Introducing pgstream: Postgres replication with DDL changes
Today we’re excited to expand our open source Postgres platform with pgstream, a CDC command line tool and library for PostgreSQL with replication support for DDL changes to any provided output.
By:
Esther Minano SanzPublished:
Reading time:
7 min readWhy?
At Xata, Postgres takes centre stage. And while it is our main database, we also offer other features that require us to extend its reach while keeping the data in sync. A good example of this is our full-text search feature, which enables the use of Elasticsearch on top of Postgres. To keep these two datastores in sync, we capture and identify data and schema changes in Postgres and push these modifications downstream to Elasticsearch with minimal latency. This is often referred to as CDC (Change Data Capture).
So now you know our use case, but why did we build our own replication tool? There's many established solutions out there, but we had very specific requirements, which included support for continuous tracking of schema changes (DDL). This was something that existing tooling didn't support at the time. Database schemas have a tendency to change over time - if your CDC tool doesn't support replicating them, you risk data loss and manual intervention to fix your pipeline. There had to be a better way!
We also wanted a solution that was easy to deploy and operate for both big and small setups, which isn't always the case for existing tooling.
Introducing pgstream
And so pgstream was born! pgstream is an open source CDC command-line tool and library. Some of its key features include:
- Schema change tracking and replication of DDL changes: it's no surprise that this became an integral feature of pgstream, since it was one of the biggest requirements. We will go into a bit more detail on how this is implemented below.
- Modular deployment configuration: pgstream modular implementation allows it to be configured for simple use cases, removing unnecessary complexity and deployment challenges - the only requirement for pgstream is a Postgres database! However, it can also easily integrate with Kafka for more complex use cases.
- Elasticsearch/OpenSearch replication support: out of the box support for replicating Postgres data and schema changes to an Elasticsearch compatible store, with special handling of field IDs to minimise re-indexing caused by column renames.
