Geographically distributed Postgres for multi-tenant applications
Documenting a pattern for making multi-tenant applications global by distributing the data, using only standard PostgreSQL functionality.
By:
Tudor GolubencoPublished:
Reading time:
9 min readWe'd like to document a pattern for distributing Postgres databases to multiple regions or even multiple clouds. You can do this with any managed Postgres service or by self-hosting, because it doesn't rely on any functionality beyond what is available in a standard Postgres installation.
In short, the pattern looks like this:
- Separate per-tenant data tables from the control plane tables.
- Place the per-tenant data tables in the region closest to where you expect the users to be.
- Create a global view of the data by using Postgres Foreign Data Wrappers (FDW) and partitioning.
- Keep authentication and control plane data in a single region.
Why
First, many applications happily live in a single region and there's no reason to complicate them. However, if you have a global customer base, there are a few reasons for which you might consider distributing your data to multiple regions:
- Lower latencies. A round-trip-time from Sydney to
us-east-1is about 200 milliseconds, and that becomes quickly noticeable if you need multiple round-trips. If you know that a particular customer lives in Australia, it makes sense to store their data there. - Data residency laws. Regulation (with greetings from the EU) might require you to ensure that any private data of a customer is only ever stored in a particular geographical region.
- Apps running on the Edge. If you'd like to use something like Cloudflare workers but also want to use Postgres, you'd better have some distributed data strategy, or you'll end up paying a lot of latency costs, especially if your app needs multiple round trips to the database.
- Multi-region and/or multi-cloud. This can be a goal in itself, if you don't like putting all your eggs in one basket. Every once in a while, the AWS us-east-1 region goes down for a few hours and takes with it 70%ish of the internet. With a multi-region setup, you can reduce the blast radius of events like this.
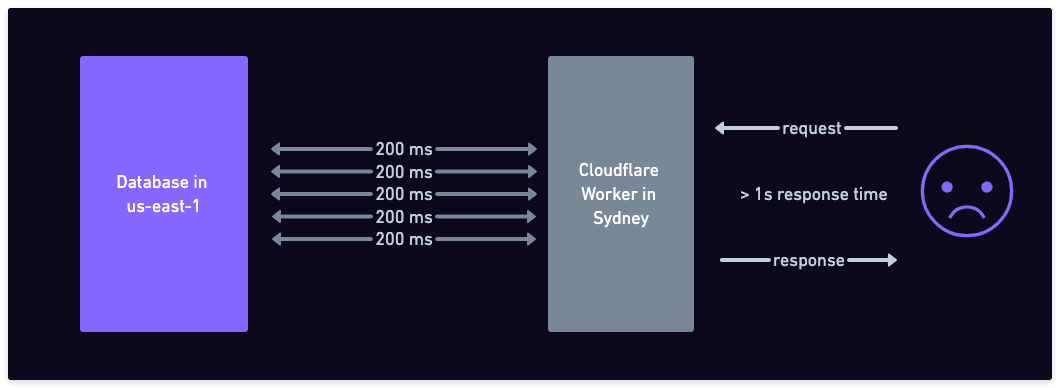
Five round-trip times to the database add up to >1s wait time for the user
When does this pattern fit?
This pattern works when two conditions are met:
- Most of the data model can be segmented by a particular key (e.g. customer id) into "tenants".
- Each tenant has a natural "affinity" to a particular region.
To illustrate, let's imagine a multi-tenant SaaS service, like a Notion clone. Most of their data (pages, blocks, tables, comments, files, editing history) can be neatly separated by workspace. The data inside a workspace is relational and highly inter-linked (e.g. pages contains blocks and files, blocks can have comments), but there are no foreign keys between workspaces, meaning you can't link to a block in a different workspace. In this case, a workspace is a "tenant".
However, not all the data has to be specific to a tenant, which is why the word "most" is used in the first condition above. The users table, the list of workspaces, and the membership information between users and workspaces might sit better outside of the "tenant" data. We call this the "control plane" data. The control plane data doesn't need to be segmented.
