File Attachments: Databases can now store files and images
Extending a database record to include a new file column type with a global CDN, common security boundaries, and image transformations.
Written by
Sorin Toma
Published on
August 30, 2023
Today, as part of our launch week, we’re beyond excited to announce a feature that we've wanted to add ever since we started Xata: File Attachments. Think of it as having a new database column type where you can store files of any size, and behind the scenes they are stored in AWS S3 and cached through a global CDN. Files simply become a part of a database record. For example, they respect the same security boundary -- if you can access a record, you can also access its attached files. Image file types also get some extra functionality allowing you to request them at any size and style with built-in transformations. With this release, we aim to simplify your application architecture and reduce the number of services you need to manage.
In this blog we'll dive into the capabilities released today and architecture behind our implementation. We hope you enjoy the read as much as we did building it 😃
Both files and relational data are ubiquitous in today's applications. Even the most basic scenarios generally require both structured relational data and file storage. Think about a blog which uses both posts metadata and images, a product catalogue or a document library. They all require basic data record management and query capabilities, as well as storage and access to large binary objects like images, videos, and documents.
We often see engineers using a relational database with a separate storage service to store the data used by their application. In most cases the binary files are related to the relational data, therefore the common pattern is to store a file link in the database. This experience adds unnecessary friction and we saw an opportunity to simplify. Because file storage use cases are so closely correlated to data, we decided to embed file attachments directly into our serverless database and bring a new experience for building data apps that require binary storage.
We've shown this feature to a number of developers before releasing it, and this is the type of feedback we've received on our approach so far:
Xata has become a critical part of my development cycle because I can quickly create and modify data structures without having to handle the database and migrations myself. Extending my records to include images has been great because I can easily apply transformations to them in the SDK. What I'm really excited about the ability to store any file type securely inside my database, it allows me to eliminate additional services like AWS S3.
Sebastian Gilits - Entrepreneur
We chose Xata as our DBaaS for KWARECOM’s Mapping and Reporting Portal because of its low latency and serverlessness in comparison to other options out there. Our performance expectations are met. We’ve come to know and love their latest file storage offering; very unique and appealing. The CDN backed images are fast and the simplicity Xata provides means we at KWARECOM don’t need to worry about the complexity on the backend anymore.
Titus S. Zoneh - CEO @ KWARECOM
The DX for images and file storage in the Python SDK and REST API were out of this world. I’m using images and file storage for an article classification tool. The simplicity of having image transformations baked into the record API is second to none. When my students at Berkeley are looking to spin up a quick project, I’m going to point them to Xata.
Will Monge - Engineering Lead @ Good Research
Let’s take a deeper look into what gets simplified and how Xata achieves this.
We’re really excited about today's release because it packs a lot of functionality into the simple experience of adding another column to your database. We wanted this experience to feel familiar, like adding and viewing an attachment in a spreadsheet instead of dropping a file into a generic bucket. When we started to work on the file attachments, we had the following goals in mind:
- Relational and storage APIs should share the same endpoints and the same connections. It is easier to work with and maintain one service rather than two.
- APIs must share the same authorization scheme and the same permissions model. Avoid having to use different credentials and keep permissions in sync.
- Relational data and binary object data should share the same region. Both data types should reside in the same compliance boundary and have similar guarantees.
The first step in our design was to acknowledge that relational data and large binary objects have very different consumption models and trying to fit both into the same storage service leads to unacceptable compromises. One size doesn’t fit all. Serving large binary objects from a relational database cannot match the performance of a dedicated storage service in terms of compute cost, concurrency and throughput. The opposite is even more obvious, a storage service cannot match the querying and data management capabilities of a relational database.
Like with any design challenge, we had to devise a solution to address seemingly conflicting requirements. The APIs for relational data and binary objects needed to be unified, while the backend storage had to differ to achieve the expected performance and feature set.
At the API and database schema level, the binary object data type became the file column type. You can attach one or multiple files in a column to a record in your database. This approach allowed all existing Xata features to work with the file type without any API change.
