Create an advanced search engine with PostgreSQL
PostgreSQL provides the necessary building blocks for you to combine and create your own search engine for full-text search. Let's see how far we can take it.
By:
Tudor GolubencoPublished:
Reading time:
9 min read
This is part 1 of a blog mini-series, in which we explore the full-text search functionality in PostgreSQL and investigate how much of the typical search engine functionality we can replicate. In part 2, we'll do a comparison between PostgreSQL's full-text search and Elasticsearch.
Hey, we’re Xata, a Postgres platform with copy-on-write branching, scale-to-zero, and anonymization so you can code and test with real data safely.
If you want to follow along and try out the sample queries (which we recommend; it's more fun that way), the code samples are executed against the Wikipedia Movie Plots data set from Kaggle. To import it, download the CSV file, then create this table:
And import the CSV file like this:
The dataset contains 34,000 movie titles and is about 81 MB in CSV format.
PostgreSQL full-text search primitives
The Postgres approach to full-text search offers building blocks that you can combine to create your own search engine. This is quite flexible but it also means it generally feels lower-level compared to search engines like Elasticsearch, Typesense, or Meilisearch, for which full-text search is the primary use case.
The main building blocks, which we'll cover via examples, are:
- The
tsvectorandtsquerydata types - The match operator
@@to check if atsquerymatches atsvector - Functions to rank each match (
ts_rank,ts_rank_cd) - The GIN index type, an inverted index to efficiently query
tsvector
We'll start by looking at these building blocks and then we'll get into more advanced topics, covering relevancy boosters, typo-tolerance, and faceted search.
tsvector
The tsvector data type stores a sorted list of lexemes. A lexeme is a string, just like a token, but it has been normalized so that different forms of the same word are made. For example, normalization almost always includes folding upper-case letters to lower-case, and often involves removal of suffixes (such as s or ing in English). Here is an example, using the to_tsvector function to parse an English phrase into a tsvector.
As you can see, stop words like “I”, “to” or “an” are removed, because they are too common to be useful for search. The words are normalized and reduced to their root (e.g. “refuse” and “Refusing” are both transformed into “refus”). The punctuation signs are ignored. For each word, the positions in the original phrase are recorded (e.g. “refus” is the 12th and the 13th word in the text) and the weights (which are useful for ranking and we'll discuss later).
In the example above, the transformation rules from words to lexemes are based on the english search configuration. Running the same query with the simple search configuration results in a tsvector that includes all the words as they were found in the text:
As you can see, “refuse” and “refusing” now result in different lexemes. The simple configuration is particularly useful when you have columns that contain labels or tags.
PostgreSQL has built-in configurations for a pretty good set of languages. You can see the list by running:
Notably, however, there is no configuration for CJK (Chinese-Japanese-Korean), which is worth keeping in mind if you need to create a search query in those languages. While the simple configuration should work in practice quite well for unsupported languages, I'm not sure if that is enough for CJK.
tsquery
The tsquery data type is used to represent a normalized query. A tsquery contains search terms, which must be already-normalized lexemes, and may combine multiple terms using AND, OR, NOT, and FOLLOWED BY operators. There are functions like to_tsquery, plainto_tsquery, and websearch_to_tsquery that are helpful in converting user-written text into a proper tsquery, primarily by normalizing words appearing in the text.
To get a feeling of tsquery, let's see a few examples using websearch_to_tsquery:
That is a logical AND, meaning that the document needs to contain both "darth" and "vader" in order to match. You can do logical OR as well:
And you can exclude words:
Also, you can represent phrase searches:
This means: “darth”, followed by “vader”, followed by “son”.
Note, however, that the “the” word is ignored, because it's a stop word as per the english search configuration. This can be an issue on phrases like this:
Oops, almost the entire phrase was lost. Using the simple config gives the expected result:
You can check whether a tsquery matches a tsvector by using the match operator @@.
While the following example doesn't match:
GIN
Now that we've seen tsvector and tsquery at work, let's look at another key building block: the GIN index type is what makes it fast. GIN stands for Generalized Inverted Index. GIN is designed for handling cases where the items to be indexed are composite values, and the queries to be handled by the index need to search for element values that appear within the composite items. This means that GIN can be used for more than just text search, notably for JSON querying.
You can create a GIN index on a set of columns, or you can first create a column of type tsvector, to include all the searchable columns. Something like this:
And then create the actual index:
You can now perform a simple test search like this:
To see the effects of the index, you can compare the timings of the above query with and without the index. The GIN index takes it from over 200 ms to about 4 ms on my computer.
ts_rank
So far, we've seen how ts_vector and ts_query can match search queries. However, for a good search experience, it is important to show the best results first - meaning that the results need to be sorted by relevancy.
Taking it directly from the docs:
PostgreSQL provides two predefined ranking functions, which take into account lexical, proximity, and structural information; that is, they consider how often the query terms appear in the document, how close together the terms are in the document, and how important is the part of the document where they occur. However, the concept of relevancy is vague and very application-specific. Different applications might require additional information for ranking, e.g., document modification time. The built-in ranking functions are only examples. You can write your own ranking functions and/or combine their results with additional factors to fit your specific needs.
The two ranking functions mentioned are ts_rank and ts_rank_cd. The difference between them is that while they both take into account the frequency of the term, ts_rank_cd also takes into account the proximity of matching lexemes to each other.