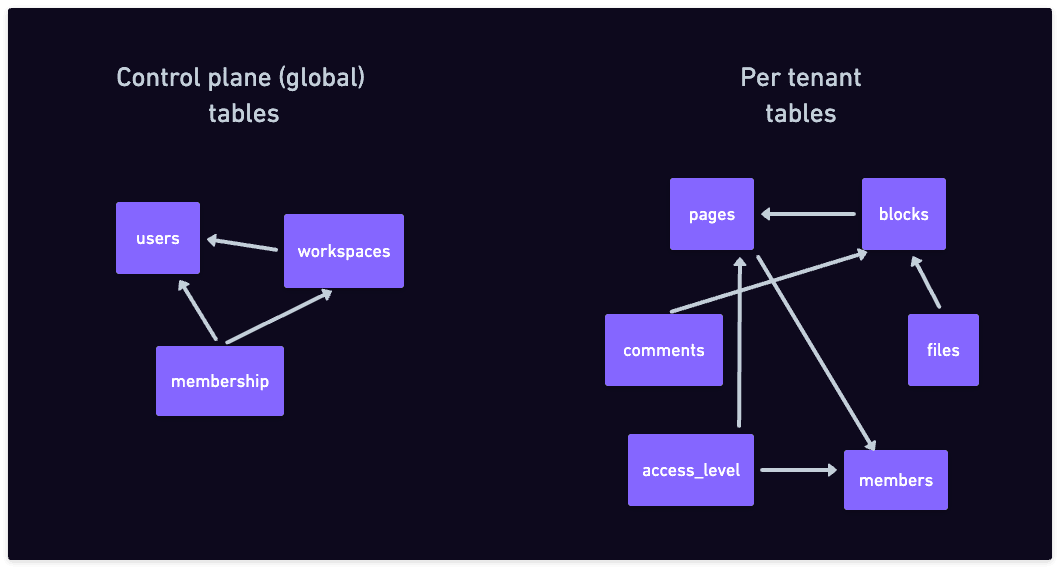
Data model for an imaginary Notion clone
The second condition talks about the "affinity of a tenant to a region". This means that a particular tenant's data would be accessed mostly from a particular geographical region.
In the Notion-clone case, we could make the assumption that if a workspace was created in Europe, it probably belongs to a company in Europe, and it will probably be mostly accessed from Europe.
These two conditions are usually easy to satisfy for B2B multi-tenant SaaS applications. For example, Notion and Slack have workspaces as tenants, Github and Vercel have organizations as tenants, and so on.
Centralized control plane and authentication
In this pattern, the control plane data tables are kept in a single central region. This typically includes the users table, which means the authentication is done from this central region.
On the other hand, the tenant data is distributed to the region where the tenant has the affinity. Because the data is segmented by tenant, all foreign keys point inside the tenant. This means that by connecting to a single region, you can access all the data for a particular tenant.