Using the existing Xata REST APIs or SDKs, and the same connection, a developer can now upload a file, download a file, run queries over files using filters, aggregations, joins, and even run search queries to match file metadata.
In the record model the file column holds a JSON object with a predefined schema which contains both file metadata and the file content.
{
"name": "Butterfree.png",
"mediaType": "image/png",
"size": 75,
"version": 1,
"attributes": {
"height": 475,
"width": 475
},
"base64Content": "iVBORw0KGgoAAAANSUhEUgAAAAIAAAACCAYAAABytg0kAAAAEklEQVR42mNk+M9QzwAEjDAGACCDAv8cI7IoAAAAAElFTkSuQmCC..."
}Thinking further about typical relational data and file storage use cases, we noticed significant commonalities and differences. The management of files maps very well to relational data management. CRUD operations are similar in the sense that they work over organized data, entries have owners, there is a permission model in place, and they offer a level of consistency and durability. In general we can say that the write patterns are fairly similar. An application for managing files can very well use a database API to achieve the same.
The important difference comes with the read patterns. Relational databases are designed for complex queries, which can involve high usage of CPU and memory, while storage reads have minimal CPU and memory usage. Because the operations are extremely simple, the storage reads generally scale to much higher request rate, concurrency and throughput. Therefore storage read patterns expect very high concurrency and throughput with minimal cost. Offering the database read for files retrieval will not meet the expectations for a storage service.
We will call this high scale read use case, the content distribution scenario. To address content distribution, Xata introduces direct access URLs. They can be retrieved by reading the file column. Accessing the URL does not involve a database call and therefore they are NOT subject to Xata concurrency and rate limits, and can make use of the storage service capacity.
Since file attachments share the same endpoints with the Xata APIs, the same authorization scheme applies. Whether you are using API keys or OAuth, the same credentials can be used for managing files. This single service approach reduces complexity on the client side and at the same time guarantees that future authorization methods and future permissions models apply uniformly to both records API and file attachments API.
As we discussed in the previous section, there are two distinct usage scenarios for files. The first is the common relational data approach where the operations are file CRUD and metadata query. The common authorization applies here. Access to the file is conditioned by the user having access to the database record.
The second scenario is the content distribution through direct access URLs. In this case the authorization requirements are very different. If resource management requires a trusted security model, content distribution sometimes requires unrestricted access.
To cater for different URL access needs, Xata provides 3 levels of authorization for the URLs that it generates.
- Public Access - the requests to retrieve the file are not subject to any authentication or authorization. This is very convenient for truly public content, but can be very dangerous if configured by mistake on sensitive data. By default, all uploaded files are private (the access URL requires authentication). Public access can be configured per file to allow maximum flexibility. The default can be updated per column, for scenarios where all files need to be public.
- Signed URL - Xata can generate a signed URL which grants access to anyone having the URL for a specified amount of time. This is commonly used in scenarios where an image is rendered but the URL cannot be further shared because it expires shortly. The default timeout is 1 minute, but it can be configured per file.
- Authenticated URL - the requests need to include a valid Authorization header in order to retrieve the file.
All the access URLs offer lower latency compared to file retrieval through the Xata API because, apart from the authorization check (for signed and authenticated URLs) they go directly to storage skipping Xata middleware and the database service.
Going further on storage performance, modern applications require low latency across the globe.
We could not claim to simplify working with files and then ask customers to configure and manage their own CDN to get reasonable global performance. As a result, the support for file attachments includes built-in CDN capabilities. There is no opt-in and no action is required to enable it; all direct access URLs are served through a CDN by default. In essence, all files retrieved through a URL are cached at the edge, making the following requests blazing fast.
Xata opted to integrate Cloudflare’s Global CDN for its wide geographical coverage, its performance and its feature set.
As with any cache, the great performance improvement comes with the fundamental problem of stale cache entries and cache invalidation. Xata addresses stale cache entries by design using immutable file objects. This means any update to a file is in fact a new file object, with a different ID generating a different URL and eventually a different cache entry. This pattern is also known as versioning, because conceptually the cache keys change with every version of the object.
