for Elasticsearch storage. You can find the toggle in the database settings. Don't worry though, search is still included in the free tier and enabled by default.
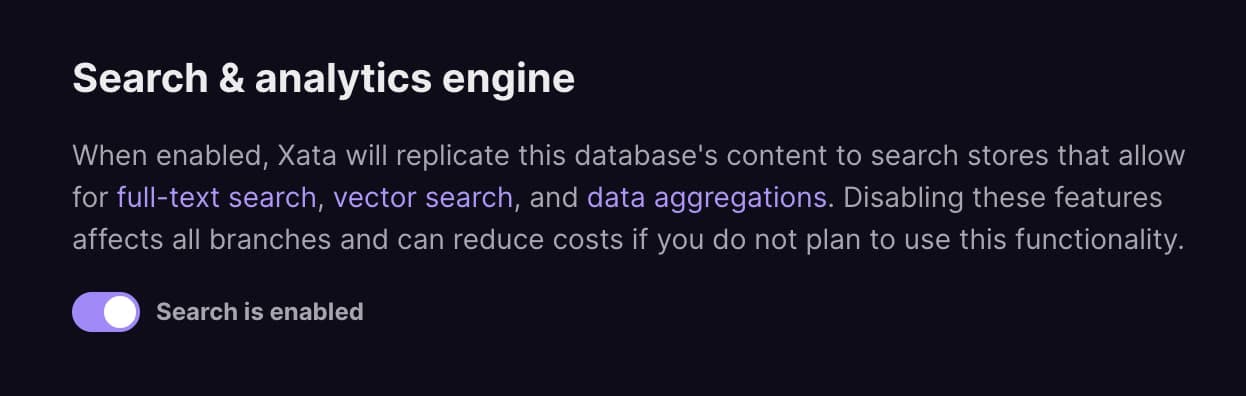
Search toggle in database settings -
The schema edit view within the UI received a visual upgrade. It should be easier to view the requirements for each column at a glance.
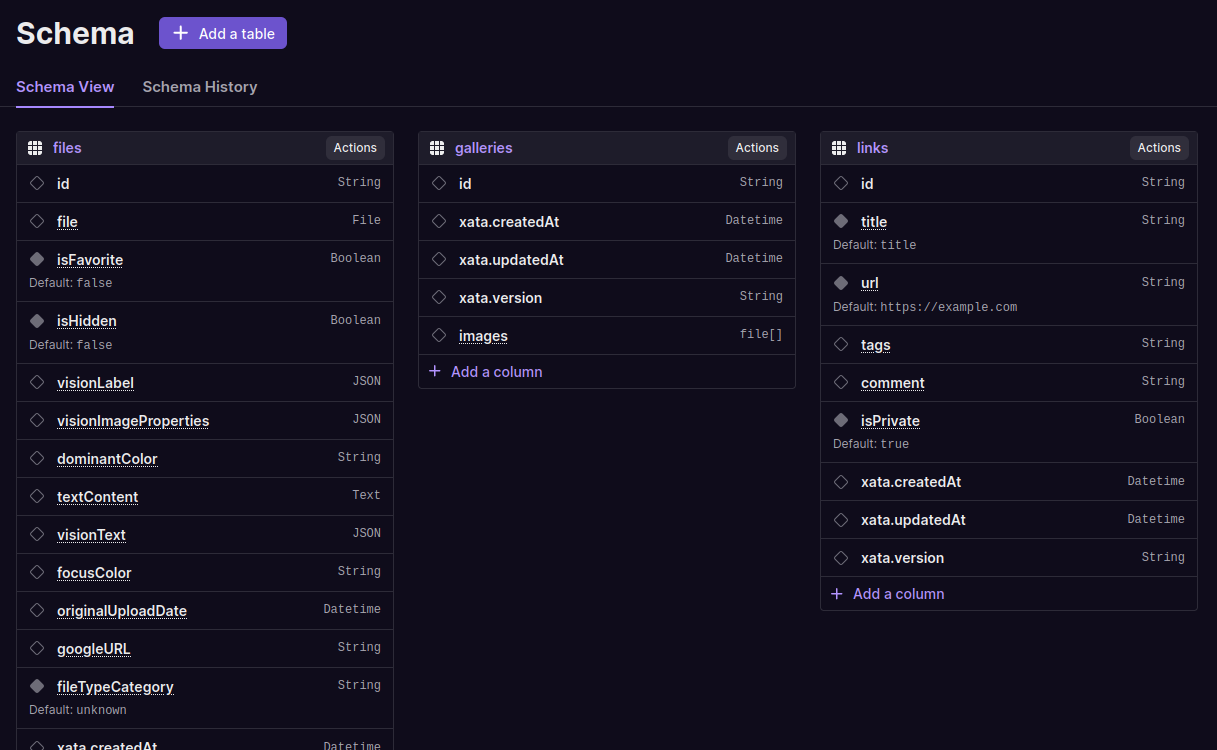
- In preparation for our upcoming releases, we have re-structured our docs to make it easier to find what you're looking for. Please let us know if you have any feedback! Also quick reminder: the search bar in the docs works really well (because it's based on Xata).
- We've added
betaandalphatags to features that are not yet generally available. At a high level you can think ofalphaas "only available to a select group of users" andbetaas "available to all users, but not yet stable". - Updated the error messages when trying to use the SDK directly from the browser to point to a particular docs URL.
- Building a Retrieval-Augmented Generation Chatbot with SvelteKit and Xata Vector Search by Rishi Raj Jain - This tutorial shows you how to build a RAG Chatbot using Xata, SvelteKit, LiteLLM, TailwindCSS and Vercel.
-
Video and audio files previews in the UI: If you use file attachments and attach video or audio files, you now get a nice player in the UI to preview the file.
Preview video player -
Initiate filters from the column headers! This is a small change, but it's a really nice shortcut.
-
Another quality of life improvement: when adding a new record, the default values are now pre-filled in the form. This should save you a few clicks and make the process smoother.
- File attachment URLs are now returned automatically in the search results. While previously you had to query the transaction store (/query), you can now get the file attachment URLs directly from the search results. This will save some round-trips.
- Improved the table search code snippets in all languages for which we have SDKs.
- When uploading a file, the upload response now contains all the object fields, with the exception of the actual file content.
- Fixed a bug where CSV download was occasionally failing.
- Fixed a bug where in the link selection dialog the column selector was not a drop-down.
- Create your own content management system with Remix and Xata by Rishi Raj Jain - This tutorial shows you how to build a content management system with Remix and Xata.
- Educating new frontend developers with Xata - A community spotlight putting the spotlight on Teri Eyenike, a software engineer out of Lagos, Nigeria empowering the next generation of developers to build.
-
We improved the website search experience, which itself uses Xata's full-text search features. Search results now additionally match against headers within documents, which should make functions and other deeper content easier to find. Please let us know if you have any feedback or if particular search terms don't seem to work as expected.
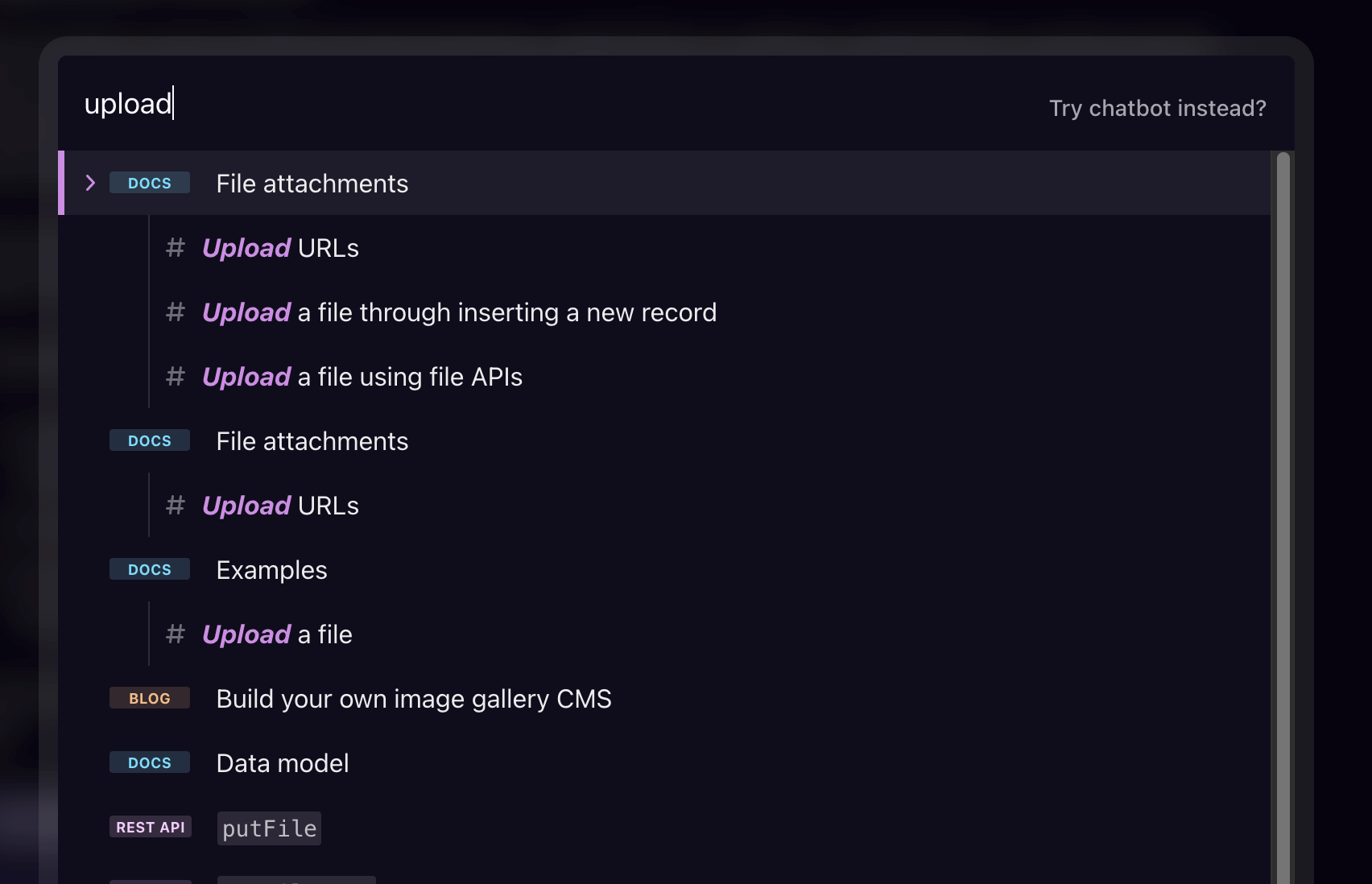
Improved docs search -
Speaking of search, we have also improved the docs for our search functionality: https://xata.io/docs/sdk/search
-
Improved CSV import error reporting in the UI by showing tooltips above the column names that have errors.