- Webhook support: out of the box support to invoke a webhook endpoint whenever your source data changes. Helpful for reacting to specific data changes seamlessly.
How does pgstream work?
Internally, pgstream is constructed as a streaming pipeline, where data from one module streams into the next, eventually reaching the configured output plugins. pgstream keeps track of schema changes and replicates them alongside the data changes to maintain a consistent view of the source data downstream. This modular approach makes adding and integrating output plugin implementations simple and painless.
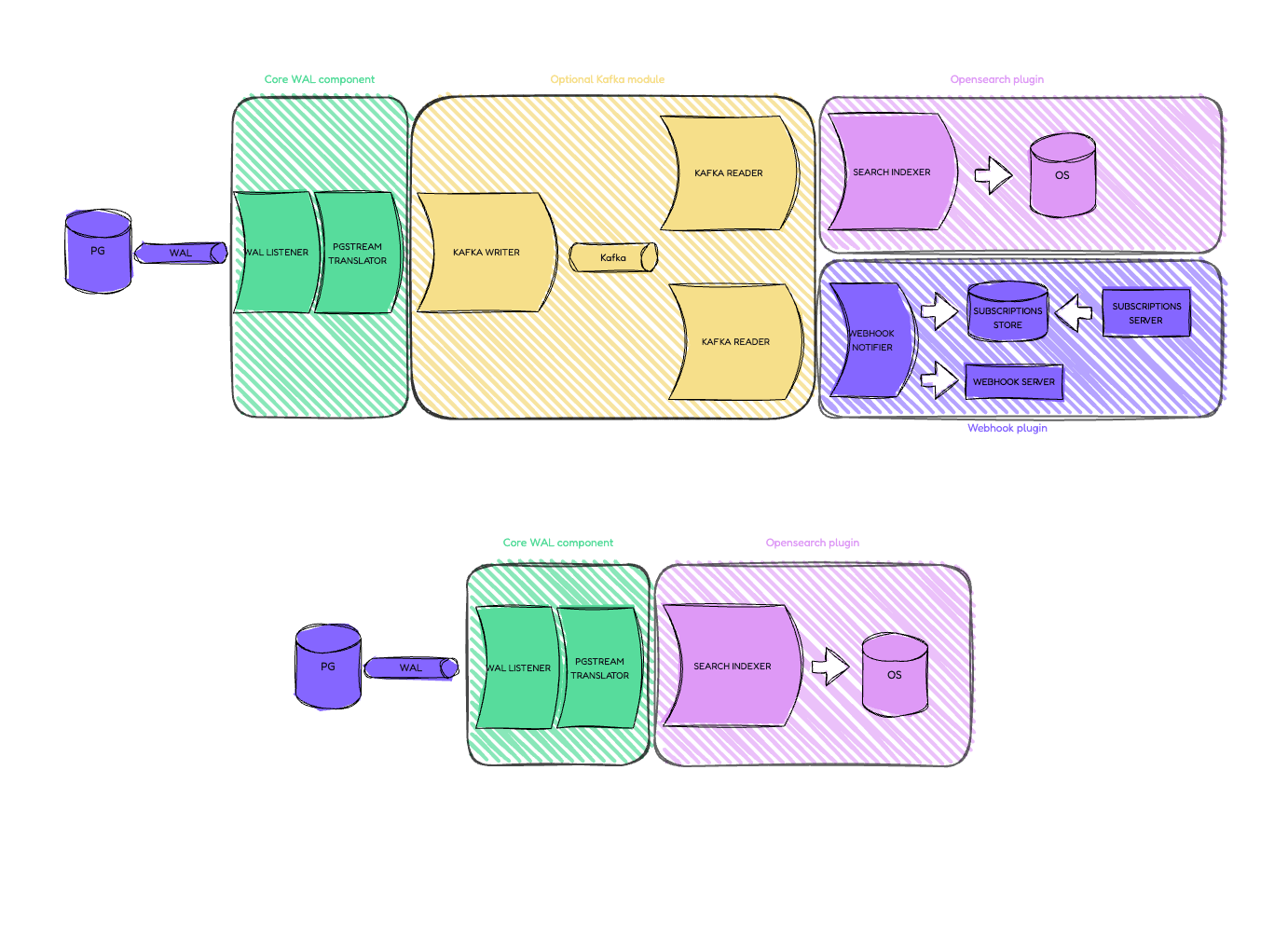
pgstream architecture
Tracking schema changes
One of the main differentiators of pgstream is that it tracks and replicates schema changes automatically. How? It relies on SQL triggers that will populate a Postgres table (pgstream.schema_log) containing a history log of all DDL changes for a given schema. Whenever a schema change occurs, this trigger creates a new row in the schema log table with the schema encoded as a JSON value. This table tracks all the schema changes, forming a linearised change log that is then parsed and used within the pgstream pipeline to identify modifications and push the relevant changes downstream.
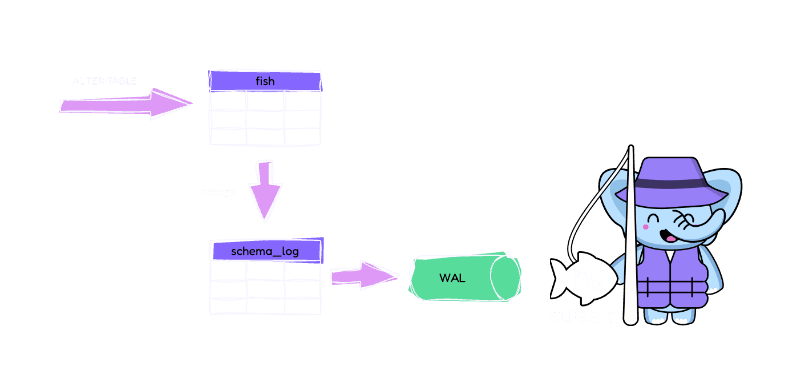
Tracking schema changes
The schema and data changes are part of the same linear stream - the downstream consumers always observe the schema changes as soon as they happen, before any data arrives that relies on the new schema. This prevents data loss and manual intervention.
Architecture
Disclaimer: There are a lot of references in this section to the WAL (Write Ahead Logging). It refers to a sequential record of all changes made to a database, and a key component to Postgres replication.
Now, let's dive a little deeper into the stream!
At a high level, the internal implementation is split into WAL listeners and WAL processors.
WAL listener
A listener is anything that listens to WAL data, regardless of the source. It has a single responsibility: consume and manage the WAL events, delegating the processing of those entries to modules that form the processing pipeline. Depending on the listener implementation, it might be required to also have a checkpointer to flag the events as processed once the processor is done.