Following this pattern, when the client application loads a set of records from Xata, it also gets the most up-to-date URLs which are guaranteed NOT to hit a stale cache entry, no matter where the cache is (browser, web proxy, CDN). This is very important because the user can clear the browser cache and Xata can invalidate the CDN cache, but a web proxy in between might still serve a stale cache entry. Versioning guarantees this can never happen. The downside is that file URLs are not persistent and they should not be used as static resources. However, this fits the Xata model of attaching binary objects to database records. Similar to the database records, the URLs are dynamic content and needs to be retrieved through database reads and queries.
We have seen that content cannot be stale, but there is an important note on permissions. When a public object gets cached, changing permissions will not invalidate the cached entry. Making a file private applies immediately for new URLs, but the file is still accessible through old URLs until the cache entry expires in 2h. Xata advises greatest caution when configuring public access, because in practice there is a delay in changing the permissions from public to private.
Looking at the most common scenarios where relational data is used together with binary files, the image use case stands out. All web applications use images today and images tend to require processing before they are rendered. Xata file attachments come with a comprehensive set of image transformations -- from resizing to photo adjustments to changing format and compression.
All transformations are applied at the edge and are cached by default. Again, Xata leverages Cloudflare functionality for image transformations.
We considered more flexible transformation definitions through query parameters or request body objects, but in the end chose the industry standard of defining the transformations in the URL path. This makes it easier to embed the transformation into a web page and the transformation is automatically included in the cache key within the CDN.
https://eu-west-1.storage.xata.sh/transform/rotate=180,height=50/nj42n37o4l3dd19fe6vsh4plkk
Generally, our philosophy is to abstract away complexity where we can so our end users don’t have to worry about it. File attachments is no exception to this strategy.
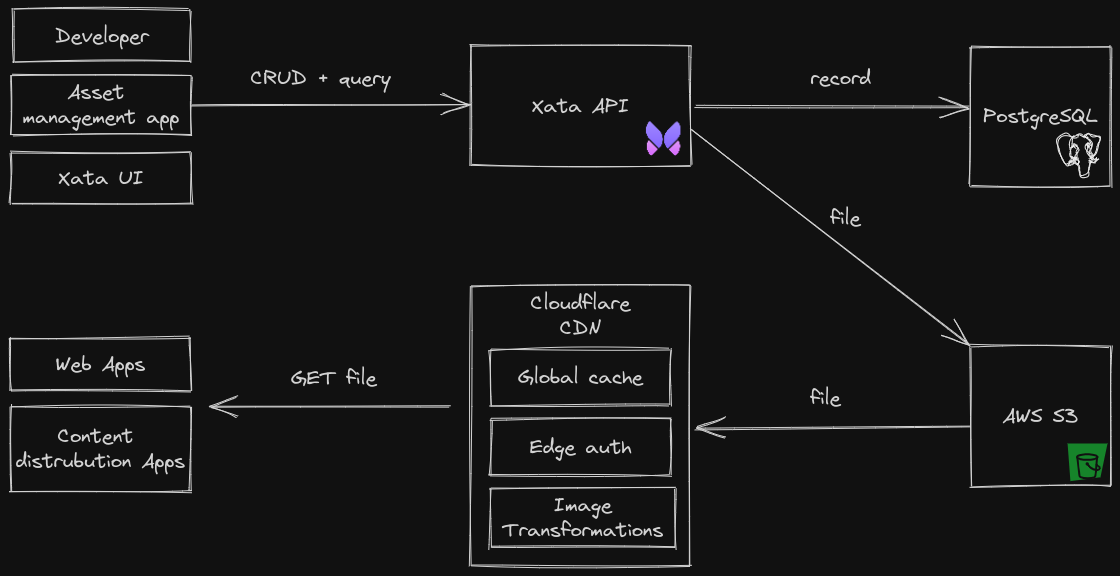
Behind the scenes, the file data is actually stored in two places. The file content is stored as an AWS S3 object while the file metadata (name, type, size, S3 pointer) is stored as a JSON object in the PostgreSQL database table.