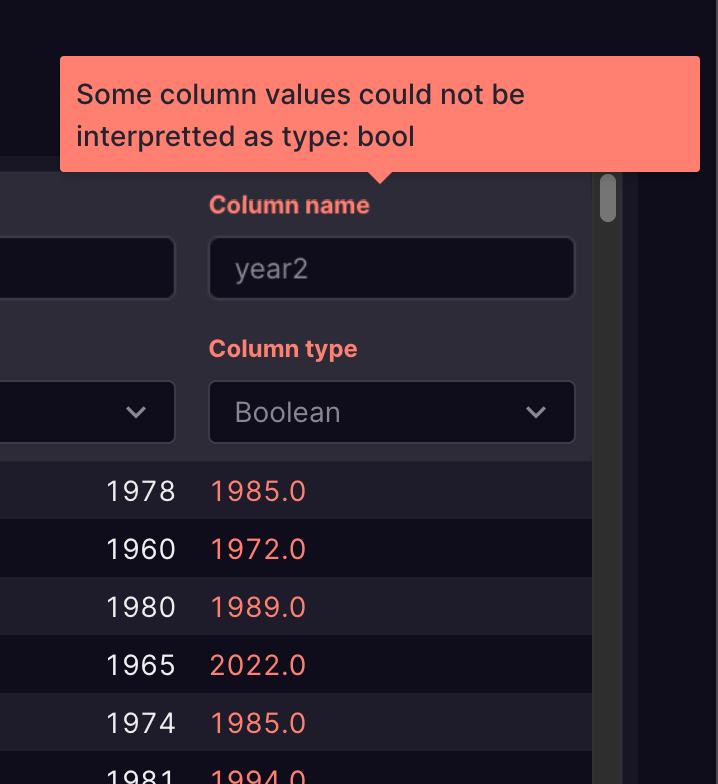
CSV error tooltips -
Small fix to the focus state of the Github connect button on the database cards. Previously the opacity wasn't being switched.
-
Fixed default TTL for the signed URLs created for file attachments when updated via partial update.
-
Fixed some broken links in the OpenAPI spec documentation.
-
For another public website improvement, you can now subscribe to RSS feeds for particular categories of our blog.
-
A new example for uploading files using Next.js was added to our examples repository.
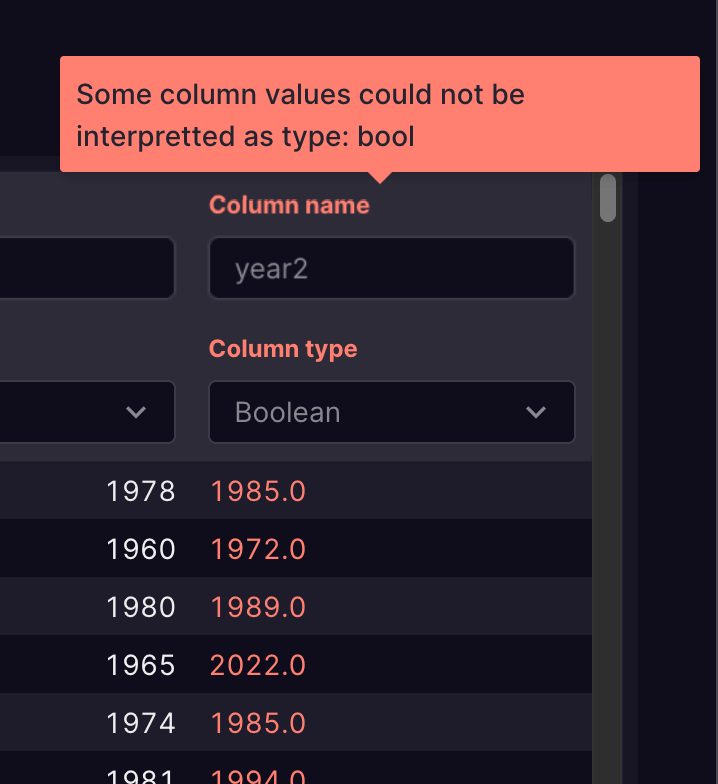
- How to perform Postgres schema changes in production with zero downtime - This contains a recording and summary of the workshop we did about schema changes in Postgres with zero downtime. If you missed the workshop, you can still watch the recording!
- Announcing the winners of the Holiday Hackathon - Congrats to all winners! 🎉🎉🎉
-
File uploads from the browser! This was a highly requested feature for file attachments. The way it works is that you can create a new record without passing the file, you get back an
uploadUrlthat is safe to pass to the browser, then you upload the file to that URL. For more details, see the documentation for Upload URLs. This example demonstrate doing files uploads directly from the browser, in a sample Next.js application. -
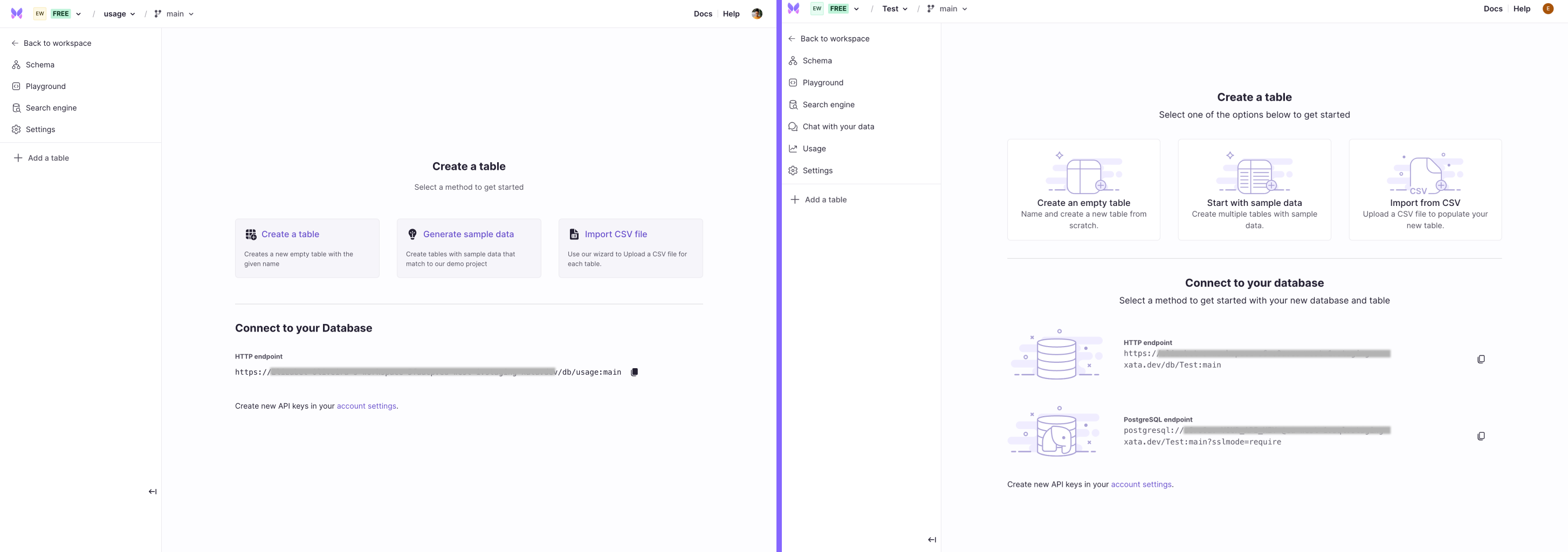
We've shipped a new onboarding workflow for creating and connecting to databases. The new workflow asks a few questions and then displays instructions that fit with your particular case.

Xata onboarding workflow -
Cloudflare launched a database integration for Xata. Please see the docs here, and there's also a demo on Cloudflare TV.
-
Lots of tables? You're going to enjoy this quality of life improvement where you get a search box on top of the list of tables.

- The branch selector in the UI now accepts hundreds or thousands of branches, for our dear heavy-branch users.
- The workspace invite emails got a facelift with our updated branding.
- Made it possible to query Xata metadata columns when using the Drizzle integration.
- Fixes for using transaction via the TypeScript SDK.
- Added a “Back to Workspace” button when you are on Account settings. Makes it easier to well, get back to the workspace.
- Fixed indexing in the search engine for the JSON type values.
- Fixed replication errors in some corner cases.
- Fixed the support for some SQL queries that are using sub-queries.
- Fixed a couple of typos in the OpenAPI spec, because attention to details matters.
- The first Xata workshop: Learn how to perform Postgres schema changes in production with zero downtime. It's this Wednesday, register for free to get the recording.
- Xata-Cloudflare integration: Connect your Cloudflare Worker with Xata in one click
- The Club Xata experience - connecting, collaborating, creating
- Tutorial: Build your own image gallery CMS
- Community spotlight: Automating the creation of Shopify stores with Xata
- Community spotlight: Reducing search response time by 99.98% with Xata
Discover the latest enhancements and feature updates at Xata:
- Release of Go SDK: We've released our official Go SDK, adding to our existing Python and TypeScript offerings. This new Go SDK provides improved performance and better concurrency support, ideal for Go developers. For more information, refer to our docs.
- Improved UI in schema editor: Implemented title truncation in the schema editor to prevent table overflow, enhancing the overall user interface and readability.
