How we implemented database renaming
Starting today, you can now rename your Xata database
By:
Noémi VányiPublished:
Reading time:
5 min readIt may seem simple, but the hard things always are. Starting today, you can now rename your Xata database!
You can either rename your database from our app, the CLI, the SDK, or the REST API.
Now let’s look at how it all comes together.
Renaming databases is a fundamental feature that every database should support - it is a basic operation. When you create your database you might change the database name from the singular to the plural. For example, I initially named the architecture record directory for my team at Xata as "decision." Then I realized that "decisions" would be a more appropriate name. So, I had to delete the existing "decision" database, along with its associated tables and schema, and create everything again under the new name. It's common to iterate on the database name a few times during the creation process.
After you have built an application on top of your database, it’s less likely that you will change its name. This is because the database name is usually incorporated into the REST API URL. It's comparable to renaming a GitHub organization. When you rename an organization or transfer repositories, you need to update the URLs in your local git configuration to ensure everything functions correctly.
So we are optimizing for renaming the database several times at the beginning of the schema creation, when you only have one or two database branches. Later in the database life when you integrated it into your application, you are less likely to change it as it requires greater effort to update the URLs accessing your database.
Technical details
In Xata there are two planes, the control plane for routing and regions for storing user data and metadata. We store database metadata including the database name and branch names in DynamoDB. When you rename your database, we must update both the database entry on the control plane and database and its branch entries in the region.
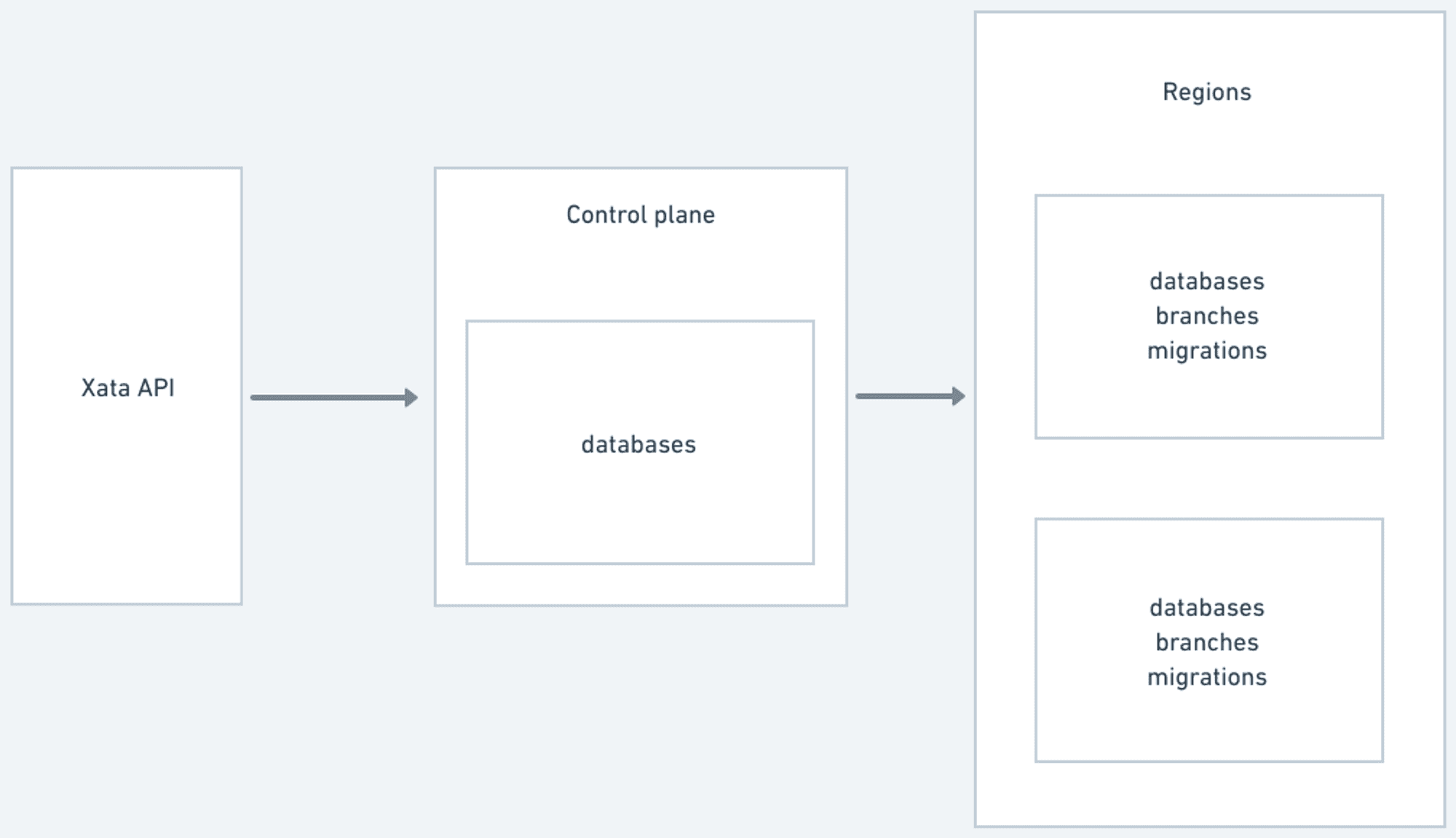
Updating the database name
In our data model database names are part of the sort key for both databases and database branches. Furthermore, to make the problem more complex, we also store database names in Stripe for paid branches. Unfortunately, there is no way to update a sort key in DynamoDB, so we have to recreate the items.
Alternatively, to avoid recreating items, we also considered putting the database ID in the sort keys. Then on top of the existing table, we wanted to use either a local secondary index (LSI) or a global secondary index (GSI). The downside of using a global secondary index is that it is eventually consistent. When an item is updated in the table, there may be a delay in propagating updates to the index, resulting in potentially outdated data being returned. Running schema migrations on database branches proved to be problematic for us. Specifically, we encountered issues where certain migrations, such as adding columns, would fail due to outdated data in the index.
Local secondary index eliminated the issues during migrations as it is strongly consistent. However, this approach requires a complete table rewrite because LSI can only be added to a table at table creation. We scrapped the idea because the effort was not worth it.