We chose S3 for the binary object storage for its high performance, durability, availability and because it shares the same compliance certifications with the AWS Aurora, which we use for running PostgreSQL. This way, all data (relational and binary objects) is located in the same data centers and benefits from the same compliance guarantees.
The fundamental challenge when writing state to two different services is making it transactional. Xata service implements two-phase commit semantics to ensure that a file write either completes successfully or is rolled back. This is one of the key operations where Xata does the heavy lifting and abstracts away the complexity. The client code can rely on the transactional guarantee and no longer be concerned with two-phase commit or dealing with an out of sync state.
A second set of challenges comes around data deletion and cleanup, where again it is not trivial to keep the state in sync between two services. With database tables, Xata takes the cautious approach of delayed cleanup. This allows us to offer undo delete operations (not exposed yet) and to have a general recovery option in case of accidental deletes. When file content storage comes into the picture, it needs to follow the same pattern. Restoring only half of the deleted data is not particularly useful.
The implemented solution treats the PostgreSQL metadata as source of truth and removes the associated file data only when the corresponding records are deleted from PostgreSQL. This is achieved by hooking into the PostgreSQL replication and handling delete record events. This is an elegant way of replicating the deleted state from PostgreSQL to S3, but unfortunately it is only half the solution, because it only handles individual record or value deletes. When data is deleted by dropping entire columns, tables, databases the events are not captured in replication so Xata handles this separately by scheduling bulk deletes.
Backup support adds another level of complexity. Xata creates regular backups and can perform a restore on request. The binary object storage needs to match the ability to restore the state from the time of the database backup. This is achieved through a combination of immutable S3 objects and configuring S3 lifecycle. Deleted files become inaccessible, but they are kept for 7 days after their deletion for recovery purposes. After the 7 days the files are permanently deleted.
If you look at the file column JSON example shown earlier, it might strike you as odd. Files don’t come encoded as base64 and they are certainly not used in their encoded form.
Xata APIs are JSON based and therefore the file content needed to fit in a JSON object. We chose to use Base64 encoding as it is the most common binary encoding and has the widest library support across languages. For a client application that has binary content in a buffer, it should be trivial to encode it as Base64. The Xata SDK offers helpers here.
While we recommend this approach when dealing with small files and when extending existing apps that already use Xata APIs, we acknowledge there are drawbacks in using the Base64 encoding. For very large files or for very high throughput applications, the extra CPU cost of encoding and decoding the files begins to matter and it is exposed in the delivery latency. Also, the extra 33% in file size added by the encoding impacts the size on the wire and implicitly the performance and bandwidth costs.
To alleviate these concerns we introduced binary file APIs. These APIs use similar endpoints but they accept and they retrieve binary content. For files larger than 20MB these are the only APIs for uploading content.
It is important to mention these are still database APIs, they involve reads and writes of metadata to PostgreSQL and they are not direct S3 wrappers.