- Workspace deletion update: You can now delete workspaces even if they have active subscriptions, providing enhanced control over workspace management. Additionally, the confirmation modal has been updated to inform you about any active subscriptions associated with a workspace before its deletion.
- Participate in the Xata Holiday Hackathon: Showcase your app development skills using Xata. Build an app on top of Xata, and submit your project by January 15, 2024, for an opportunity to win prizes. To learn more, check out our Holiday Hackathon blog post.
Take a look at the recent progress in our pgroll project:
- [FIX] Improved table name handling: Resolved a bug where incorrect table name quoting in the
OpSetReplicaIdentityoperation led to issues with tables having case-sensitive names. PR #206 - [FIX] Enhanced release process: This community contribution, pushes the Docker image to
ghcr.iowith packaged results accessible at https://github.com/users/xiaoyao9184/packages/container/package/pgroll. PR #209 - [NEW] Automated Go type generation: Added a Makefile target to automate Go types generation from JSON schema using
omissis/go-jsonschema. PR #210
Explore Xata's recent blog posts to stay informed. Subscribe to the blog to get the latest content delivered to your inbox. Here are some of our recently published posts:
Discover the latest enhancements and feature updates at Xata:
- Redesigned navigation: We've made significant improvements to the navigation system in Xata. The navigation now follows a linear breadcrumb flow, providing a more intuitive and user-friendly experience. The overall interface presentation, including improved sorting capabilities, further refines data organization within Xata.
- Improved error handling: We’ve introduced advanced SQL context parsing and made significant improvements to autocompletion for SQL keywords, table names, and column names. This provides a more refined SQL query development experience, allowing users to work with complex queries.
- JSON
bigintparsing issued fixed: Addressed and resolved parsing errors encountered with invalid bigints in JSON handling. - Fix for CLI installation issue: Corrected a module loading error encountered during the installation of the Xata CLI. The error was related to the inability to find the
tslibpackage, which occurred with version 0.14.3 on Node v20.9.0. The issue is now fixed. PR #1245
Take a look at the recent progress in our pgroll project:
- [NEW] Added set replica identity operation type: Introduced a new operation type for setting replica identity. This feature allows setting the replica identity of tables, like fruits, to FULL, index, default, or nothing. For index type, specify the index name. The replica identity applies to both new and old versions of the table upon operation start. PR #201 To ensure new tables in pgroll-enabled branches have
REPLICA IDENTITY FULL, a second migration now automatically runs right after thecreate tablemigration. This is necessary because Postgres doesn't allow setting the replica identity during table creation. - [NEW] Brew update: As pgroll has been updated to version v0.4.0, Homebrew users can now get the latest features and improvements for Postgres zero-downtime migrations. To get the latest version, run
brew install pgrollor update an existing installation withbrew upgrade pgroll. - [FIX] Fixed primary key function: The revised SQL query enhances performance in cluster environments with a large number of schema objects. This change leads to faster and more efficient data retrieval in complex databases. PR #198
- [FIX] Connection establishment enhancement: Improved the error messaging for database connections by introducing a ping to the database right after connection establishment. This update ensures error messages are more straightforward and specific to the connection issue, eliminating the previously seen unrelated prefixes in error descriptions. PR #195
- [FIX] Default value update for column additions: Default value auto-quoting for new columns has been removed to fix issues with time-based defaults like
now(). Users now need to manually quote necessary default values. PR #200
Explore Xata's recent blog posts to stay informed. Subscribe to the blog to get the latest content delivered to your inbox. Here are some of our recently published posts:
Discover the latest enhancements and feature updates at Xata:
- Added blog navigation by tags: We've introduced a new feature that simplifies blog exploration. Now, you can easily discover blog posts by appending tags such as "postgres," "engineering," "product," "community," and more to the end of the blog tags URL (
https://xata.io/blog/tags). This enables you to find and browse blog posts relevant to your specific areas of interest. For example, you can access all Xata blog posts related to PostgreSQL using the following URL:https://xata.io/blog/tags/postgres, or filter by two tags using a URL like this:https://xata.io/blog/tags/community,announcements. In addition, tags will soon be accessible directly through the UI for even easier navigation. - Enhanced CSV file import support: This update introduces the capability to import both remote and local files from a CSV. Only the file's path, URL, or base64 encoding is required. While this feature is currently available in the CLI, we plan to support it in the Xata app soon.
- Enhanced search responses: Closing a common feature request, the TypeScript SDK
v0.27.0introduces thetotalCountfield in search responses (includingsearch,search.byTable,search.all, andvectorSearch) to report the total number of matching records. This is considered a minor breaking change as the response format is now an object, not an array. Adding the total hits to every search response makes it easier for the client to decide whether to fetch another page of results. ts-client#1232 - Improved Python syntax and error messages: The playground now offers better syntax highlighting and a more intuitive display of errors for Python code.
- Migration to monorepo: Our website, application, and documentation have successfully migrated to a monorepo structure. This means that related Xata projects, components, and resources are now stored in a single repository for improved code management and collaboration. This update lays the foundation for a more personalized and immersive user experience across the different entities.
- Python code snippets and improved connector information: We’ve added Python code snippets within the playground. Users can now easily integrate and experiment with Python for an improved development experience. Additionally, we've enhanced the connector info for Drizzle and Kysely snippets across local repositories, covering all data types for a better user experience.
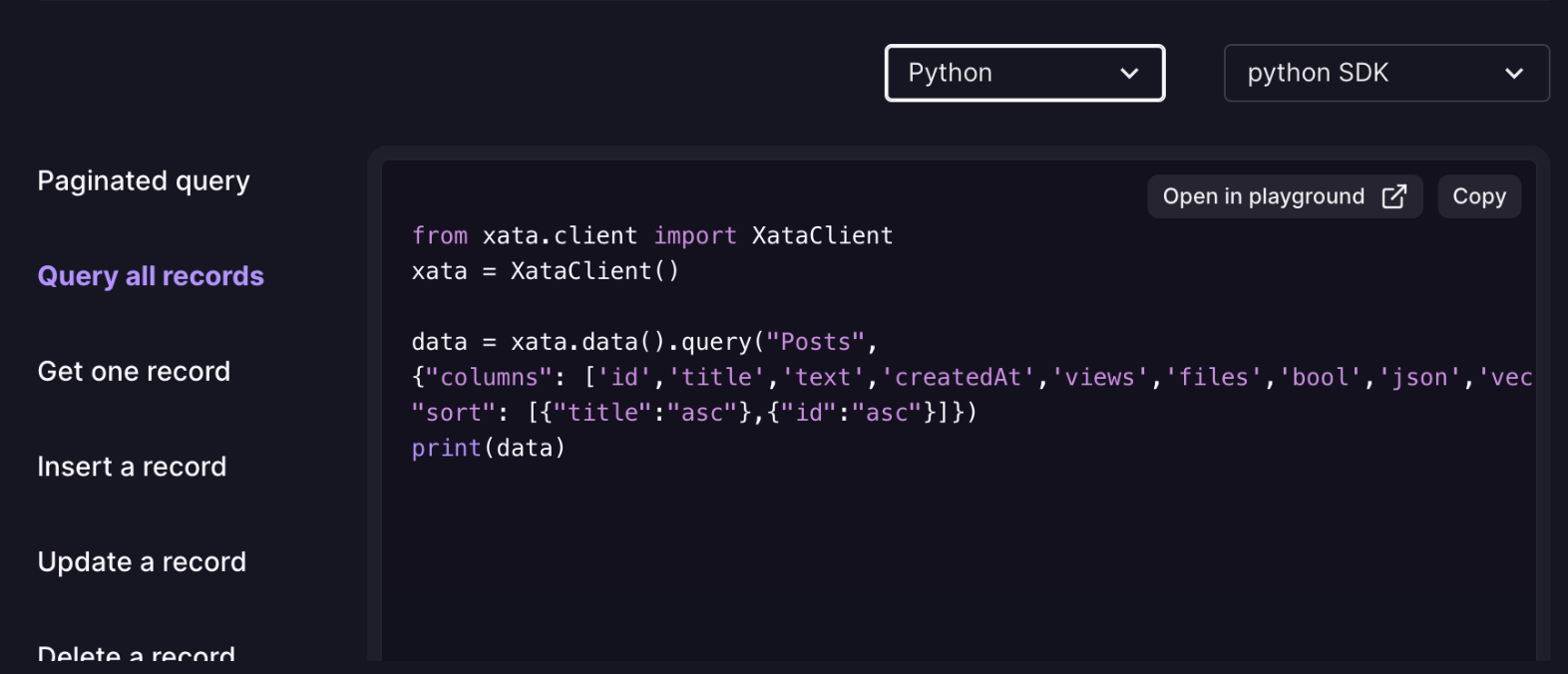
Python code snippet - Support for importing vector columns: With this enhancement, you can now import vector columns through the in-app CSV import wizard.
Take a look at the recent progress in our pgroll project:
- [NEW] Security definer added: With the addition of the
SECURITY DEFINERattribute, the security model of the pgroll schema allows admins to restrict access while ensuring uninterrupted functionality pgroll#191. Thank you @jankatins for your contribution. - [FIX] Fixed
previous_versionfunction: Resolved an issue where theprevious_versionfunction did not correctly remove the previous version schema upon completing migrations applied in schemas other than public and enhanced testing to ensure that the--schema flagis properly respected pgroll#190
Explore Xata's recent blog posts to stay informed. Subscribe to the blog to get the latest content delivered to your inbox. Here is our most recently published blog post:
Discover the latest enhancements and feature updates at Xata:
- Added support for top values aggregations - This update introduces support for top values aggregations on fields with data types of
int,float, andbool. Previously, only fields with the data typestringwere supported for this aggregation method. This enhancement expands the applicable field types to includeKeyword,Numeric,ip,boolean, orbinary. - Improved SQL autocompletion feature - We’ve introduced advanced SQL context parsing and made significant improvements to autocompletion for SQL keywords, table names, and column names. This provides a more refined SQL query development experience, allowing users to work with complex queries.
- URL retrieval for file transformations - Introducing a new Python helper function contributed by the community. This function focuses on optimizing the retrieval of URLs for file transformations xata-py 178.