To use them in a query, you can do something like this:
One thing to note about ts_rank is that it needs to access the search column for each result. This means that if the WHERE condition matches a lot of rows, PostgreSQL needs to visit them all in order to do the ranking, and that can be slow. To exemplify, the above query returns in 5-7 ms on my computer. If I modify the query to do search for darth OR vader, it returns in about 80 ms, because there are now over 1000 matching result that need ranking and sorting.
Relevancy tuning
While relevancy based on word frequency is a good default for the search sorting, quite often the data contains important indicators that are more relevant than simply the frequency.
Here are some examples for a movies dataset:
- Matches in the title should be given higher importance than matches in the description or plot.
- More popular movies can be promoted based on ratings and/or the number of votes they receive.
- Certain categories can be boosted more, considering user preferences. For instance, if a particular user enjoys comedies, those movies can be given a higher priority.
- When ranking search results, newer titles can be considered more relevant than very old titles.
This is why dedicated search engines typically offer ways to use different columns or fields to influence the ranking. Here are example tuning guides from Elastic, Typesense, and Meilisearch.
If you want a visual demo of the impact of relevancy tuning, here is a quick 4 minutes video about it:
Numeric, date, and exact value boosters
While Postgres doesn't have direct support for boosting based on other columns, the rank is ultimately just a sort expression, so you can add your own signals to it.
For example, if you want to add a boost for the number of votes, you can do something like this:
The logarithm is there to smoothen the impact, and the 0.01 factor brings the booster to a comparable scale with the ranking score.
You can also design more complex boosters, for example, boost by the rating, but only if the ranking has a certain number of votes. To do this, you can create a function like this:
And use it like this:
Let's take another example. Say we want to boost the ranking of comedies. You can create a valueBooster function that looks like this:
The function returns a factor if the column matches a particular value and 0 instead. Use it in a query like this:
Column weights
Remember when we talked about the tsvector lexemes and that they can have weights attached? Postgres supports 4 weights, named A, B, C, and D. A is the biggest weight while D is the lowest and the default. You can control the weights via the setweight function which you would typically call when building the tsvector column:
Let's see the effects of this. Without setweight, a search for jedi returns:
And with the setweight on the title column:
Note how the movie titles with “jedi” in their name have jumped to the top of the list, and their rank has increased.
It's worth pointing out that having only four weight “classes” is somewhat limiting, and that they need to be applied when computing the tsvector.
Typo-tolerance / fuzzy search
PostgreSQL doesn't support fuzzy search or typo-tolerance directly, when using tsvector and tsquery. However, working on the assumptions that the typo is in the query part, we can implement the following idea:
- index all lexemes from the content in a separate table
- for each word in the query, use similarity or Levenshtein distance to search in this table
- modify the query to include any words that are found
- perform the search
Here is how it works. First, use ts_stats to get all words in a materialized view:
In the above we use the Levenshtein distance because that's what search engines like Elasticsearch use for fuzzy search.
Once you have the candidate list of words, you need to adjust the query include them all.
Faceted search
Faceted search is popular especially on e-commerce sites because it helps customers to iteratively narrow their search. Here is an example from amazon.com:
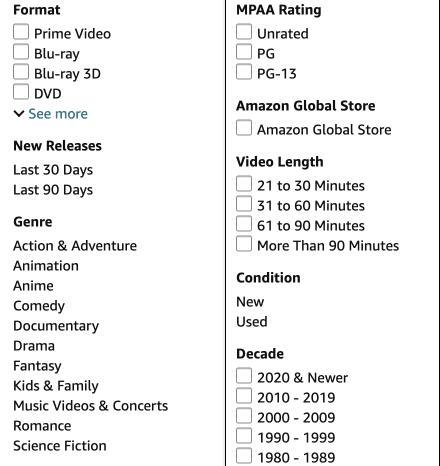
The above can implemented by manually defining categories and then adding them as WHERE conditions to the search. Another approach is to create the categories algorithmically based on the existing data. For example, you can use the following to create a “Decade” facet:
This also provides counts of matches for each decade, which you can display in brackets.
If you want to get multiple facets in a single query, you can combine them, for example, by using CTEs:
The above should work quite well on small to medium data sets, however it can become slow on very large data sets.
Conclusion
We've seen the PostgreSQL full-text search primitives, and how we can combine them to create a pretty advanced full-text search engine, which also happens to support things like joins and ACID transactions. In other words, it has functionality that the other search engines typically don't have.
There are more advanced search topics that would be worth covering in detail:
- suggesters / auto-complete
- exact phrase matching
- hybrid search (semantic + keyword) by combining with pg-vector
Each of these would be worth their own blog post, but by now you should have an intuitive feeling about them: they are quite possible using PostgreSQL, but they require you to do the work of combining the primitives and in some cases the performance might suffer on very large datasets.
In part 2, we'll make a detailed comparison with Elasticsearch, looking to answer the question on when is it worth it to implement search into PostgreSQL versus adding Elasticsearch to your infrastructure and syncing the data. If you want to be notified when this gets published, you can follow us on Twitter or join our Discord.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Full-text search engine with PostgreSQL (part 2): Postgres vs Elasticsearch
Using PostgreSQL as a full-text search engine is tempting because it requires less infrastructure. But is its set of search-related features enough to compete with the Lucene based alternatives?