Powering up schema migrations with pgroll
Integrating pgroll into Xata to provide zero-downtime, reversible schema migrations.
By:
Emily MorganPublished:
Reading time:
6 min readIn a typical development workflow, schema changes to an application’s database can take a long time, and rollbacks are often error prone. That’s why we’ve created pgroll - an open source Postgres tool for zero-downtime and reversible schema migrations.
Starting today with our public beta, pgroll is now the underlying technology used behind our schema change APIs for the Xata web application, CLI and SDK. Using pgroll behind the scenes allows us to dogfood our product, as well as de-risk migrations by providing a standardized API. It also means that users will have more fine grained control over their databases.
New features
Users have consistently voiced a number of pain points, from adding constraints, to column editing, to having more flexible schemas during the initial data modeling phases. Using the capabilities pgroll provides on top of Postgres allows us to address a lot of these issues.
Xata users will now notice some new features such as:
- The ability to add and remove constraints after creating columns
- For example, modifying a column to be not null or unique after a column has been created and contains data is now possible.
- The ability to create columns that are not nullable without defaults
- These columns will be populated with a “zero” column value depending on the column’s type.
- The ability to run raw arbitrary SQL migrations on the underlying Postgres database
- You can now create column types outside of rich Xata types, as well as constraints, foreign keys, and other Postgres native supported objects.
Enabling direct Postgres access
In order to access the new features users must first do two things.
The first is to flip the feature flag and enable direct access to Postgres for your workspace.
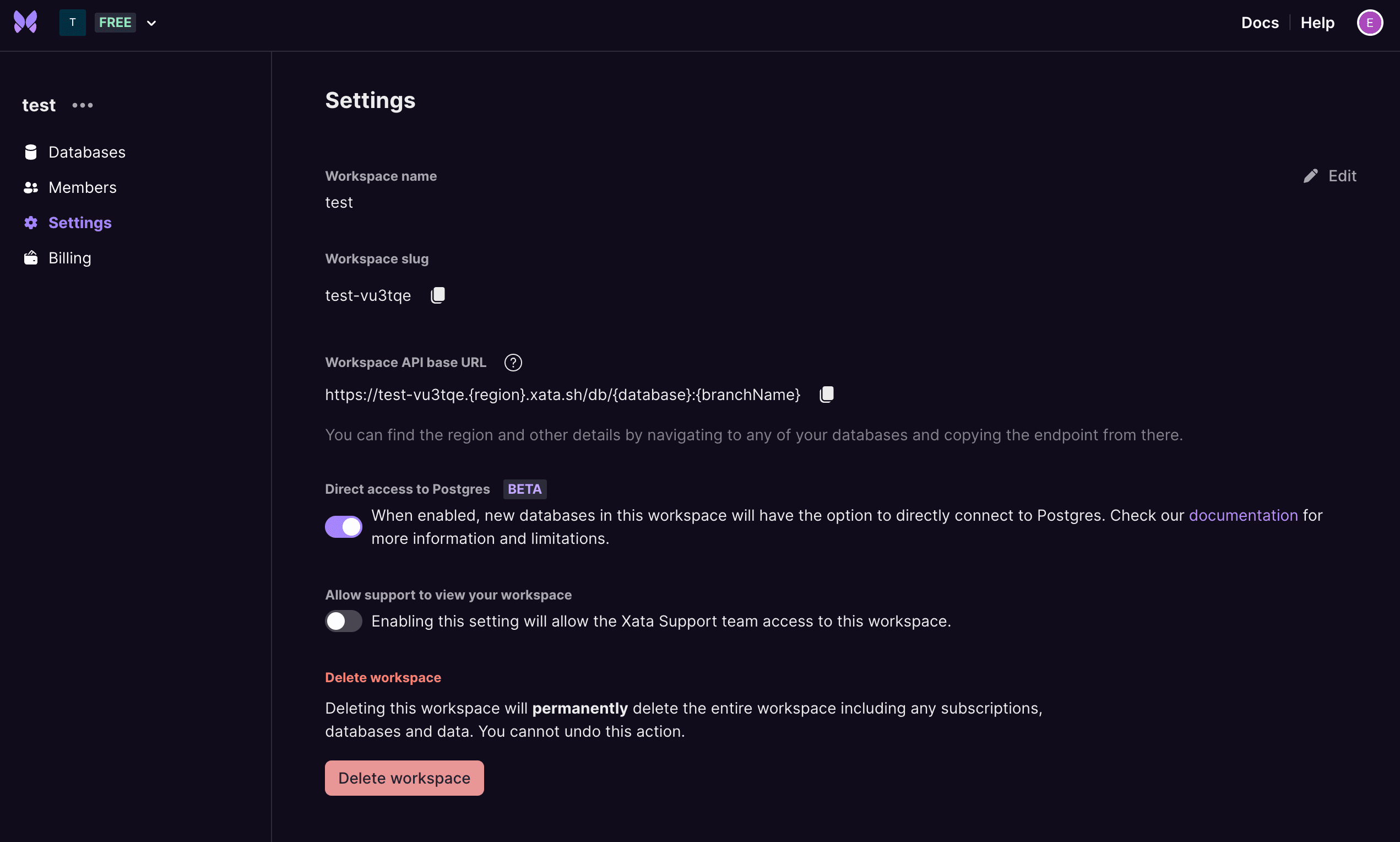
Enable direct access for your workspace
The second is to enable direct access to Postgres when creating a new database.
