What is horizontal sharding?
A basic overview of horizontal sharding. What is it and what are the challenges?
By:
Joan EdwardsPublished:
Reading time:
10 min readWant to grasp a complex concept in the time it takes to brew your morning coffee? In our XataByte: 3-minute byte-sized read series we offer concise explanations to help you unravel intricate database concepts without the time commitment. Today's reading is a bit on the longer side; we're looking at horizontal sharding.
Recently, while wandering through the narrow aisles of a small comic store brimming with pop culture relics, I came across an interesting find. Hidden amongst a varied assortment of DC and Marvel comics, were shelves dedicated to the "Jodoverse" - a series of comics created by Alejandro Jodorowsky. With the spines showing slight signs of age, I remarked to the store owner about the find and asked for a specific issue. Without resorting to a system, ledger, or anything, he quickly scanned the shelves and in a matter of milliseconds found exactly what I asked for with no hassle. I was impressed to see that his collection was organized by genre, collaborator, publication year as well as story arc!
The store owner's organizational strategy allowed him to quickly access comics. His store was divided into different sections; each section was like a mini comic store specializing in a particular category. For example, if you were looking for a 90s Jodorowsky comic created in collaboration with a particular artist, you'd first go to the section dedicated to Jodorowsky's works, find a specific area for collaborations, and then narrow your search down to the shelves tagged with the 90s. This setup, where each 'mini-store' or section held a distinct subset of the entire collection, mirrors the concept of horizontal sharding in databases, where data is split into manageable parts based on specific keys for more efficient access and retrieval.
Just as the comics are grouped and allocated to specific shelves based on various attributes, horizontal sharding distributes rows of a database across multiple locations, or "shards", based on specific key attributes. This method not only ensures quick access but also optimizes storage and performance. The store owner knew exactly where each comic belonged; the same with horizontal sharding which ensures that every piece of data finds its right place in a database system.
What is Sharding
Sharding is a database design technique where data is split across multiple servers, or "shards", each holding a portion of the data. Think of it like the shop mentioned above: instead of having everything jumbled together, the shop is organized into sections, with each section (or "shard") holding a specific category of comics. This structure makes it easier and faster to find a particular item, just as sharding can make databases more efficient by spreading the load across multiple servers.
As data volumes grow exponentially, efficient data management becomes extremely important. That's why sharding is so important, it's one of the techniques employed to maintain the sanity and speed of large databases. So, what are the different types of sharding?
- Vertical sharding: In this approach, different tables or columns are placed on different servers. For example, one server might store names and descriptions, while another might store order histories.
- Horizontal sharding: This is the most common form of sharding. Here, rows of a database table are held separately, rather than splitting by columns. For instance, if you had a database of comics, one shard might contain issue IDs 1 to 1000, while another might hold 1001 to 2000, and so on.
- Range-based sharding: Range-based sharding is a specific method of horizontal sharding where rows are partitioned across shards based on ranges of values of a sharding key. For instance, user IDs 1 to 1000 might be stored on one shard, while user IDs 1001 to 2000 might be on another. In essence, all range-based sharding is horizontal sharding, but not all horizontal sharding is range-based. Other horizontal sharding strategies might involve hashing, directory-based sharding, or even geographically-based sharding. Each strategy has its own advantages and best-use cases.
Other types of sharding exist and include:
Hash-based sharding
A hash function is applied to a key attribute, and the result determines which shard the record goes to. This type of sharding may be good for evenly distributing data, especially when the range or list is not predictable. For example, user IDs can be hashed, and the hash value determines the shard.
Directory-based sharding
A separate lookup service or directory maps each data item to a specific shard. This offers flexibility in sharding and can handle more complex data distribution scenarios. For example, a mapping service can direct user queries to the appropriate shard based on the user's location or preferences.
Geo-sharding
Data is sharded based on geographical locations. This is useful for services that need to reduce latency by locating data closer to the user. For example, social media posts might be stored in a shard located in the same region as the user.
Key-based sharding
This is also known as customer sharding. The sharding is done based on a specific key, such as customer ID or tenant ID. This can be used for multi-tenant applications where data isolation between tenants is crucial. For example, each comic's data can be stored in a separate shard.
Functional sharding
This is sharding based on the function or the type of data. This is suitable for systems where different types of data have vastly different access patterns. For example, this can be used when one shard handles all the transactional data, while another handles logging or archival data.
Sharding comparison example
In horizontal sharding, each shard contains a subset of the rows from the original table, but the structure (columns) remains the same across all shards.
