How to perform Postgres schema changes in production with zero downtime
Schema migrations are a pain. In this workshop we review the problem space and tools available to make reversible schema changes in production with zero downtime.
By:
Alex FrancoeurPublished:
Reading time:
8 min readSchema migrations are a pain. They typically require multi-step playbooks to roll out in production and migrate your data over. In this workshop we review the problem space and tools available to make reversible schema changes in production with zero downtime.
Common pitfalls to rolling out schema changes
There are a number of gotchas we typically see folks run into when trying to roll out schema changes in a production environment where downtime is simply not acceptable.
Additive-only changes and schema debt
If you’ve ever worked with a production database, I’m sure you’ve run into this one. We’ve interviewed many developers and architects about schema migrations and the one thing they’ll all admit is that they’d rather add columns than remove them. It’s the safe play, destructive changes can be complex, but things can get out of hand very quickly. A single column can very quickly turn into multiple versions with different variations.
This pattern comes from fear of breaking the application, which is fair. Though at the end of the day, having a table with hundreds of columns can lead to a few issues. You can end up with performance implications returning certain queries, having long living compatibility code in your application and general confusion for anyone new to the database.
The locking minefield
If you aren’t familiar with Postgres, locking is a way to control concurrent access to data in tables. Locks are used pretty heavily when modifying your schema and there are many types of different locks available in Postgres.
As an example, any ALTER TABLE statements will require the ACCESS EXCLUSIVE lock which conflicts with all other lock types. Meaning, most changes to your table essentially make it inaccessible for writes. When talking about production applications, the general goal is to reduce the time during which Postgres tables are locked as much as possible. Unless you have the same exact data in your staging or preview environments as you do production, realistic locking scenarios can be relatively hard to test for.
Deploying application changes
Now, this part is always fun. The ordering of deployment for changes in your application. Do you deploy your application first? Your database first? Or both at the exact same atomic time? There’s no completely right answer, but there’s definitely wrong answers and a lot of it depends on your application and the changes being made.

Ensuring data consistency between the changes, avoiding schema drift and backfilling the appropriate data correctly are some of the complexities that can lead to downtime. That’s why the more complex the application, the more complex the deployment process ends up being for database changes.
Rolling back your changes
If you have downtime because of changes made to your database, what do you do? Rollback of course. Rolling back your schema changes in production is probably the only thing scarier than rolling them out in the first place. If your schema changes were a long multi-step process, you can assume that rolling those changes back will be even more difficult.
Because of this difficulty, rollbacks typically aren’t tested before deploying to production. In the best case scenario you have a short unplanned maintenance window. Depending on the size or complexity of the data, it could take hours to revert.
Planning, testing & communication
And of course, no matter how much you prepare human error is always a possibility. Large scale applications typically have large organizations with multiple stakeholders and end users. Which means, downtime is as much of a people problem as anything else. Having good documentation, a collaborative team, likely some process and ensuring everyone in the organization is on the same page is an important piece of the puzzle.
Production rollout strategies
There are some battle-tested ways to roll out schema changes in production environments. Here's a quick overview of some strategies we see out in the wild.
Version controlled SQL scripts
Relational databases have been around for a while, and some practices have stood the test of time. It is not uncommon for an entire database schema history to be stored in a widely accessible folder, with well ordered SQL files and a manual, well documented process to roll out changes. Just don't let your intern near it 😉
This is a trusted solution for keeping a history, making changes and quickly being able to rebuild your database. Putting these files behind version control systems like git / GitHub allow for some change management process. While maybe not for everyone, this is good enough for more businesses than you’d think -- and at a variety of scales.
Frameworks & ORMs
There are generally two ways to deploy your database alongside your application. Coupling the two together, or decoupling them. When your application is coupled together with your database, you typically see an ORM or framework in use.
ORMs like Prisma or Drizzle and frameworks like Django, Ruby on Rails or Laravel will not just generate schema migrations for your application, but deploy the changes at the same time. This works well at a smaller scale, but as you grow there end up being a number of downsides ranging from collaboration features to having less control over the schema migrations themselves.