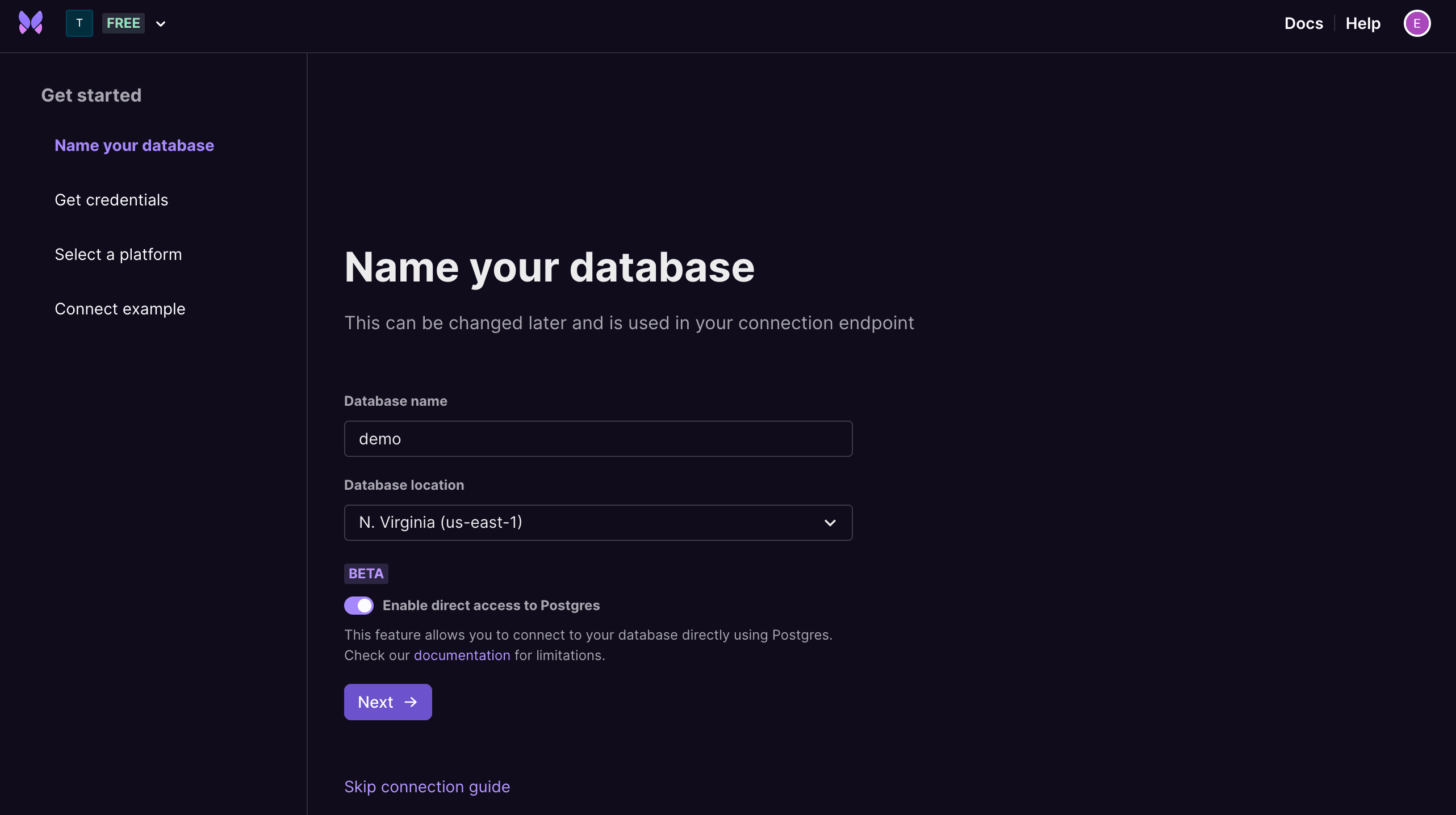
Enable direct access for your database
Once the database is created, you're all set. You now have a brand new Postgres database with pgroll enabled 🐘
A more powerful migration experience
When using a Postgres enabled database, there will be new options to edit columns on the Table and Schema views.