Explore Xata's recent blog posts to stay informed. Subscribe to the blog to get the latest content delivered to your inbox. Here is our most recently published blog post:
Discover the latest enhancements and feature updates at Xata:
- Case insensitive matching is now available: Users can now benefit from case-insensitive matching. This functionality is perfect for those dealing with mixed-case data entries or aiming for a broader text search result regardless of character case. Learn more about this feature in our SDK filtering docs.
- Enhanced security with OAuth 2.0 support: We're excited to announce that we've expanded and improved our OAuth 2.0 support, the industry-standard protocol for authorization. This enhancement aims to offer more flexibility and security to our users while integrating third-party applications - you can expect more straightforward implementations, and enjoy more robust security measures. See our integration docs for more information.
- Enriched SQL proxy logs: SQL proxy logs have been improved to offer enhanced clarity. The
stmt_typenow signifies the distinct SQL operation, such as select, insert, update, or delete. Therecord_countcaptures the number of processed and returned rows, while in insert and update actions,res_target_countenumerates the total values used. - Increased pagination capacity: To better accommodate users' data retrieval needs, we've enhanced to the pagination feature. Originally set to handle 10,000 records, the platform's pagination limit has now been expanded to support up to 50,000 records. See our docs for more information.
- Introducing the beta version of
pgroll:pgrollis a dedicated open-source command-line tool tailored for streamlined schema migrations on Postgres databases. Designed to minimize downtime and offer instant rollbacks, it's now available for experimentation and feedback in our GitHub repository. Check out our recent blog post to learn more.
pg-roll virtual schema - Improved transactions helper in the Python SDK: - In response to valuable user feedback, we've implemented changes in the transaction helper. Now, it will smoothly back off and retry on rate-limiting errors, without evicting all operations on errors. Additionally, we've added the capability to specify the target branch in the execution call. See xata-py#173 in the repo for more information.
- New version of the TypeScript SDK available: We have released an updated version of the TypeScript SDK. This release brings improvements and optimizations to better cater to the needs of TypeScript developers using our platform.
- New Xata pricing structure - We are introducing a new pricing structure. We've implemented a usage-based billing system, ensuring you only pay for what you use. Start with Xata at no cost and scale your payments only as you grow. See our pricing page for more information.
- Percentiles aggregation added: Similar to Elasticsearch, we have implemented a percentiles aggregation feature. This update includes schema modifications for average and percentiles aggregations, as well as adjustments to the handling of values, ensuring compatibility with both string and number types. See our docs for more information.
- Support for conflict support in
INSERTStatements : To offer better conflict management in data operations, we've enhanced the SQL proxy. Users can now leverage theON CONFLICTclauses when usingINSERTstatements. This means when attempting to insert data that might cause a conflict, like a duplicate key, you now have more control over the response - you can ignore the conflict or update the conflicting record. - Updated Zapier Integration: The latest version of our Zapier integration, v1.0.1, now provides support for JSON columns. This enhancement facilitates more versatile data handling and interaction for users leveraging JSON structured data within their Zaps.

Explore Xata's recent blog posts to stay informed. Subscribe to the blog to get the latest content delivered to your inbox. Here are some of our recently published posts:
Discover the latest enhancements and feature updates at Xata:
-
Xata Playground now supports Python: Python has been added to our web-based IDE, Xata Playground. Alongside TypeScript and SQL, you can now use Python to explore Xata's SDKs, rapidly test ideas, and easily transition back to your main IDE for full-scale development.
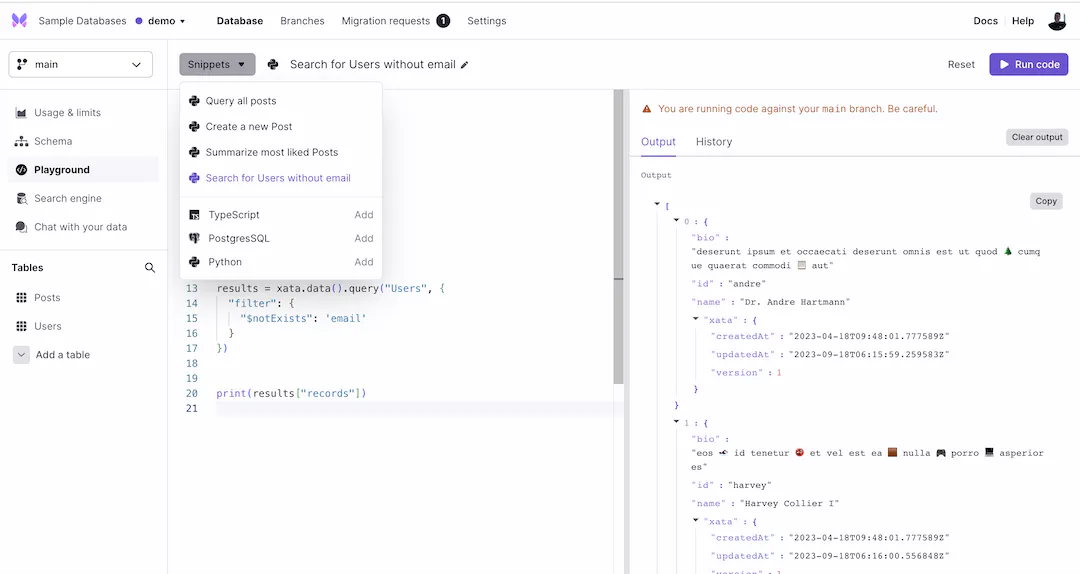
Python support for Xata Playground -
New gallery app example available: We've introduced a gallery app example built with Next.js and Chakra UI to demonstrate the File Attachments functionality as well as key Xata features such as pagination, form handling, search functionality, image transformation, and so much more. Check out our docs to learn more.
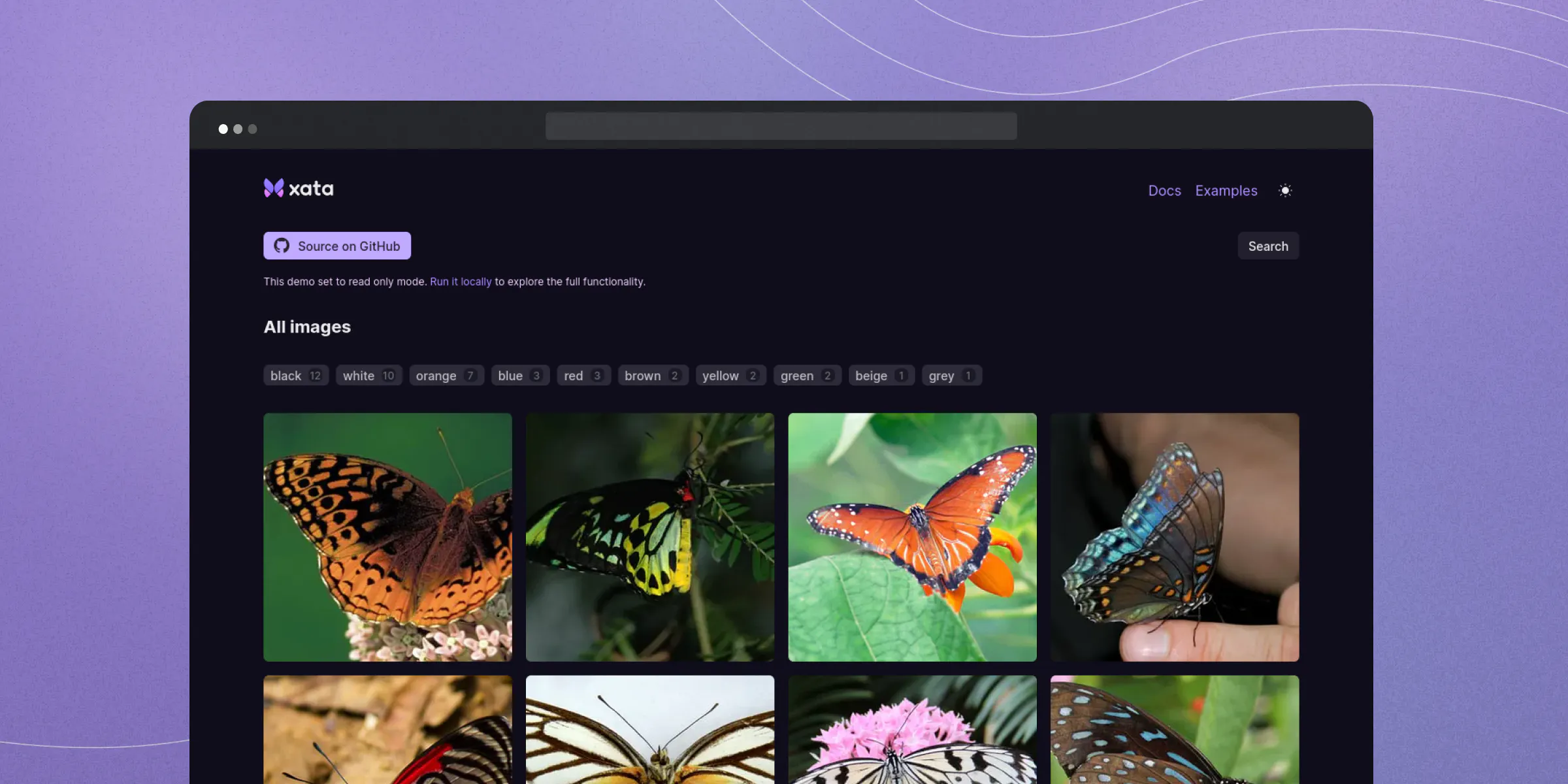
Gallery app example -
Design improvements: Visual layout and elements are now more consistent across all Xata pages, leading to improved accessibility and ease of navigation. These changes are all aimed at making experiences on the Xata platform as smooth as possible.
-
Updates to
vectorSearch: The component has been updated for an improved user experience. It now returns full metadata, offering a more detailed view of your search results. This update was made in response to a request in our discord community.