Expand & contract
The expand and contract strategy, also known as parallel change, is a pattern used to migrate your schemas with zero downtime. This pattern is usually seen in decoupled architectures and is proven to work well at scale.
It works by applying changes in a specific series of steps that add in the new schema and data, with the application aware of both schemas for a given period of time. Then, deleting the old schema after the data has been backfilled. This approach is backwards compatible and reversible and a pattern we see used regularly in modern applications.
Application specific processes
Every application is unique in one way or another. As applications grow in complexity, so do their schema migrations. You may find yourself writing pages and pages of documentation, but for good reason. Micro-managing schema migrations means that petabytes of customer data are safe and your business continues to run smoothly.
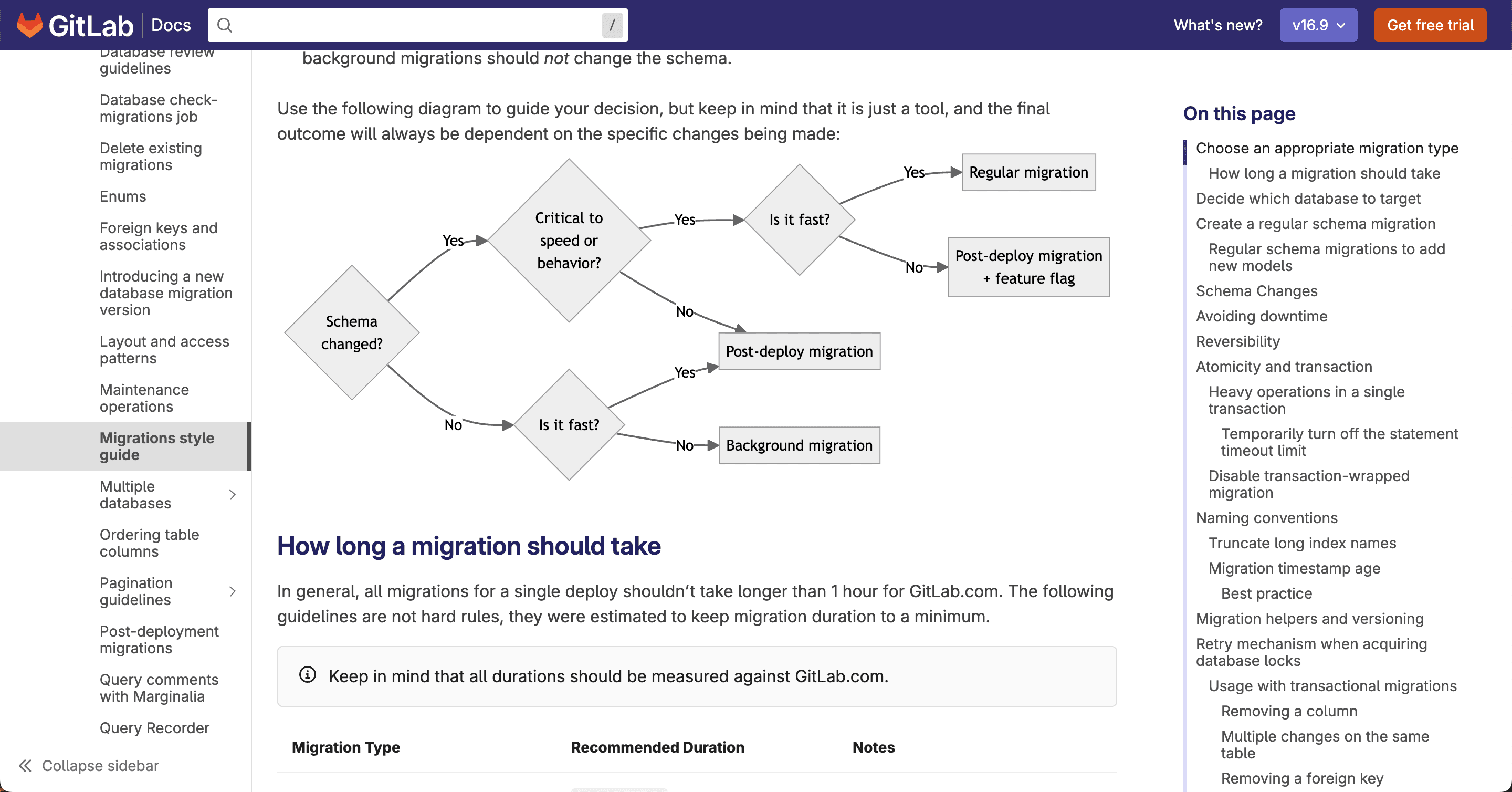
GitLab migration guide
In larger organizations like this, schema migrations typically are categorized by type and smaller and more frequent changes are preferred. There may also be processes in place for feature flags or canary deployments for multi-tenant environments. Generally, I’d say whatever approach you take – good documentation is always a welcome addition. This GitLab documentation is a great example of how organizations tend to handle schema migrations at scale.