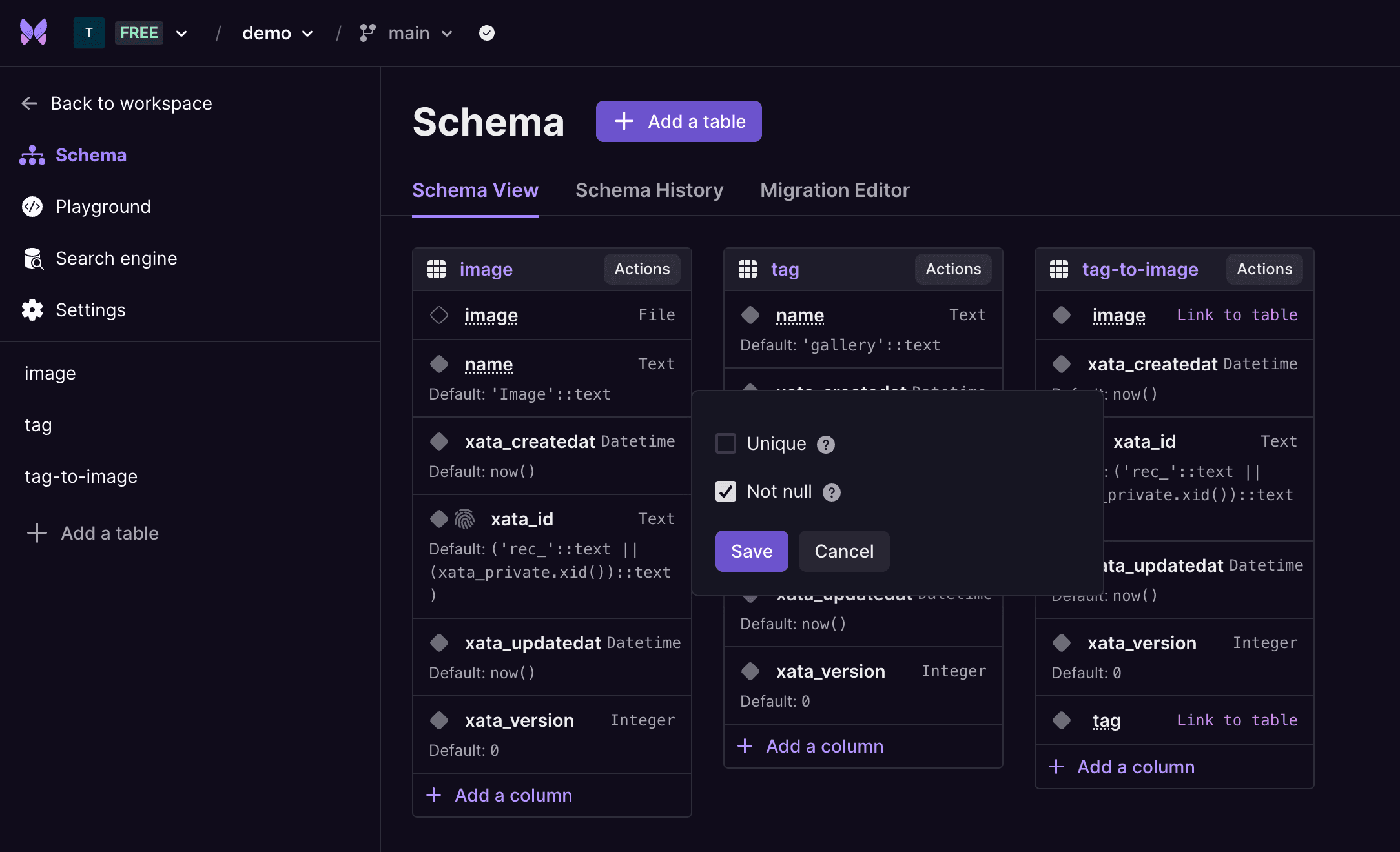
New edit column functionality
There will also be a new tab called Migration Editor on the Schema view page. Users can now run numerous arbitrary migrations with type safe completions, from additive changes like creating new columns, to destructive changes like changing column types. All operations supported can be found here with a long list of examples here.