Suppose there is a table of Marvel comic book issues:
Issue ID | Series Title | Character | Release Date | Storyline |
|---|---|---|---|---|
-------- | -------- | -------- | -------- | -------- |
... | ... | ... | ... | ... |
To shard this table horizontally based on the series title, it might look like this:
Shard 1 (Avengers series)
Issue ID | Series Title | Character | Release Date | Storyline |
|---|---|---|---|---|
001 | Avengers | Iron Man | 2018-05-01 | Story A |
002 | Avengers | Thor | 2018-06-01 | Story B |
... | ... | ... | ... | ... |
Shard 2 (Spider-Man series)
Issue ID | Series Title | Character | Release Date | Storyline |
|---|---|---|---|---|
101 | Spider-Man | Spider-Man | 2019-05-01 | Story X |
102 | Spider-Man | Spider-Man | 2019-06-01 | Story Y |
... | ... | ... | ... | ... |
This is represented in the below diagram:
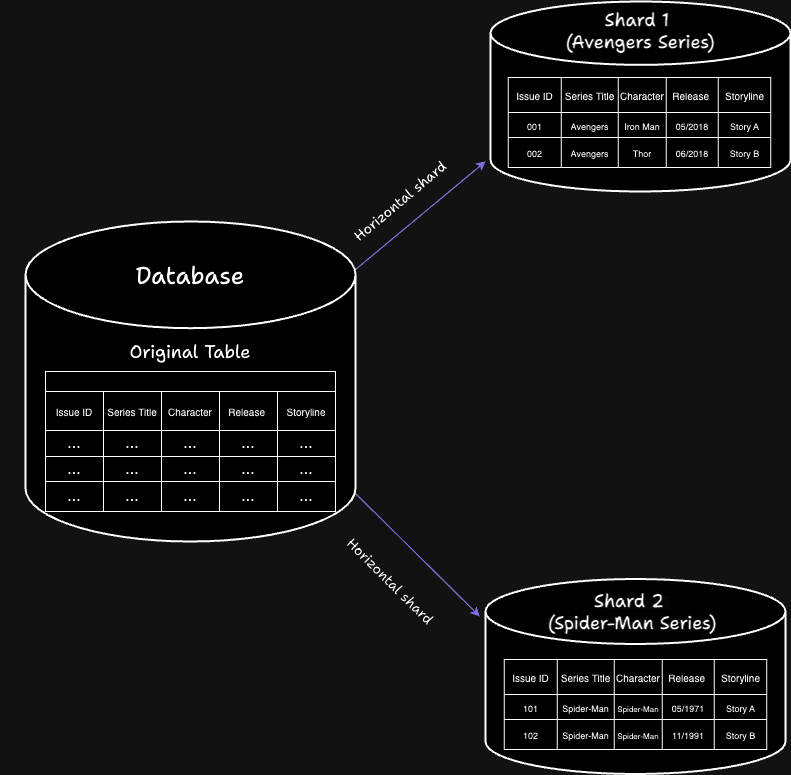
Horizontal sharding example
Conversely, in vertical sharding, each shard contains a subset of the columns from the original table.
Using the same original table structure, if divided into two shards with vertical sharding, it might look something like the following:
Shard 1 (Basic information)
Issue ID | Series Title | Release Date |
|---|---|---|
001 | Avengers | 2018-05-01 |
002 | Spider-Man | 2019-05-01 |
... | ... | ... |
Shard 2 (Content details)
Issue ID | Character | Storyline |
|---|---|---|
001 | Iron Man | Story A |
002 | Spider-Man | Story X |
... | ... | ... |
In horizontal sharding, the data is divided into different rows across shards, but the table structure (columns) is the same. In vertical sharding, the data is divided into different columns across shards, potentially splitting the table into different aspects or types of data.
Why horizontal sharding?
Database sharding is important for several reasons, primarily relating to the scalability, performance, and reliability of database systems, especially when managing massive amounts of data. Here's why it's considered crucial:
- Scalability: As databases grow in size, they can experience slowdowns in query performance, potentially affecting the user experience for applications that depend on them. Sharding helps databases scale out by distributing the data across multiple servers or clusters, enabling them to handle larger workloads and more users.
- Improved performance: Distributing the data across multiple servers means that fewer rows are queried in each shard. This leads to faster query performance since each server has less data to sift through.
- Load balancing: Sharding can distribute the database load evenly across servers. This ensures that no single server becomes a bottleneck, improving the overall performance and responsiveness of the database system.
- Hardware cost efficiency: Instead of scaling up, sharding allows organizations to scale out, adding more servers to the mix. This spreads data across multiple servers, each handling a part of the total data, which lightens the load on individual servers.
- Failover and redundancy: If one shard fails, it won't bring down the entire database. Only the users or transactions tied to that specific shard would be affected, while others can continue operations normally. This can be combined with replication strategies to provide even better fault tolerance.
- Geographical distribution: For global applications, sharding can be done based on geographical considerations. This means that users can be served from a nearby shard, reducing latency and improving application responsiveness.
- Isolation of problematic workloads: If a particular shard starts to experience issues, it can be isolated and managed without affecting the performance of other shards. This isolation can also be good for maintenance and updates.
- Storage management: Different shards can be placed on different storage mediums depending on the access patterns.
Benefits of horizontal sharding
- Handles more data and users: Sharding lets a database grow and handle more data and users.
- Speeds up searches: It's usually quicker to find something in a smaller room than a huge library. Similarly, sharding makes data searches faster.
- Keeps things running: If one shard has a problem, the others keep working.