Explore Xata's recent blog posts to stay informed. Subscribe to the blog to get the latest content delivered to your inbox. Here are some of our recently published posts:
Discover the latest enhancements and feature updates at Xata:
- A new look for Xata.io - We've given Xata.io a fresh new look, making it even more user-friendly. This redesign includes several improvements, such as clearer messaging and a streamlined workflow, all aimed at providing an improved experience for our users.
- File Attachments are now available - We have embedded file attachments directly into our serverless database and improved the experience for building data apps that require binary storage.
- New UI experience for CSV import and export - Introducing an entirely new CSV import and export interface that simplifies your Xata.io experience, enabling you to automatically create new tables by directly importing your data into Xata's database. The export feature allows you to download your data as CSV files.
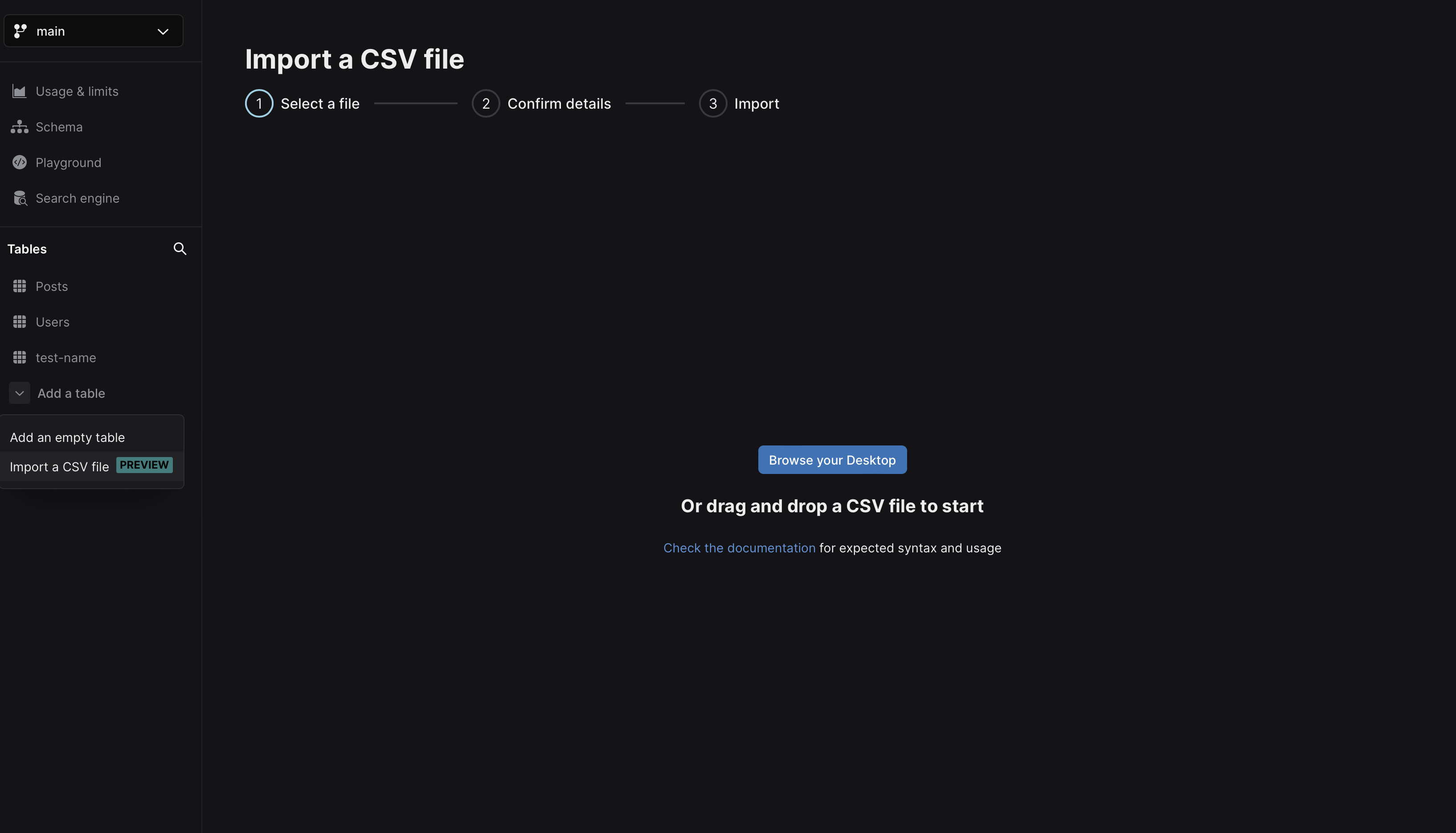
- Support for JSON ingestion - Basic support for JSON column types is now available, expanding the range of data formats that Xata.io can handle.
- Improved data traversal with reverse links - We now provide column expressions in the query endpoint for more precise projection definitions with JSON objects. The new Xata querying syntax makes it possible to traverse the N:1 relationships backwards and solves the N + 1 problem.
- The Xata Python SDK is in GA - Our Python SDK is now in general availability. We're excited to release version 1.0.0 of our Python SDK, offering a more stable and feature-rich experience for developers.
- Direct SQL access - We've introduced support for SQL (Postgres dialect) over HTTP, with a focus on safety.
- To ensure secure SQL access to Xata databases, we've developed a dedicated SQL proxy. The proxy works alongside the Xata data API, enhancing security between Postgres, routing, and authentication components.
- We have plans to further expand SQL support and introduce the Postgres Wire protocol for maximum compatibility.
- New integrations - Xata now offers integrations with LangChain, the ORM Drizzle, and the TypeScript builder Kysley, expanding the range of tools and possibilities for developers.
- Xata's new framework guides - Our getting started guides for the frameworks Astro, Next.js, Nuxt, Remix, SolidStart, and SvelteKit have undergone a significant overhaul. These getting started guides provide a more user-friendly introduction to Xata. Explore the guides to learn how to use the Xata CLI, create databases, define schemas, import CSV data, and make the most of querying, filtering, and full-text fuzzy search capabilities.
Explore Xata's recent blog posts to stay informed. Subscribe to the blog to get the latest content delivered to your inbox. Here are some of our recently published posts:
- Xata Launch Week
- Bring (and take) your own data with CSV import and export
- LangChain integrations
- Announcing General Availability of the Python SDK
- File Attachments: Databases can now store files and images
- SQL over HTTP and ORM integrations
- New getting started guides: Astro, Next.js, Nuxt, Remix, SolidStart, and SvelteKit
- Reduce query round trips with improved one-to-many relations
- Introducing the JSON column type
- Xatabyte: Basics of database indexing
- Designing your database schema
- CSV Import CLI improvements: CSV Import via the CLI is now ~2.5x faster and infers column types better. We're also updating our CSV import UI - watch this space for updates.
- As announced in the previous edition of the Changelog, the search API now returns the total number of hits. The TypeScript SDK now supports retrieving this total count and it is also displayed in the Xata UI.
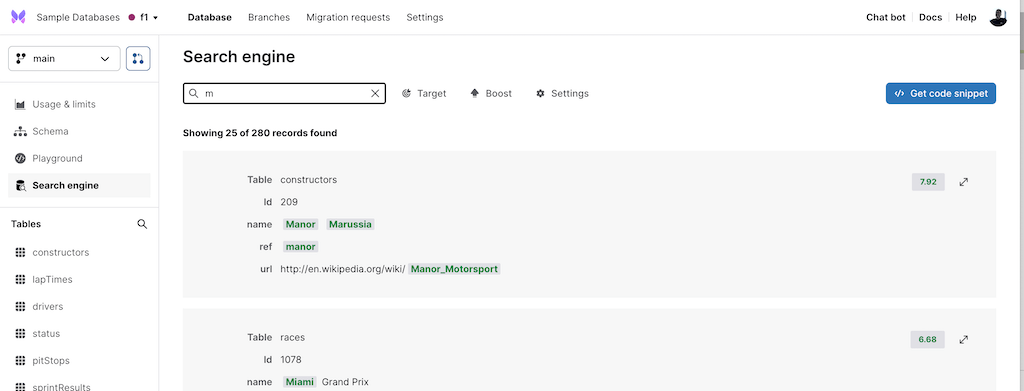
- The TypeScript SDK now supports sessions for the Ask endpoint. This means it's now possible to ask follow-up questions when using ChatGPT to get answers from your database.
- Usability improvement: When adding a new table or a new column, invalid characters are blocked at the input level, saving you time.
- Fixed horizontal scrolling and improved the word warping in the Playground.
- Fixed showing of leading zeros in numeric cells in the table.
- Our docs just got a major face lift, matching the rest of our branding. Other improvements include:
- The documentation content is now public on GitHub and open for community edits.
- Website search was rebuilt and will now output results from the blog alongside documentation.
- Grammar and syntax highlighting in code snippets are improved.
- We’ve officially published the first preview versions of the
1.xversion of our Python SDK: https://pypi.org/project/xata/1.0.0a3/ - The early access program for image transformations and file storage has officially kicked off. Come join our Discord channel and hop into #eap-files if you’d like to join in on the fun.
- Community contribution from cartogram to fix some typos in
xata init - The search API now includes the total hits returned in the search response (canny request). This is only available in the REST API at the moment and SDK support will be coming soon.
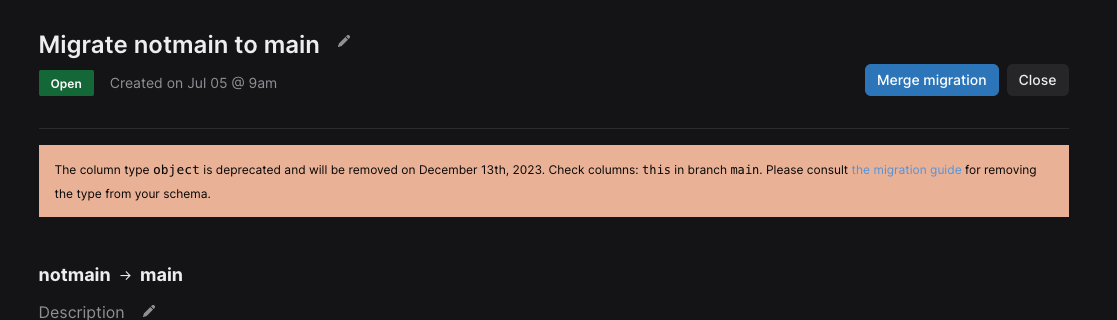
- The
askendpoint that enables you to easily build ChatGPT experiences on your data is now conversational. With the latest update, you can now ask follow up questions to your data. - When deleting a workspace, delete based on the name of the workspace instead of the workspace ID.