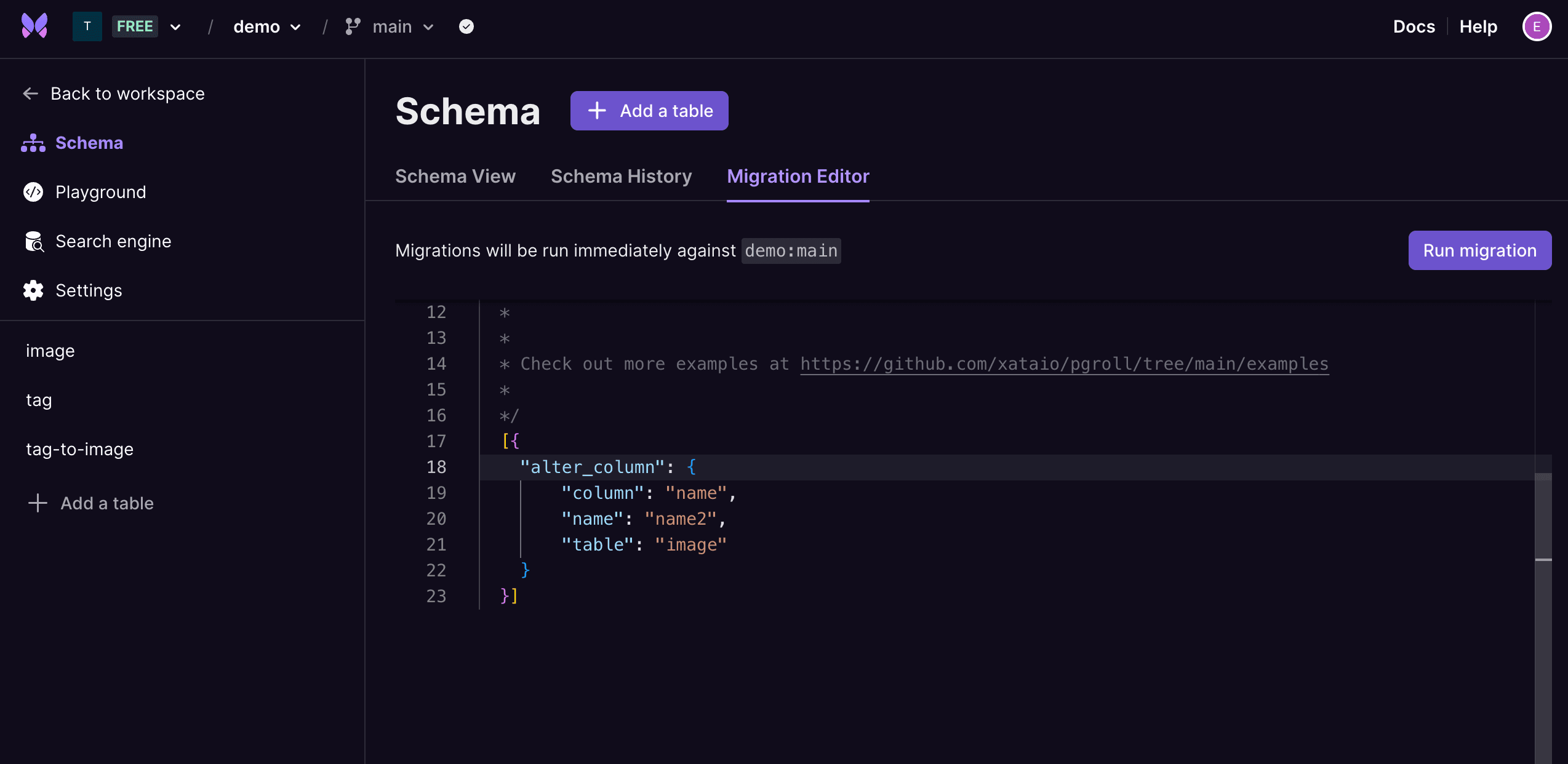
New Migration Editor
We've also introduced a new Schema History tab that contains a list of all the migration operations that have been run against a the user’s database schema up until now. Information such as the migration status, migration type (whether it was run using pgroll or directly with SQL), and contents can be viewed by clicking into it. Every single change made to the database is listed here and can be used for auditing purposes.