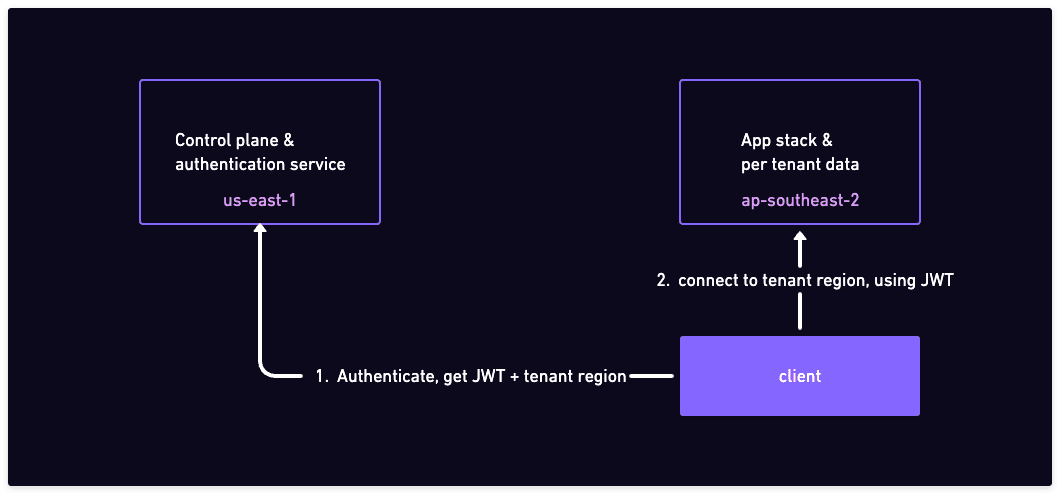
Authenticate with the central region
It does mean that logging in and signing up is a bit slower because they are served from the central region, but those operations are relatively rare.
A copy of the application stack is deployed in each region. After logging in / signing up, a JWT (or other similar tokens) are used to authenticate on the data plane. This means that every subsequent request can be sent directly to the region where the tenant data is stored.
Alternatively, the application stack can run on an edge platform (e.g. CloudFlare workers) and therefore automatically close to the user and (hopefully) close to the tenant region. In this case, the client can pass the tenant region as part of the request, and the edge platform can route the request to the correct region.
Distributing the per tenant data
In our Notion clone example, let's look at how we'd distribute the pages table. We're assuming a simplified schema for this table, with a page id column, title and URL columns, and the workspace id foreign key. We're also going to add a region column, which will be used to partition the data. This last one is not strictly required, but it will help with partitioning (see below).

Pages table, grouped by tenant and region
We're showing a single table here, but keep in mind that the data is relational with many foreign keys pointing to other tables. Yet, all the foreign keys point inside the tenant, which means that all tables can be distributed in the same way.
We're going to create a posts table in each region and store there the data for the tenants that have affinity to that region. In our example, we're going to have three Postgres instances in three regions, and each will have a pages table with the same schema.
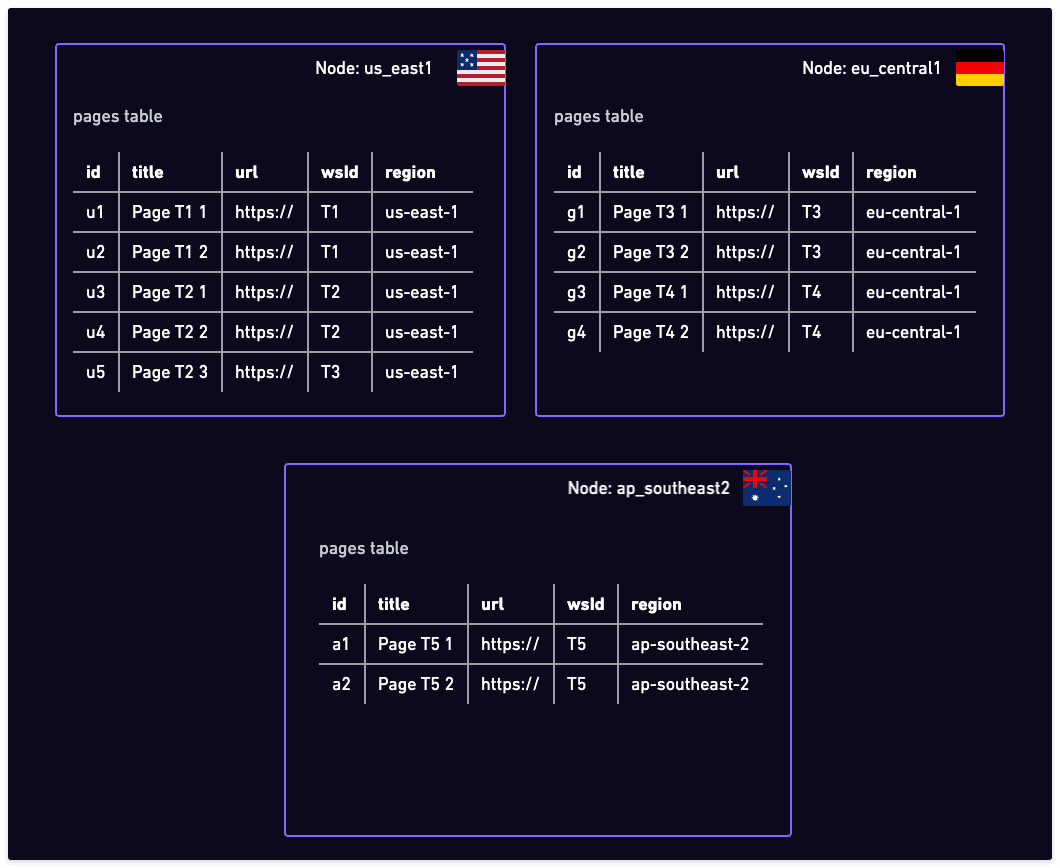
Distributed pages tables
Note that you would want to generate globally unique IDs for pages, so that you can avoid conflicts when merging data from different regions. You can use UUIDs/ULIDs for this, or you can use a combination of region ID and a local sequence.
What if you need to query more than one tenant?
If you can keep your application to only ever need to access data from a single tenant at a time, it means that you can simply connect to the node that has the data for that tenant and treat it as a regular Postgres database (which it is). This means that you get:
- same ACID guarantees
