pgstream v1.0.0: Stateless schema change replication
A major architectural milestone that removes schema logs and simplifies how pgstream captures and replicates Postgres schema changes
By:
Esther Minano SanzPublished:
Reading time:
6 min readToday we’re excited to announce pgstream v1.0.0! 🚀
This major release marks an important milestone and is centered around a fundamental architectural change: stateless schema change replication, something that’s been on our radar for some time. 📡
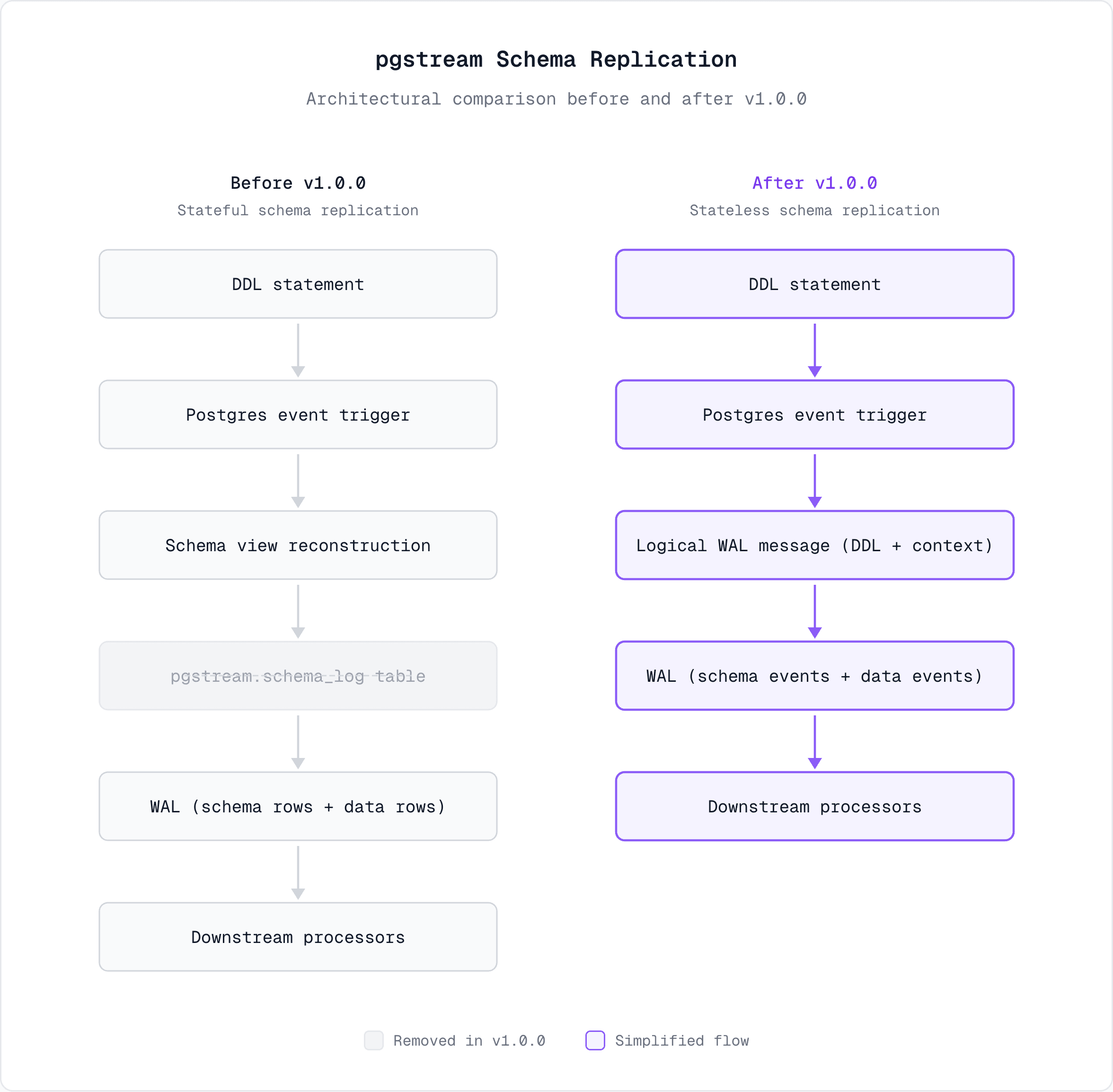
pgstream has supported schema change replication for a long time, but until now it relied on state on the source database to represent schema history. With v1.0.0, we’ve removed that dependency entirely. Schema changes are now captured, enriched, and replicated without storing schema state in the source database, while preserving the same strong ordering guarantees between schema and data changes.