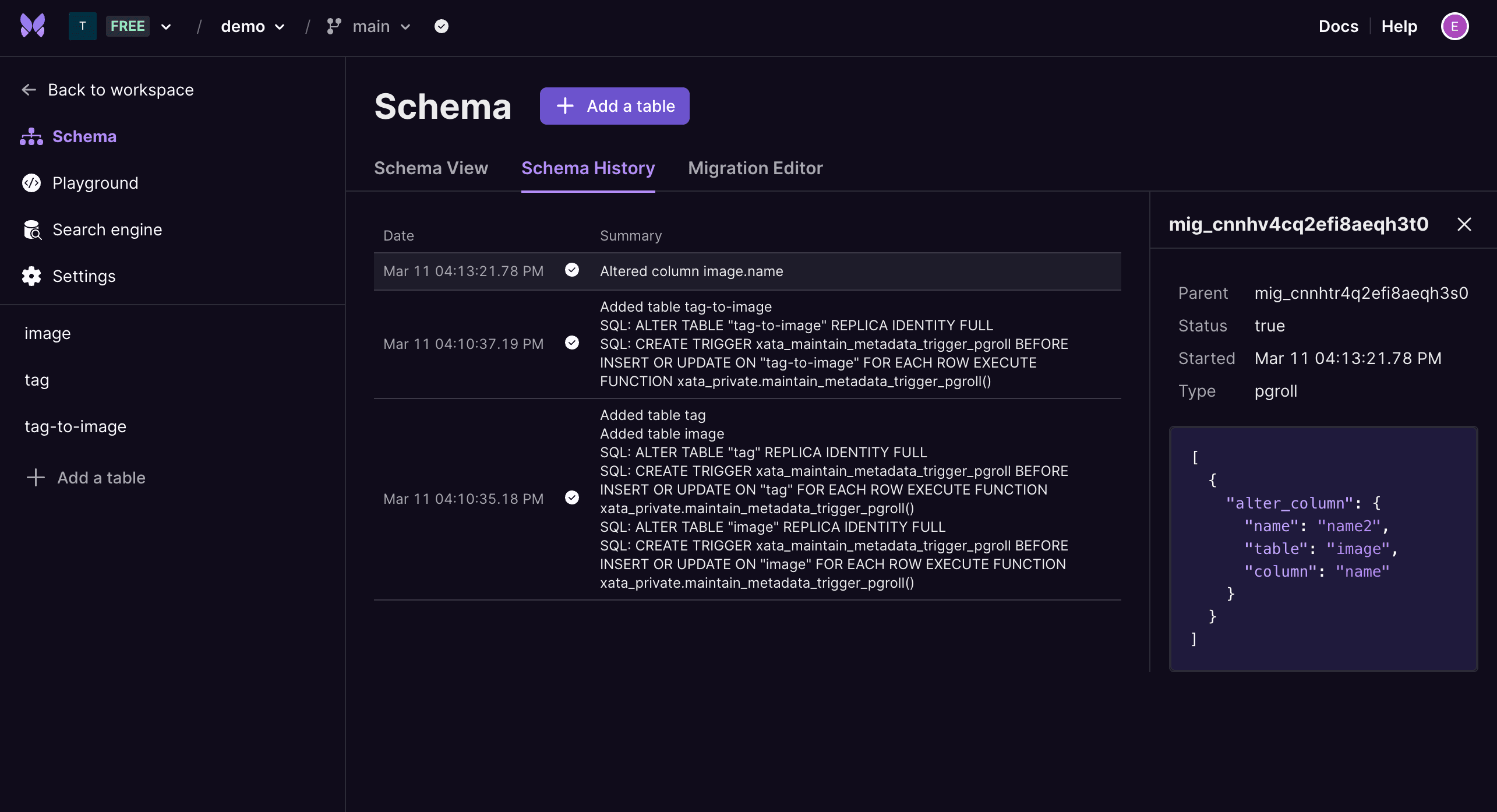
New Schema History tab
SDK and CLI changes
For users that have not enabled this feature flag for their workspace, there will be no changes to the existing APIs when using our CLI and SDK.