- same performance
- all Postgres features including extensions
But what if that is the case for 95% of your application, but occasionally you need to query or aggregate data across all tenants (for example for reporting)? Or what if you occasionally need to write data to multiple tenants at the same time?
What if I told you it's possible to create a global view of the pages table, that looks like a normal Postgres table, but is actually a view that aggregates data from multiple Postgres instances?
Let's say we use another Postgres instance as our "controller node". In this Postgres instance, we mount the pages table from all the other Postgres instances using the postgres_fdw extension (comes with the default Postgres installation). We also create a partitioned table that will act as the global view of the pages table.
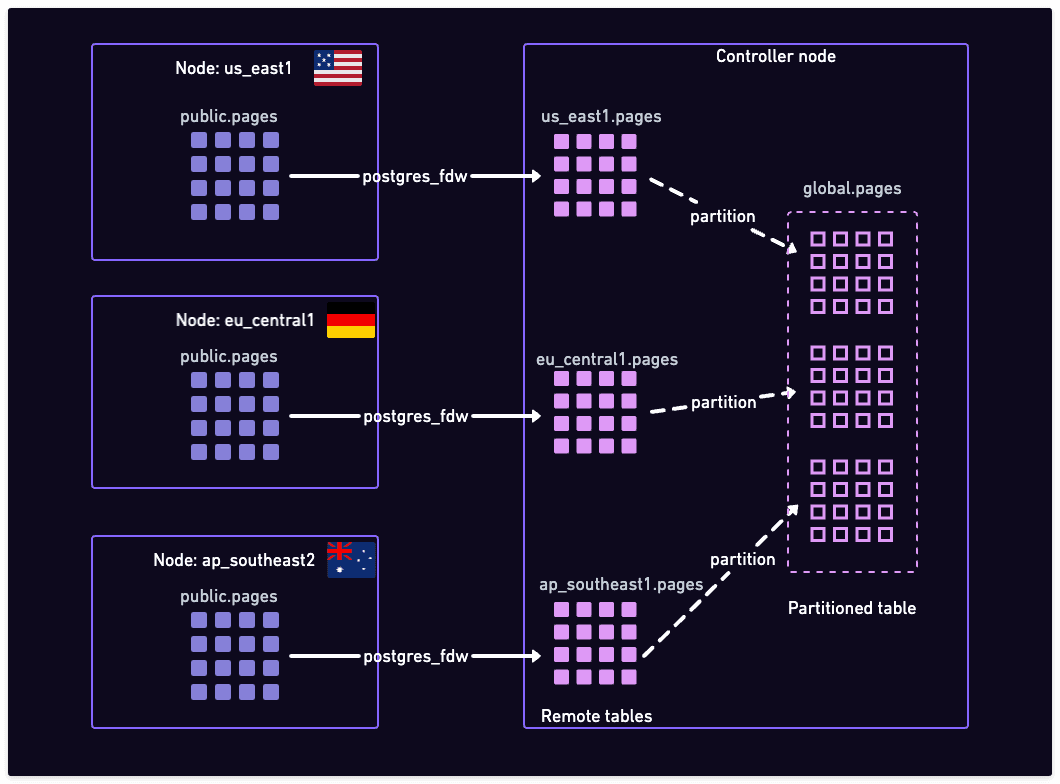
Global view using FDW and partitioning
In the above, the tables are presented with their schema name. In the data nodes, we assume the schema name is public. When mounting the tables to the controller node, we use a schema name that matches the region name, or the node name. This is a convenient way to keep track of where each table is coming from.
For example, here are the commands to mount the pages table from the us_east1 node to the controller node:
First, define the remote server:
Import remote tables, all at once, in a dedicated schema:
You can now query use the us_east1.pages table as if it was a local table.
After you have done this for all the other nodes/regions, you can also create a partitioned table that will act as the global view:
You can query the global.pages table as if it was a global view of the full data.
You can also insert data via the global.pages table, as long as you provide a value for the region column (or have a default set on the column). The data will be routed to the correct node.
While for simplicity we have used a separate controller node, you can also create the global views in any or all of the data nodes. In this case, you can use both local and remote tables as partitions of the same partitioned table.
Limitations
While the FDW + partitioning trick (for lack of a better word) provides a global view that you can query and write to, it does have some important limitations at the moment. Note that these limitations apply only when you are accessing or writing via the global view. That's why we're saying that this pattern works best, for now, when you rarely need to use the global view.