Decision
Keep in mind that our optimization efforts are focused on scenarios where users rename their database only a few times during the initial stages of creating a new database. After the application is deployed, they are less likely to rename due to the overhead. Thus, we decided it is not necessary to include the database ID in the sort keys (SKs) of the database and database branches. Lookups must be fast and easy based on workspace IDs and database names.
As I mentioned above, we stored the database name in Stripe. We want to avoid touching billing metadata whenever possible, so we decided to use IDs instead of names.
We choose to recreate database and branch items in DynamoDB when the database is renamed. This approach required the least amount of data migration and no significant schema changes.
My tips for migrating data in production
Currently, we do not have a platform for maintaining production metadata. Instead, we had to use scripts to get the job done. If you are part of a small startup, here are a few tips for when migrating production data:
- Pair up for perfection. Always migrate data pairing up with someone else on your team. Not only does this help with sharing knowledge, but it is crucial that someone else double checks your commands before running them on production data.
- Dry-run is a must run. Add a dry-run flag to your script to see what operations it is trying to perform. This way you can validate that the script is going to do what you expect.
- Preserve the past. When updating fields in an entry, always store the old value in case you have to revert your changes. When the migration is finalized, you can always clean it up.
Migrations
We store database metadata in both planes. However, the database IDs were different for the same database on different planes. First, we had to change that.
The migration involved reading the ID from the control plane and copying it to the databases in the region plane in every region. We preserved the old ID of the databases in a separate column. So, if we decide to revert the change later or something gets mixed up, we still have the old IDs.
Another missing piece from the regional DynamoDB tables was the database ID for database branches. When communicating with Stripe we decided to use database IDs, so we must be able to find the database ID of the database branch. We again had to get together and backfill the database ID for every database branch.
Lastly, we migrated customer metadata in Stripe. During this process, we changed the name to the database ID. As a result, Stripe now uses the database ID in the callback to our backend, allowing us to update the number of units associated with the corresponding database branch. We can perform a lookup using a local secondary index and proceed to update the usage plan for the relevant branches whenever a customer purchases additional units.
That is the tale of database renaming. Let us know if you find any issues either on Github or Discord. If you don't have a Xata account yet, sign up for free! We have a very generous free plan.
Thank you for sticking around and happy database renaming!
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.