There are currently two implementations of the listener:
- Postgres listener: listens to WAL events directly from the replication slot. Since the WAL replication slot is sequential, the Postgres WAL listener is limited to run as a single process. The associated Postgres checkpointer will sync the LSN (Log Sequence Number) so that the replication lag doesn't grow indefinitely.
- Kafka reader: reads WAL events from a Kafka topic. It can be configured to run concurrently by using partitions and Kafka consumer groups, applying a fan-out strategy to the WAL events. The data will be partitioned by database schema by default, but can be configured when using pgstream as a library. The associated Kafka checkpointer will commit the message offsets per topic/partition so that the consumer group doesn't process the same message twice.
WAL processor
A processor processes a WAL event. Depending on the implementation it might also be required to checkpoint the event once it's done processing it as described above.
There are currently three implementations of the processor:
- Kafka batch writer: it writes the WAL events into a Kafka topic, using the event schema as the Kafka key for partitioning. This implementation allows the sequential WAL events to fan-out, while acting as an intermediate buffer to avoid the replication slot to grow when there are slow consumers. It has an internal memory-guarded buffering system to limit the memory usage of the buffer. The buffer is sent to Kafka based on the configured linger time and maximum size. It treats both data and schema events equally, since it disregards the content.
- Search batch indexer: it indexes the WAL events into an OpenSearch/Elasticsearch compatible search store. It implements the same kind of mechanism as the Kafka batch writer to ensure continuous processing from the listener, and it also uses a batching mechanism to minimise search store calls. The search mapping logic is configurable when used as a library. The WAL event identity is used as the search store document id, and if no other version is provided, the LSN is used as the document version. Events that do not have an identity are not indexed. Schema events are stored in a separate search store index (
pgstream), where the schema log history is kept for use within the search store (i.e. read queries). - Webhook notifier: it sends a notification to any webhooks that have subscribed to the relevant WAL event. It relies on a subscription HTTP server receiving the subscription requests and storing them in the shared subscription store which is accessed whenever a WAL event is processed. It sends the notifications to the different subscribed webhooks in parallel based on a configurable number of workers (client timeouts apply). Similar to the two previous processor implementations, it uses an internal memory-guarded buffering system which separates the WAL event processing from the webhook sending, optimising the processor latency.
In addition to the implementations described above, there's an optional processor decorator, the translator, that injects some of the pgstream logic into the WAL event. This includes:
- Data events:
- Setting the WAL event identity. If provided, it will use the configured id finder (only available when used as a library), otherwise it will default to using the table primary key/unique not null column.
- Setting the WAL event version. If provided, it will use the configured version finder (only available when used as a library), otherwise it will default to using the event LSN.
- Adding pgstream IDs to all columns. This allows us to have a constant identifier for a column, so that if there are renames, the column id doesn't change. This is particularly helpful for the search store, where a rename would require a re-index, which can be costly depending on the data.
- Schema events:
- Acknowledging the new incoming schema in the Postgres
pgstream.schema_logtable.
What's next?
This is only the beginning! We plan to continue developing pgstream and exploring how it can make it easier to replicate data.
Here are some of the items in our development pipeline:
- Support for multiple Kafka topics
- Additional Postgres plugin support (
pgoutput) - Advanced data stream filtering
- Automatic backfill of existing data
- Additional Kafka serialisation formats (
avro) - Additional output plugin support (
postgres,clickhouse,snowflake) We are excited to share this with you and look forward to your feedback! Want to see pgstream in action? Check out this quick demo video.
If you have any suggestions or questions, please open an issue in our GitHub repo, reach out to us on Discord or follow us on X / Twitter. We'd love to hear from you and keep you up to date with the latest progress on pgstream.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Postgres webhooks with pgstream
Trigger HTTP webhooks on every INSERT, UPDATE, or DELETE in PostgreSQL. Open-source CDC setup with pgstream, no polling required.
pgstream v0.4.0: Postgres-to-Postgres replication, snapshots & transformations
Learn how the latest features in pgstream refine Postgres replication with near real-time data capture, consistent snapshots, and column-level transformations.
Postgres Cafe: Solving schema replication gaps with pgstream
In this episode of Postgres Café, we discuss pgstream, an open-source tool for capturing and replicating schema and data changes in PostgreSQL. Learn how it solves schema replication challenges and enhances data pipelines.