Performance impact: it's complicated. Accessing a remote table is a lot slower than accessing a local table, especially when the table is half-way across the globe. Also, transferring a lot of data over the Internet is slow and expensive, so that becomes another optimization metric. In order to create the optimal plans, the Postgres planner needs to be aware of these things and take it into account. As of today (Postgres 16) however, this is unfortunately only partially the case.
Write transactions across regions are not ACID. As we've mentioned earlier, inserting data via the global tables works well. However, transactions that span multiple remote tables are not true ACID. This is because the current Postgres FDW does not support two-phase commit (2PC) or other mechanisms to ensure that the transaction is atomic across all nodes.
The future
As we've seen, this pattern works great as long as you don't need to access or write to multiple tenants at the same time too often, which is typically the case for multi-tenant SaaS applications.
A variation of the same pattern can be used to horizontally scale multi-tenant applications. Instead of the region column, use a node column and use it to partition the data across multiple nodes in the same region. You can split tenants by any property you choose (e.g. free vs paid), or simply hash by the tenant ID.
Over the longer term, as the Postgres FDW, partitioning, and planner improve, we can expect the global views to be more performant and that will make this pattern useful for a wider range of applications. This would mean that in order to obtain distributed Postgres you wouldn't need to use an extension like Citus, you will be able to do it with the standard Postgres code.
As part of our own "distributed Postgres" project, which we have already teased in the pgzx release blog post, we have been thinking about how to pull this future forward. We're excited to share more about this in the coming months. If you want to be in the loop, we have a newsletter dedicated to our open source projects, where we share our progress.
If you're looking to distribute your Postgres database, either geographically or horizontally in the same region, we'd love to chat with you! Please say hi on our discord or over email.
Until next time 👋
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.