- Display an object deprecation notice where appropriate throughout the Xata app
- Adds the physical close button back in for mobile record / image viewing as a more obvious close option
- Resolved numerous bugs in the table related to linked columns and metadata fields
New blog posts:
- As announced here, we have added two new regions: Sydney 🇦🇺 and Frankfurt 🇩🇪. G'day mate, and respectively, Guten Tag.
- In addition, the UI and the relevant APIs now return the friendly region name (e.g. Frankfurt) beside the AWS region name (eu-central-1).
- The Xata GitHub integration now triggers the branch creation as soon as a commit is pushed to a new branch, while before it was waiting for the Pull Request to be open. What this means, in practice, is that the Xata branch is created before the Vercel build in almost all cases, which means you are no longer getting a red Vercel build on the first try. 🟢
- When adding a column, a nice flashing effect shows where your new column has landed:
- For another quality of life improvement, added type-ahead search for selecting columns for filtering and sorting.
- Similarly, when you need to select a table to create a link relation, you can now type to quickly find the table you need. No more scrolling thrown tens of tables.
- The TypeScript SDK and Python SDK emit server messages to the logs. For example if you are invoking the get columns of a table API, a message about the object deprecation will be added to the client logs. This creates a communication channel to provide meta information to the client side.
- As part of our object type deprecation plan, which we announced in the last Changelog edition, we are now showing warnings in the UI when a new object type is being created.
- Fixed UI issue with the multiple column type editing.
- Fixed out of range error messages (e.g. int value that is larger than max int).
New Blog posts:
- Important: we are planning to deprecate the
objecttype. We have published a plan for it and we have updated the docs with the available alternatives. A warning will show up in the UI as well if you try to add a column with dots. It is best to avoid this type from now on. - Improved the bulk inserts API to returned all the failed records, not only the first one. This enables significantly more efficient data loading operations in the presence of errors.
- Metadata columns
createdAt,updatedAt, andversionare now exposed in the UI, and usable in filters and sort conditions across the app. mew tables get these columns by default:

- Added
createdAtandupdatedAtfields to the search API responses metadata. - Removed plural versions of the CLI commands (e.g. “workspaces”, “branches”). The singular version of them has been recommended for a while now, and it's time to remove the deprecated commands.
- Made access to the read replicas publicly available for the /query and /summarize endpoints. Change the consistency level to eventual to leverage this functionality.
- It is now possible to explicitly address the ID column of a linked record in filters. This was already possible by using the table name, this adds the option of addressing as
table.id. - Fixed deleting records that have
:in their ID columns. - Fixed UI issue where the Filter menu item was not hidden when clicking outside of it.
- Fixed the reloading of the
updatedAtandversioncolumns where other columns where edited. - Fixed boolean and datetime column widths in the UI.
- Removed the “reset filters” message on empty table when only sort conditions are set, because removing the sort condition won’t reveal more rows.
- Fix: it is no longer possible to delete databases that have billing units attached. You need to first downgrade them, and then delete them.
- Improved error message for using
$includesin the search APIs (it is not supported). - Improve the
xata pusherror message if the target branch is ahead of the migration list. - Fixed failed migrations leaving the database branch in a state where new migrations were blocked until manual intervention.
- Accessibility improvement: Fixed area-label on button menu in database header
- Fixed “Learn more” link in the code snippet for the CLI.
- Tons of quality-of-life improvements to the
xata initCLI command, improving the flow of setup questions, default values, clarifying the wording, and fixes. Make sure you upgrade soonnpm install -g @xata.io/cli@latest.

- Also added better support for
pnpmandyarn - Added a new
xata dbs renamecommand to the CLI. - Modified the
xata dbs deleteCLI command to allow for the interactive selection. - The
createdAtandupdatedAtcolumns are now available for filtering in the search endpoints as well. - Several improvements to the internal retrying logic which resulted in temporary errors during scaling events.
- Fix for adding object columns via update branch schema API.
- Fix replication issue of large vector columns when another column is updated.
- Fix unit selector on the search date boosters.
- Fixed the link of the new gear icon in settings.
New Blog posts:
New Videos:
- Added
createdAtandupdatedAtmeta-columns. From now on, you always know when something was created and last updated. You get them with the record metadata, as simple as that. This was a common feature request that makes developers life easier, which is our favorite type of feature to implement: https://feedback.xata.io/feature-requests/p/implement-createdat-updatedat-fields. It is now also possible to filter by these meta-columns. - Database renames! It sounds simple, but while it was possible to rename almost anything in Xata, database names were forever. Now you can finally fix that typo from the first day of your project. Be aware that this impacts the URLs under which the database is available, so it will be a breaking change to your application.
- Transactions: add
failMissingoption for deletes. If you set this flag to true, and the delete operations affects zero records, the transaction will be failed. - Fix occasional 500 error in the Ask endpoint that happened on particular inputs
- When returning errors about multiple columns, have the columns sorted by name.
- Added a
factoroption to the free-text-search date booster. Thefactormultiplies the boost, allowing you to better control the effect of the date booster. - Better error message on
unique+notNullcolumns. - In the UI, moved database menu functionality to database settings page.
- Bigger scroll target when dragging-and-dropping a column. Makes it easier to move columns around in the table view, especially when having lots of columns.
- For the Vercel integration, redirect to the main page if the user is signed-in already. Fixed a couple more issues around the Vercel integration.
- Handle filter, sort and hidden columns when a column is deleted. This fixes some corner error conditions after a column was deleted.
We have launched the all new Xata Workflow: complete git-like workflow for your database. This includes:
- GitHub app that follows your PRs and creates Xata branches for you,
- Vercel integration, making it much easier to connect your Xata DB with your Vercel project,
- Netlify integration and plugin, connecting your Xata DB with your Netlify proejct
- data copying between branches,
- Storing of migration in the repo and CLI pull and push command for schema changes,
- automatic migrations when you merge the Pull Request.
Other fixes and improvements:
- Improved error messages when parsing invalid JSON. Because we obsess over good error messages.
- Fixed renaming of columns and tables when only casing is changed.
- When accepting workspace invitations, treat email addresses case insensitive. This makes it easier to invite your colleagues.
- Fixed border on table cells, making keyboard navigation in the table much easier.
- Fixed the record count after generating random data from the UI.
- Fixed working with hidden linked columns in the UI.
Blog posts:
- XataForm is here! - New open-source project to deal with your forms, survey and quizzes!
- Modern database workflows with GitHub, Vercel, Netlify and Xata - Announce blog post for the new Xata workflow.
- End-to-end preview deployment workflows with Xata and Vercel - Showing our deep Vercel integration.
- Include the page size in the cursor response metadata. This takes the guessing away and helps troubleshooting.
- Improved previews for cells with a lot of data in them.
- Fixed a small keyboard navigation bug when the columns are reordered and the ID column is no longer the first.
- Improve padding on the cells containing datatime columns to give space for the remove button.
- Community spotlight: Accelerating Time-to-Market for Ecommerce Platform Batchoop
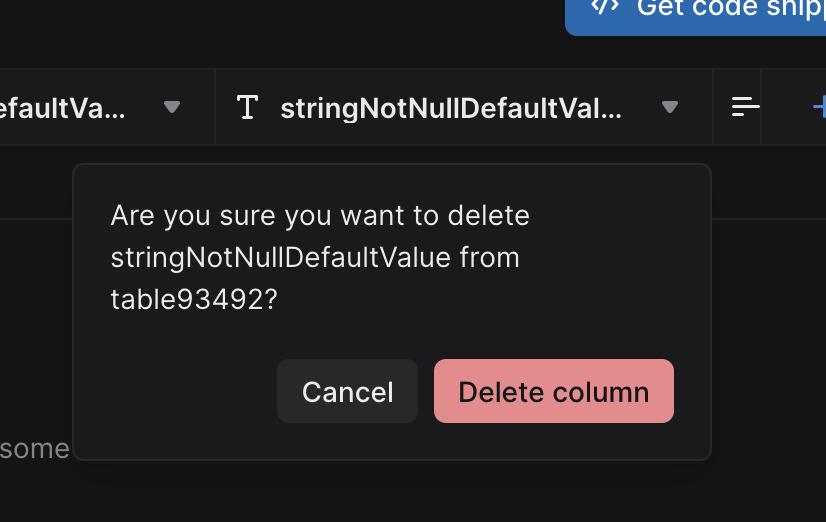
- Improved error message on for null columns without a default value. This is a common source of confusion and, yes, we’re working on fixing better by allowing not null columns without defaults.
- Better confirmation messages when deleting columns or tables. The names of the affected column and table are now included in the confirmation, for example:
- When canceling an editing operation, we now only show a confirmation dialog if there were any changes.
- The column ordering is now used consistently every where we use it: in the edit drawer, in filters/sorting dialogs, in the schema page, etc.
- Fixed the generated code in the Get Code Snippet that was sometimes producing dates with an invalid format.
- Also fixed an issue where the
'character in filters was producing an error in the Get Code Snippet. - Fixed an issue with editing the ID when adding a new record.
- Fixed scrolling behaviour when renaming or deleting Link columns in the Schema view.
- Sidebar links are now proper
<a>elements so you can right-click and open in a new tab.
- Community spotlight: The story behind xata-go, a Go SDK for Xata
- Search three ways with Xata. This pairs up with the 5 minutes video that visually demonstrates the differences between partial match, fuzzy free-text-search, and semantic/similary search.