For users that have enabled this functionality, they will need to update to the latest CLI and SDK version and create a new, empty database with Postgres enabled. We do not currently support enabling direct Postgres access on existing databases. Users will then have to run xata db pull .
The only things that change for these new Postgres enabled databases in terms of our API are primary key names and internal meta data field names. The id field has been renamed to xata_id, and xata.createdAt, xata.updatedAt, and xata.version fields have been renamed to xata_createdat, xata_updatedat, and xata_version.
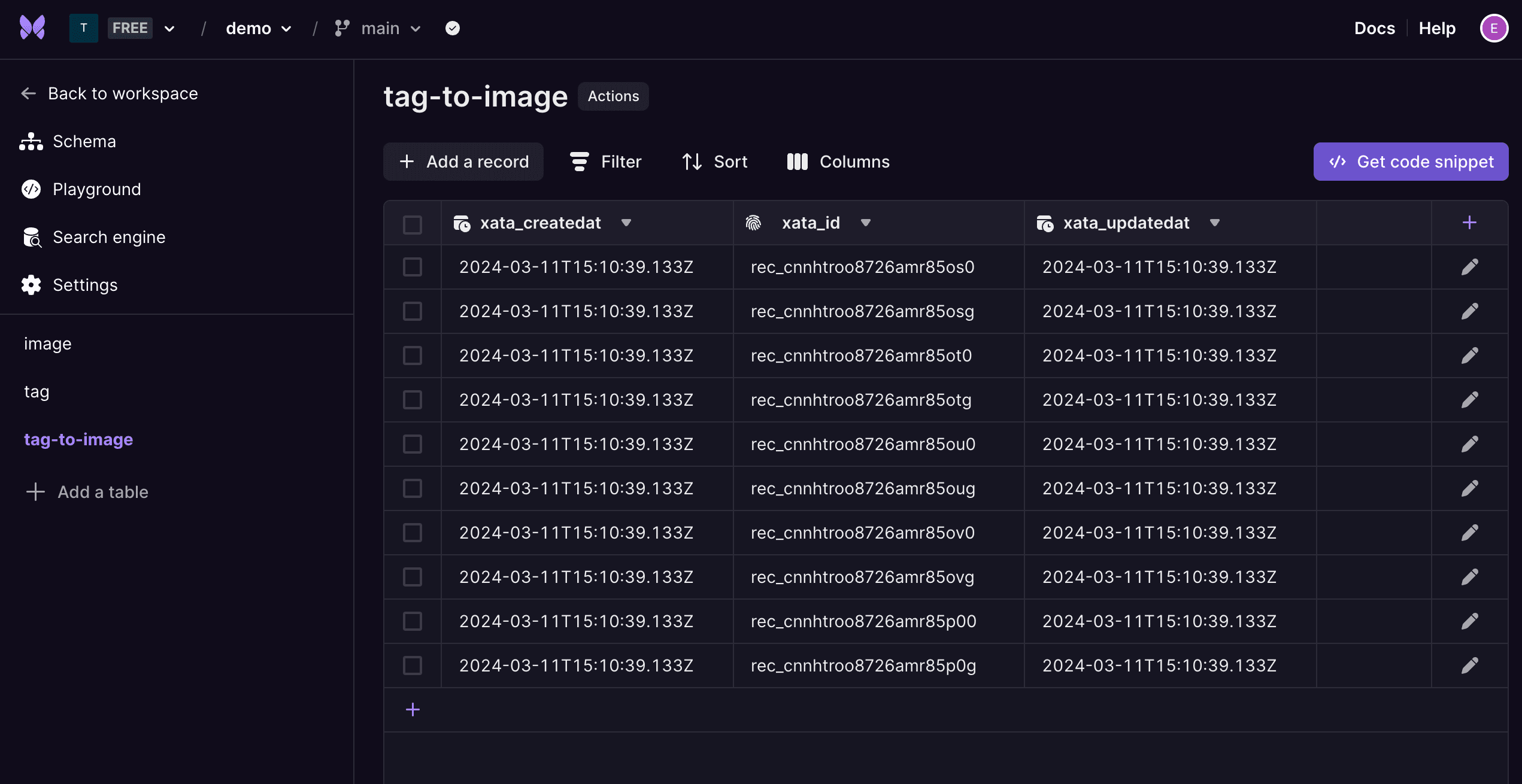
New internal column names
Technical challenges
Integrating pgroll within our web application and developer packages has posed some interesting technical challenges. Some of the main challenges we encountered were:
- Backwards compatibility with existing migration workflows
- We wanted to continue to support databases that did not have direct access to Postgres enabled so as not to break existing users’ queries. In order to maintain backwards compatibility for existing databases, we had to figure out some way to communicate to the backend whether we wanted to use the new APIs or the old ones. We settled on a combination of feature flags and request headers.
- Support for arbitrary Postgres-native column types
- Prior to the integration, there was a relatively small list of column types that we knew a column could be. Arbitrary SQL migrations over pgroll greatly expanded that list as users could create their own Postgres native column types. We had to do a lot of mapping between these new native Postgres types and the known Xata column types, as our web application has custom React components for displaying, editing, and adding data according to a column’s Xata type. Some of these new Postgres native types could not be mapped into our existing Xata types as they do not work with our Data API, so figuring that out and handling those cases gracefully was a challenge.
- Detecting when a migration is complete
- pgroll does not allow for referencing items created in previous operations in subsequent operations within the same migration. This means that running an
alter_columnoperation after anadd_columnoperation, or running arename_constraintoperation (requires a table name) after arename_tableoperation within the same migration request is not currently possible. This is due to the fact that the first operation in the list is guaranteed to compete before the second operation completes, but the first operation is not guaranteed to complete before the second operation starts. Since the backend provides an asynchronousapplyendpoint which responds with ajobId, we decided that the frontend would use the returnedjobIdas input to a second new endpoint calledstatuswhich would return the state of that migration. The frontend polls the status endpoint until the migration in question succeeds or fails before moving forward with dependent migrations.