Let’s take a closer look at what changed, why it matters, and how the new model works.
💡pgstream is an open source CDC tool built around Postgres logical replication. It supports DDL changes, snapshots, continuous replication and column level transformations for data anonymization.
pgstream can stream changes to multiple downstream targets, including Postgres, OpenSearch, Elasticsearch, Kafka, and webhooks. Learn more here.
🔄 From schema log replication to direct WAL DDL events
To understand what makes pgstream v1.0.0 different, it’s worth briefly looking at how schema change replication worked before.
The previous approach
- A custom pgstream event trigger relied on Postgres helper functions to identify schema changes:
pg_event_trigger_dropped_objectsforDROPcommandspg_event_trigger_ddl_commandsfor all other DDL
- That trigger:
- Queried Postgres system catalogs,
- Reconstructed a partial schema view,
- And inserted a row with that schema view into a
pgstream.schema_logtable.
- That schema log row was then replicated via WAL as a regular data change, alongside normal table updates.
This design had one important property: schema and data changes were correctly ordered, because everything flowed through the WAL.
However, it also introduced several drawbacks:
- The schema view had to be manually maintained and kept in sync with Postgres internals.
- Only a partial representation of the schema could be maintained, as it had to be reconstructed from system catalogs rather than derived directly from the DDL. It covered:
- Table information (columns, indexes, sequences)
- Materialized views
- Every schema change required an extra indirection step.
- DDL → schema view → table row → WAL→ downstream processors
- Schema diffs had to be computed by comparing multiple schema log entries.
In short, schema replication worked, but at the cost of complexity and fragility.
Example: a pgstream.schema_log row
Below is an example of what a single row in the pgstream.schema_log table looked like. Each row represented a materialized snapshot of (part of) the schema at a given point in time.
Row metadata:
Schema payload (stored as JSONB):
The new approach in v1.0.0
With pgstream v1.0.0, that intermediate layer is gone.
Instead of materializing schema state into a table, pgstream now:
- Uses a custom pgstream event trigger to capture DDL changes using the same event trigger functions as before,
- Builds a message attaching the DDL query and relevant context,
- Emits the messages directly into the WAL using
pg_logical_emit_message, - And lets downstream processors interpret the change directly from the event itself.
There is no schema log table, no reconstructed schema view and no source database schema state to maintain.
Why this matters
This shift has a few important consequences:
- All DDL statements are replicated, not just a curated subset
This is especially valuable for Postgres targets, which can now replay full DDL faithfully. - No schema view to maintain
pgstream no longer needs to mirror Postgres’s catalog structure or track schema shape over time. - Less indirection, fewer failure modes
Schema changes go straight from DDL execution → WAL → downstream processing. - Schema replication becomes event-driven, not state-driven
The DDL itself is the source of truth, not a derived representation. - Delta driven schema processing (no state comparison)
Rather than computing the schema diff, the DDL itself represents the schema delta (e.g.ALTER TABLE … ADD COLUMN).
In other words, pgstream no longer tries to reconstruct schema changes, it simply replicates them as events, exactly as they occurred. Schema evolution becomes fully declarative and event-driven.
📸 Schema snapshots: one unified approach
Schema snapshots are another area where pgstream v1.0.0 simplifies the architecture by removing duplication and special cases.
How snapshots worked before
Previously, pgstream used two different mechanisms to produce schema snapshots:
- For Postgres targets, schema snapshots relied on
pg_dump/pg_restore. - For non Postgres targets, pgstream constructed a partial schema view, inserted it into the
pgstream.schema_logtable, and relied on WAL-based replication to propagate that row downstream.
This resulted in separate code paths and behavior depending on the target type, on top of the existing limitations around partial schema representation and ongoing maintenance.
The unified snapshot model in v1.0.0
With pgstream v1.0.0, schema snapshots now follow a single, unified path for all targets, built entirely around pg_dump.
pg_dumpis always used to extract a complete and accurate schema definition.- Postgres targets apply the schema using
pg_restorefor native compatibility. - Non Postgres targets parse the
pg_dumpoutput and convert the DDL statements into WAL-style DDL events, equivalent to those emitted by the runtime event trigger.
All snapshot DDL events then flow through the same downstream processing pipeline as live schema changes.
By standardizing on pg_dump, pgstream removes the need for schema log based snapshots, eliminates duplicated logic, and produces more complete and consistent schema initialization across all targets.