- Do more with less round-trips. Our Transaction API endpoint can now not only
insert,updateanddelete,but alsogetdata by ID. An example looks like this:
{
"operations": [
{"insert": {"table": "items", "record": {"id": "new-0", "name": "feed the fish"}, "createOnly": true}},
{"update": {"table": "items", "id": "new-0", "fields": {"name": "feed the goldfish"}, "ifVersion": 0}},
{"get": {"table": "items", "id": "new-0", "columns": ["id","name"]}},
{"delete": {"table": "items", "id": "new-0"}}
]
}
- The “Get Code snippet” dialog is now a lot more helpful to Windows users as we’ve added support for
PowerShellandcmd🎉
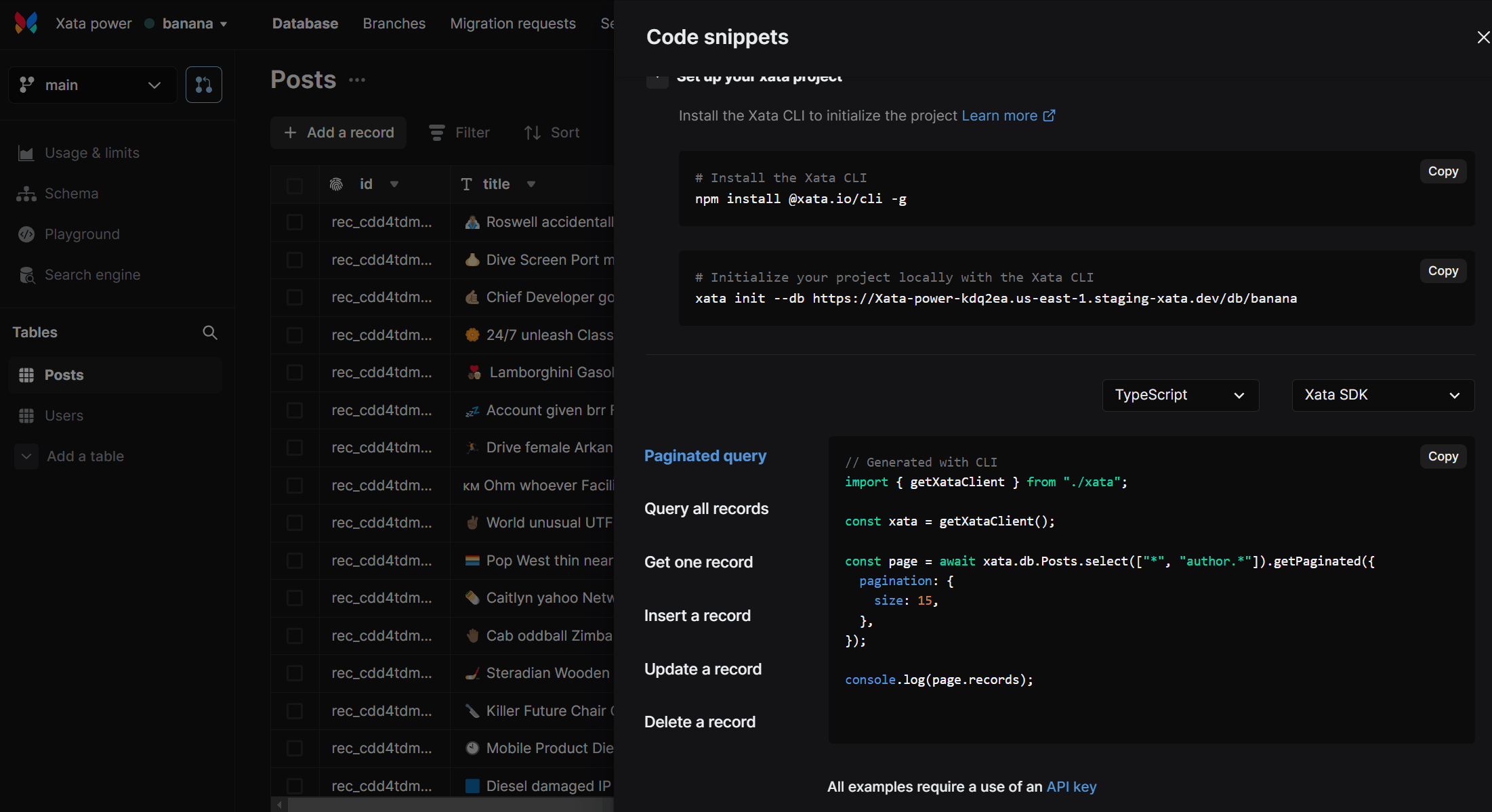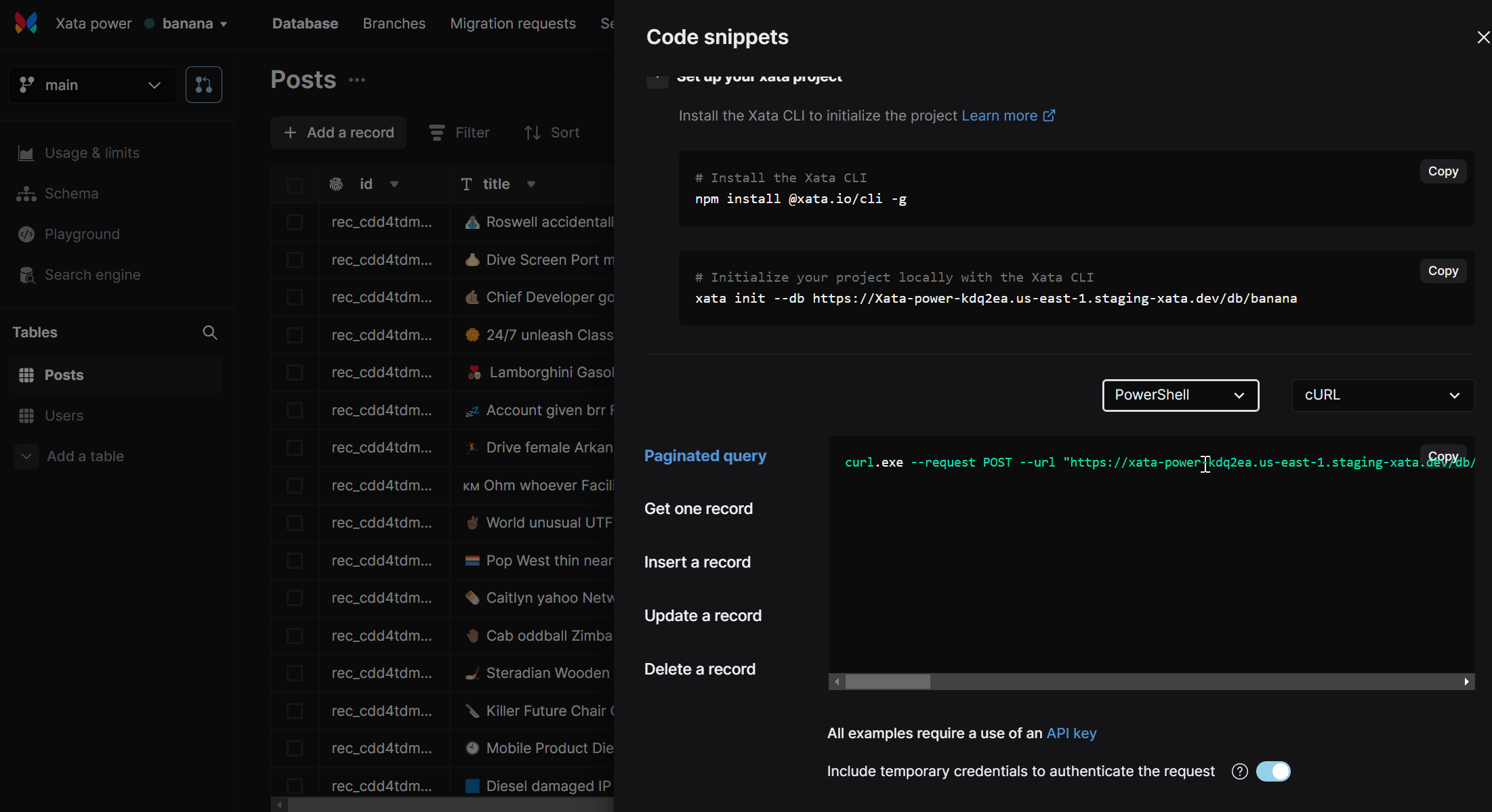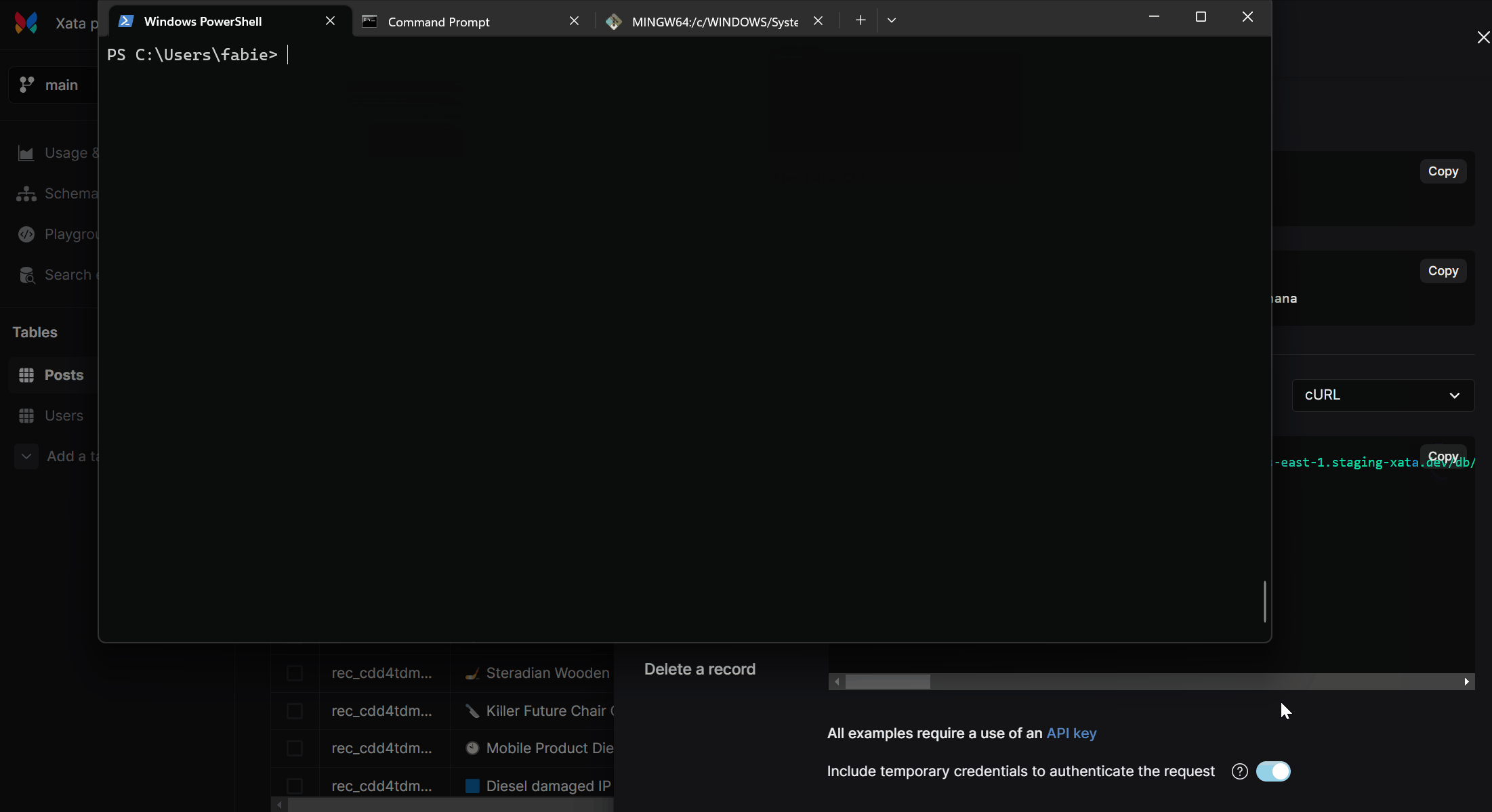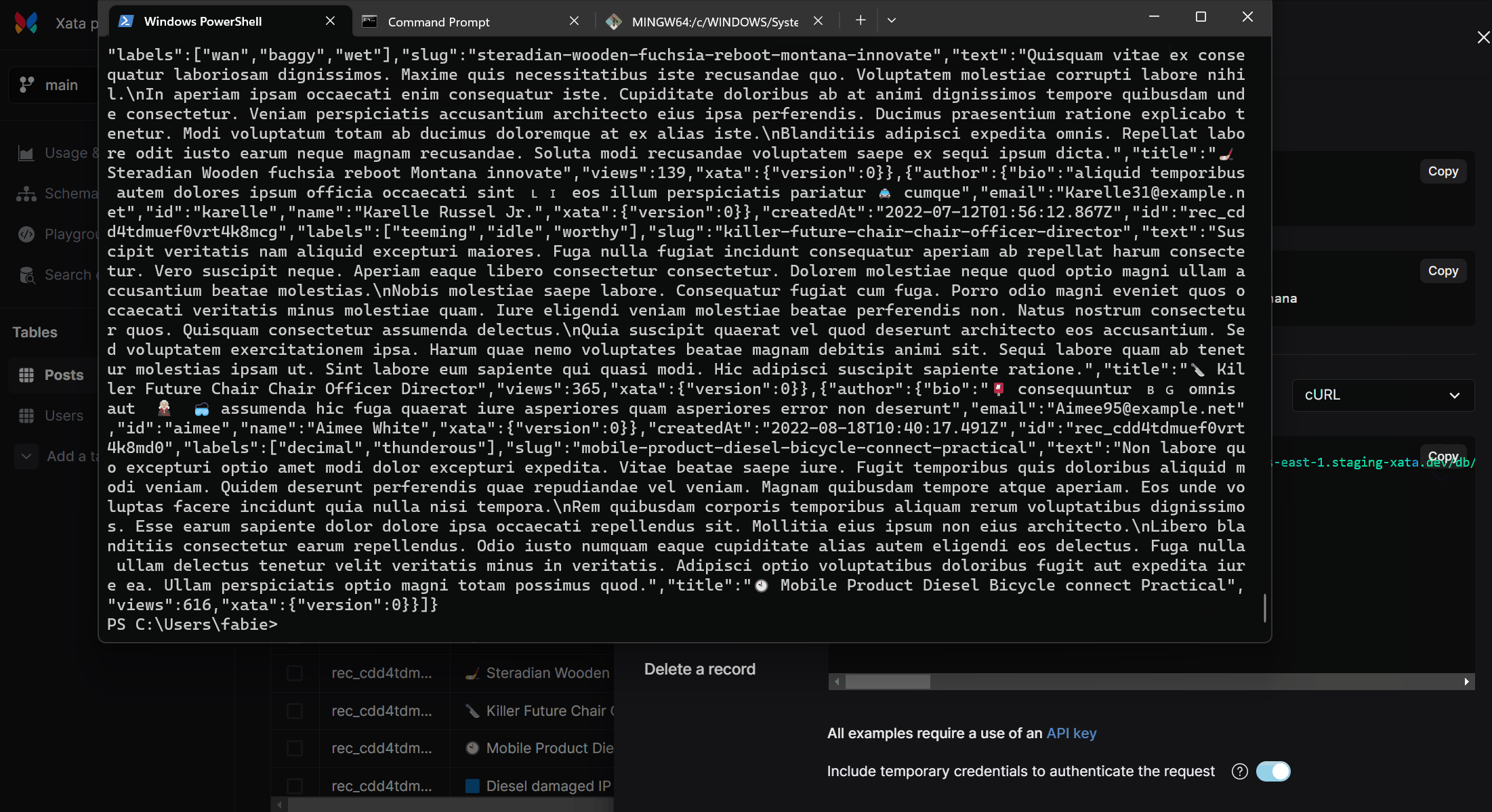
- Continuing our theme of quality of life improvements:
- Allow copy pasting of null cell values, because “nulls” are important to developers.
- Improvements in the filtering inputs.
- Fixed a bug where editing emails and numbers was sometimes moving the cursor at the end
- Xata and Auth.Js on 2 Next.Js Apps: App Directory and Pages Directory by Atila Fassina
- The Importance of Data Modeling in TypeScript by Fabien Bernard
- New Data in the Wild episode: Interview with Anna Maste formerly of Boondockers
- This twitter thread includes some new things we’re working on.
- Sometimes all you need is a bit of randomness. A new sort option allows you to “sort by random”. This can be useful, for example, to show a random sample of results from the table. To use, see the examples in the docs. The options looks like this in the API:
{
"sort": ["*:random"]
}
And like this in the TypeScript SDK (pending release):
const users = await xata.db.Users
.sort("*", "random")
.getMany();
- Fix: in some cases the context passed to ChatGPT was smaller than our target number of tokens, resulting in low quality answers. This is now fixed.
- Fix: drastically reduce the chance of
too_many_nested_clausesexception on the search and ask endpoints. Also improved the error message to guide towards a correct solution.
- Added the ability to filter on vector columns being NULL.
- Added the ability to paste an datetime into a datetime cell in the grid. e.g.
26/05/18ortomorrow at 4pm - Fixes for the behavior of the Chat bot when them Ask button is pressed multiple times or the tabs are changed.
- Fixed the display of empty strings as a default value in the Schema view.
- Added support for the vector column to the
xata schema editcommand.
- Semantic Search With Xata, OpenAI, TypeScript, and Deno - A light introduction to using the OpenAI API from TypeScript for a real use case.
- Xata and Auth.js on 2 Next.js Apps: App Directory and Pages Directory - A tutorial showing you how to use the Xata Auth.js adapter to easily implement authentication in Next.js
- Small changes to Getting Started docs to better reference Python options.
- Added atomic numeric operations to the update API. They work on the integer and float data types. They can be used, for example, to increment a counter without the risk of race conditions. Docs are in