Path to General Availability
While this is a very exciting release for us, there's still a bit more we need to do before getting this integration over the finish line.
The magic ✨ of pgroll is that it provides the ability to write to two versions of the schema at the same time while your application migrates over to the new schema. For our initial release, this functionality didn't make the cut and instead we wanted to focus on unlocking new types of migrations for our users. Before we GA this integration and approach to schema migrations, we'll provide support for multiple schemas.
At the moment, complex migrations require JSON definition in the schema editor. As we start to see adoption of these new Postgres databases and the types of migrations our users do more frequently, we'll prioritize more form based and developer friendly ways to define them.
There are still some limitations of frameworks and ORMs we want pgroll to work with such as Django, Prisma and Drizzle. Full functionality for at least these sets of tools is part of our goals for GA.
In addition to these new features, there is also some work that we need to do on the backend to migrate all existing databases, provide more context around the status of migrations and enhance our existing migration workflows. Needless to say, we're just getting started but cannot wait for what lies ahead.
Learn more and try it out today
Want to learn more about the development of this service, the folks that built it and watch a quick demo of it in action? Check out our latest meet the makers session here.
Pop into Discord and say hi if you'd like to dig in further 👋
Interested in trying out for yourself? Sign up today! Happy building 🦋
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Introducing pgroll: zero-downtime, reversible, schema migrations for Postgres
We are excited to ship the first version of pgroll, a command line tool that offers safe and reversible schema migrations for PostgreSQL
Schema changes and the power of expand-contract with pgroll
A pgconf EU talk recap covering how the expand-contract pattern and pgroll enable zero-downtime schema changes and rollbacks.
How pgroll works under the hood
Learn how pgroll implements zero-downtime schema changes by exploring an example.