Challenges of horizontal sharding
- Efficient organization: Think of it as sorting comics by themes and years in the comic store. In database sharding, the challenge is to efficiently organize data across shards, ensuring it's easy to manage and retrieve without getting jumbled up.
- Consistency across sections: Just like maintaining different sections in the store, managing shards can lead to inconsistencies in data retrieval. Users accessing different shards might experience inconsistent query performance, similar to how different sections in the store can offer varying experiences. In sharding, data integrity can become a concern, especially when managing shards independently. Ensuring consistency and integrity across shards is vital to prevent data issues.
- Balancing workload: Imagine one section of the comic store becoming too popular, causing overcrowding, while others remain empty. In sharding, this relates to load balancing. Uneven data distribution can overload some shards, resulting in performance issues, similar to a crowded section causing chaos.
- Handling historical data: Just as we talked about those older comic books, database sharding also involves the challenge of managing historical data. As data accumulates over time, adopting efficient strategies to handle this older information becomes essential to sustain both performance and storage effectiveness.
- Performance bottlenecks: An overcrowded store sections lead to slower service, improper shard distribution can cause performance bottlenecks in database sharding. Ensuring optimal data distribution among shards is essential to avoid these performance issues.
- Complexity management: Similar to the comic store's categorization system, managing multiple shards in a database can be challenging. Implementing and maintaining sharding strategies require careful planning to avoid complexity, in addition to managing costs associated with adding more servers or clusters for sharding can be a challenge. Also, PostgreSQL itself does not provide built-in database sharding in the same way some distributed databases do. However, PostgreSQL supports table partitioning, which can be seen as a form of horizontal sharding at the table level.
Implementing horizontal sharding
Horizontal sharding is not just a method of splitting a database; it's a strategic approach to reorganize how data is stored and accessed. Each phase, from choosing the sharding key to managing data across multiple shards, plays an important role in making the database more scalable and efficient. When done correctly, horizontal sharding can significantly improve a database's performance.
1. Selecting a sharding key
The process starts with choosing a sharding key. This critical step involves identifying a specific data attribute that will dictate how the database is divided into shards. The success of sharding largely depends on this choice, as it affects how easily data can be accessed and managed.
2. Shard creation and management
After determining the sharding key, the next step is to create the actual shards. These are smaller portions of the original database, designed to improve efficiency. However, it's not just about creating these shards; managing them is equally important. This includes tasks like ensuring data is evenly distributed across shards and that each shard is performing well.
3. Data migration
Migrating existing data to the newly created shards is a delicate operation. It requires careful planning to make sure that the data fits well with the chosen sharding key. Proper execution of this step is vital to ensure that data is distributed correctly across the shards.
4. Handling queries across shards
Sometimes, queries need to pull data from multiple shards. Handling these queries efficiently is crucial. The aim is to keep the retrieval process quick and smooth, maintaining the benefits of having a sharded database.
Horizontal sharding in Postgres
To get sharding in PostgreSQL, it usually has to be set up manually. This means creating several Postgres instances where each one acts like a separate piece of the larger database. Deciding how to split the data across these pieces involves choosing a key, like user IDs or locations. This process requires a lot of initial setup and ongoing work to keep it running smoothly.
There are also extensions available that can help with sharding in PostgreSQL. These tools make it easier for PostgreSQL to handle data spread out across different places, making the database more scalable. However, adding sharding, whether by doing it manually or using these tools, makes the database system more complex. It requires careful planning and regular maintenance, especially when dealing with big datasets.
Tips for horizontal sharding
Implementing horizontal sharding in database management involves several key strategies. Below is a summary:
Aspect | Description |
|---|---|
Sharding key | Choose based on frequent data access to evenly split data. |
Balancing data | Keep shards evenly loaded and adjust regularly to prevent overloading. |
Speedy queries | Optimize queries across shards for speed using efficient algorithms. |
Complex transactions | Use protocols to maintain consistent data across all shards. |
Consistency checks | Regularly sync and check data for accuracy across shards. |
Adaptable sharding | Design sharding to easily grow and adapt to changing data needs. |
Managing shards | Monitor shard performance and automate tasks for efficiency. |
Backup plans | Implement strong backup and recovery strategies for each shard. |
Resource management | Smartly plan and use resources, utilizing cloud services for flexibility. |
Shard security | Protect data in each shard with encryption and strict access control. |
And there we go – a basic rundown of horizontal sharding in databases. This overview touches just the tip of the iceberg, but it gives some insight into how horizontal sharding helps in managing large datasets more efficiently.
Let us know what you think. We have a lot more to say on the topic, so reach out to us on Discord or follow us on X | Twitter. We'd love to hear your thoughts, answer your questions, and keep you updated on the latest at Xata.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Introducing Dedicated Clusters for PostgreSQL
We are announcing dedicated clusters, for more scalable and isolated PostgreSQL databases.
Announcing the public beta for dedicated clusters
Today we're excited to open up dedicated clusters to all our customers and some amazing new additions to our serverless Postgres platform.