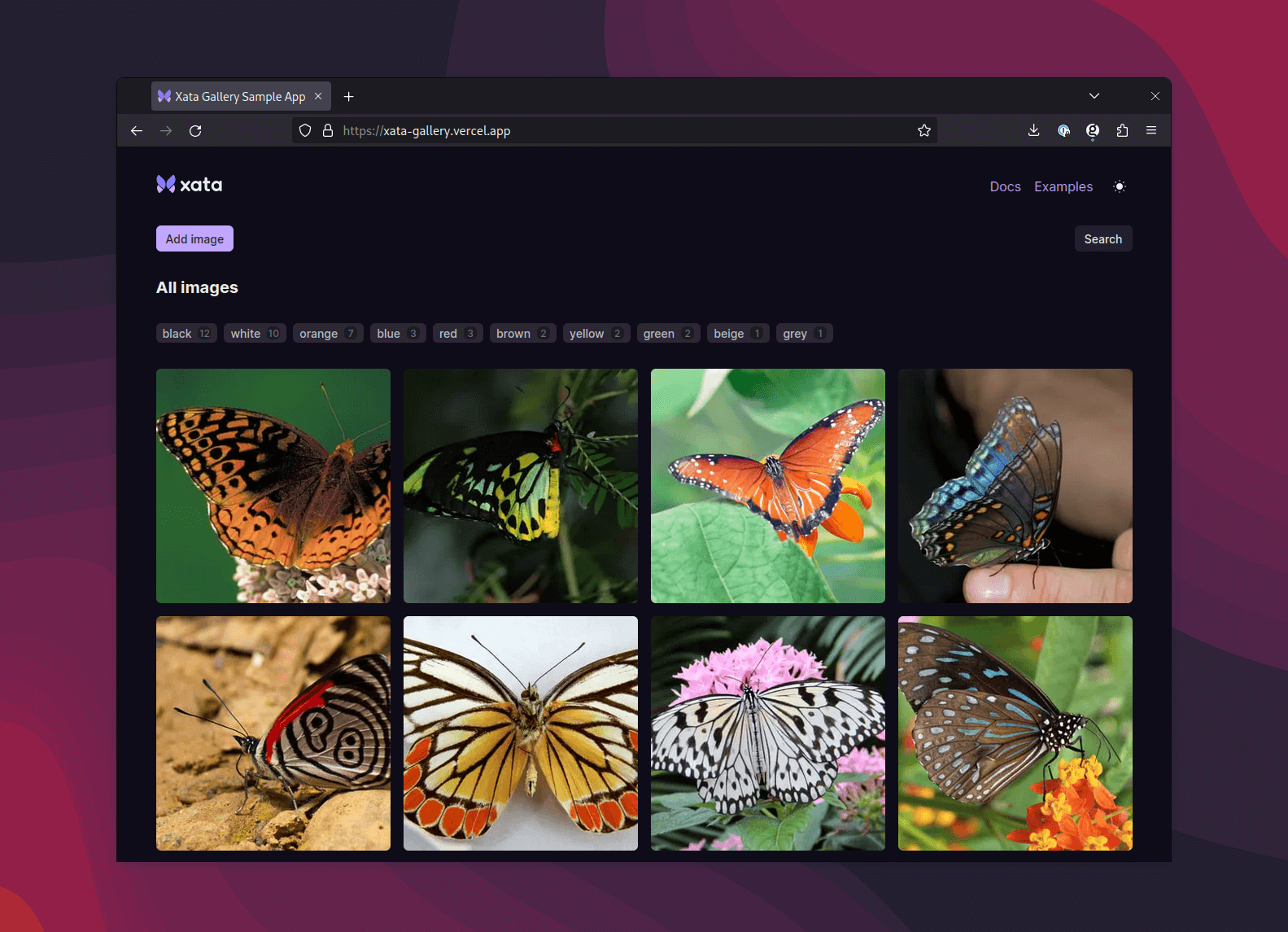
We have launched this functionality with an example image gallery app to highlight the developer experience you get with Xata and give you a starting point to try it out. This example combines full-text search, aggregations, files, and image transformations. If you’d like to get started, be sure to check out our example repository.
Before releasing file attachments, we decided to open up an early access program for those interested in our community. It was our first early access program since our private beta last year, and we were blown away by the amount of support and engagement we received from our honorary Xataflies. We sincerely want to thank everyone that participated. This feature would not be as amazing as it is today without your help 🙏
Want to join in on the fun with our community? Sign up for our content hackathon here to win some prizes and get some sweet Xata swag.
Xata is simplifying the patterns of working with relational data and binary objects together. If you are facing any of the problems described in this post, we welcome you to sign up and try Xata. We’d love your feedback on this feature, if you have any suggestions, questions, or issues reach out to us on Discord or follow us on X / Twitter.
Start free,
pay as you grow
Xata provides the best free plan in the industry. It is production ready by default and doesn't pause or cool-down. Take your time to build your business and upgrade when you're ready to scale.
- Single team member
- 10 database branches
- High availability
- 15 GB data storage
- Single team member
- 10 database branches
- High availability
- 15 GB data storage
Copyright © 2025 Xatabase Inc.
All rights reserved.