- New date picker. A new custom-made date picker is used across the UI, solving a set of problems that we had with our previous solution. Among other things, the new date picker supports human input (e.g. “today at 4pm”) and has milliseconds support. The UI is also standardized to always use UTC, for better clarity on what is being stored in the database.

- Update the /ask endpoint to use the new ChatGPT API and the newly released
gpt-3.5-turbomodel. This has resulted in a pricing decrease and more questions included in the free tier. - Fixed error when a lot of nested clauses would cause the /ask endpoint to return 500 errors
- Corrected the license of the published OpenAPI spec to Apache-2
- Fixed pasting behaviour when a cell is in edit more. It used to overwrite the whole cell, now it correctly appends to the existing text.
- Several fixes around column constraints:
- Users can set default value without setting
notNull: true - Users can enter invalid constraint combinations but are presented with a clear error about what they did wrong.
- Switching column type resets unique,
notNulland default value to an allowed value if it's unsupported.
- Users can set default value without setting
- Prevent two table cells from being selected in some scenarios. There was a bug when data had changed in the grid and you let your browser tab lose and regain focus.
- Fixed copy paste null string values in table
- More minor cell editing bug fixes
- Small design issues cleanup across the app
- right input padding for table inputs
- clickable table headers in the schema page
- scrollable branch list

- Update the /ask endpoint to use the new ChatGPT API and the newly released
gpt-3.5-turbomodel. This has resulted in a pricing decrease and more questions included in the free tier. - Fixed error when a lot of nested clauses would cause the /ask endpoint to return 500 errors
- Corrected the license of the published OpenAPI spec to Apache-2
- Fixed pasting behaviour when a cell is in edit more. It used to overwrite the whole cell, now it correctly appends to the existing text.
- Several fixes around column constraints:
- Users can set default value without setting
notNull: true - Users can enter invalid constraint combinations but are presented with a clear error about what they did wrong.
- Switching column type resets unique,
notNulland default value to an allowed value if it's unsupported.
- Users can set default value without setting
- Prevent two table cells from being selected in some scenarios. There was a bug when data had changed in the grid and you let your browser tab lose and regain focus.
- Fixed copy paste null string values in table
- More minor cell editing bug fixes
- Small design issues cleanup across the app
- right input padding for table inputs
- clickable table headers in the schema page
- scrollable branch list
Copyright © 2024 Xatabase Inc.
All rights reserved.