Planned downtime
There’s always the possibility that downtime is acceptable for your application and business. Maybe your audience is only around during business hours or you have regular planned maintenance every month. In which case, you can take more of a “big bang” approach. Multi-step process or intimately integrated ORMs simply aren’t necessary to avoid downtime, giving you more time to get creative with your maintenance window page.
Tools available for schema migrations
When you start seriously considering more destructive changes to your schema, third party tooling becomes more of a necessity to keep track of the changes, version them and perform the migrations. Since this problem has been around for a while, there are a variety of tools. We won't go into details for each one, but some solutions have been around for nearly two decades and others have popped up in the last few years.
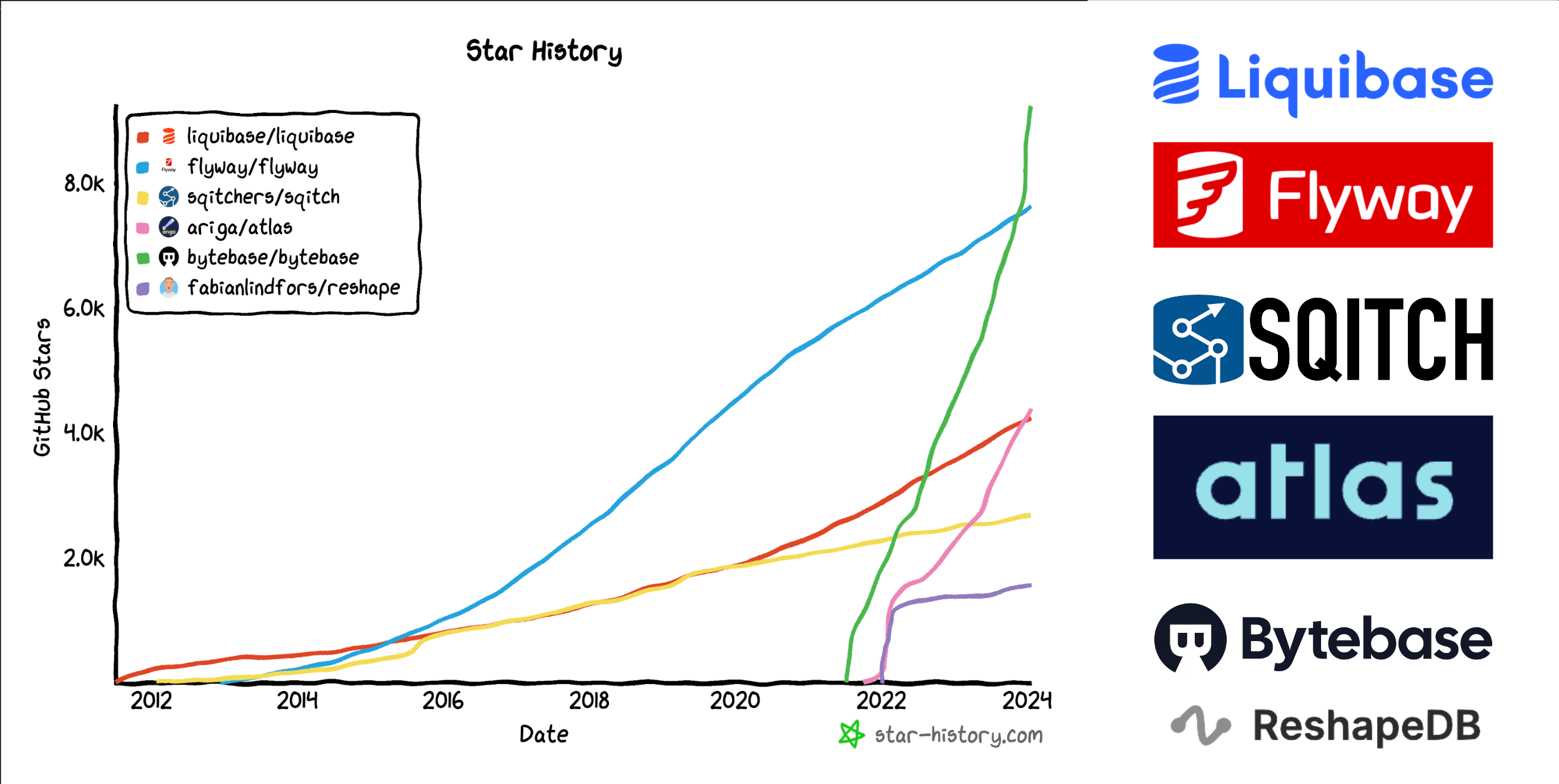
Tools for schema migrations
Both Liquibase and Flyway have been in this space for some time, Liquibase having been here the longest since 2006. Both of these offerings have a free open source solution. That being said, there are numerous features ranging from rollbacks to schema diffs that are gated at the paid tier. Liquibase is more geared towards enterprise use cases, and Flyway being a bit more developer oriented. Both solutions can use SQL to write migration scripts (though Liquibase supports other formats – YAML, XML, JSON.) and support a wide variety of databases.
Sqitch is interesting because it has positioned itself as a standalone change management system. It is unopinionated about your application framework, database engine or development environment. Unlike liquibase or flyway, there is no need to number or name your migrations a certain way. Sqitch handles this for you. It’s a unique solution that is aims to make it easy to integrate into your existing environment.
Atlas and Bytebase are very much the new kids on the block and lean into developer experience and database as code. Both have open source and cloud offerings and aim to do much more than schema migrations, supporting multiple databases.