🔍 Search indexer updates (OpenSearch & Elasticsearch)
The move to stateless schema replication also required changes to the search indexer for OpenSearch and Elasticsearch targets, which previously depended on schema log history and a pgstream-managed search index to track schema evolution.
In pgstream v1.0.0, the search indexer removes this dependency entirely, eliminating the pgstream-managed schema index in favor of alias-based field mapping.
- Field aliasing
Index mappings now use aliases to map human-readable table and column names to internal pgstream IDs. - Improved rename handling
- Column renames are handled via aliases, so existing indexed data remains untouched.
- Table renames transfer all column aliases to the new table name.
- More user-friendly queries
Queries use actual table and column names instead of internal identifiers.
This simplifies search indexing, improves rename safety, and aligns the search targets with pgstream stateless, event-driven schema model.
🧹 Upgrading to v1.00
Upgrading to pgstream v1.0.0 mainly involves a small cleanup, as this release removes the schema log mechanism used in earlier versions.
If you’re upgrading from v0.x, you’ll need to:
- Before upgrading, stop pgstream and remove the legacy schema-log migrations using the old version (for example with
pgstream destroy --migrations-only), - Upgrade to pgstream v1.0.0,
- Re-initialize pgstream with the new v1.0.0 migrations,
- Update your configuration to remove any schema log related references.
The full set of steps and commands is documented in the v1.0.0 migration guide.
💜 Community milestone
pgstream recently crossed 1,000 GitHub stars ⭐️, and we want to say thank you.
This milestone reflects the contributions, feedback and real-world usage from the community. Whether you’ve opened an issue, submitted a pull request, or shared your experience, your input has helped shape pgstream.
We’re excited to keep building pgstream in the open and to continue working alongside the community.
Conclusion
pgstream v1.0.0 removes the need to persist or reconstruct schema state in the source database. By emitting schema changes directly into the WAL as logical messages, the DDL itself becomes the source of truth and schema evolution is represented purely as a stream of events.
This shift eliminates schema logs, partial schema views, and state comparison logic, reducing both operational overhead and implementation complexity. Schema changes are now easier to maintain and more faithfully represented downstream.
We’re excited to see how this new architecture enables more reliable replication pipelines and powers the next generation of integrations! 🚀 Feedback is welcome in issues, and contributions via pull requests are even better! 💜
If you have suggestions, questions, or ideas for what we should tackle next, you can reach us on Discord or follow us on X / Twitter or Bluesky. We’re always happy to hear from you.
Ready to try it out? Head to the pgstream documentation to get started!
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
pgstream v0.9.0: Better schema replication, snapshots and cloud support
Bringing connection retries, anonymizer features, memory improvements and solid community input.
pgstream v0.8.1: hstore transformer, roles snapshotting, CLI improvements and more
Learn how pgstream v0.8.1 transforms hstore data and improves snapshot experience with roles snapshotting and excluded tables option
pgstream v0.7.1: JSON transformers, progress tracking and wildcard support for snapshots
Learn how pgstream v0.7.1 transforms JSON data, improves snapshot experience with progress tracking and wildcard support.
pgstream v0.6.0: Template transformers, observability, and performance improvements
Learn how pgstream v0.6 simplifies complex data transformations with custom templates, enhances observability and improves snapshot performance.
pgstream v0.5.0: New transformers, YAML configuration, CLI refactoring & table filtering
Improved user experience with new transformers, YAML configuration, CLI refactoring and table filtering.
pgstream v0.4.0: Postgres-to-Postgres replication, snapshots & transformations
Learn how the latest features in pgstream refine Postgres replication with near real-time data capture, consistent snapshots, and column-level transformations.
Behind the scenes: Speeding up pgstream snapshots for PostgreSQL
How targeted improvements helped us speed up bulk data loads and complex schemas.
Introducing pgstream: Postgres replication with DDL changes
Today we’re excited to expand our open source Postgres platform with pgstream, a CDC command line tool and library for PostgreSQL with replication support for DDL changes to any provided output.
Postgres Cafe: Solving schema replication gaps with pgstream
In this episode of Postgres Café, we discuss pgstream, an open-source tool for capturing and replicating schema and data changes in PostgreSQL. Learn how it solves schema replication challenges and enhances data pipelines.
Postgres webhooks with pgstream
Trigger HTTP webhooks on every INSERT, UPDATE, or DELETE in PostgreSQL. Open-source CDC setup with pgstream, no polling required.