Last but not least is Reshape. This is a relatively new open source and experimental tool that provides a novel way for handling schema migrations. Though unlike these other tools, it doesn’t support multiple databases and is only for Postgres. This means it can take advantage of capabilities specific to Postgres more-so than other solutions. Reshape inspired the next tools we'll dive into: pgroll.
Introducing pgroll: zero-downtime, reversible schema migrations for Postgres
At Xata, we recently sought to tackle this problem with a brand new solution, pgroll. pgroll is an open source command-line tool that offers safe and reversible schema migrations for PostgreSQL by serving multiple schema versions simultaneously. It takes care of the complex migration operations to ensure that client applications continue working while the database schema is being updated. This includes ensuring changes are applied without locking the database, and that both old and new schema versions work simultaneously. This removes risks related to schema migrations, and greatly simplifies client application rollout, also allowing for instant rollbacks.
If you're interested in learning more about why we built this solution, how it's different and demo of how it works -- check out this video from lead engineer Andrew Farries below.
Coming soon to Xata
We are in the process of integrating pgroll directly to Xata. This will open the door to many more migrations that can be rolled out in production, with zero downtime.
Tools for schema migrations
Let us know what you think
We'd love to hear from you if you have any feedback on the problem and our brand new solution, pgroll. If you would like to know more about pgroll or Xata in general, feel free to reach out to us in Discord or follow us on X | Twitter.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
How pgroll works under the hood
Learn how pgroll implements zero-downtime schema changes by exploring an example.
Schema changes and the power of expand-contract with pgroll
A pgconf EU talk recap covering how the expand-contract pattern and pgroll enable zero-downtime schema changes and rollbacks.
Powering up schema migrations with pgroll
Integrating pgroll into Xata to provide zero-downtime, reversible schema migrations.
Postgres schema changes are still a PITA
Table locking, downtime risks, long running migrations, manual steps, difficult rollbacks. Is there a better way?