Postgres webhooks with pgstream
Trigger HTTP webhooks on every INSERT, UPDATE, or DELETE in PostgreSQL. Open-source CDC setup with pgstream, no polling required.
By:
Tudor GolubencoPublished:
Reading time:
6 min readpgstream is a CDC (Change-Data-Capture) tool focused on PostgreSQL. Among other things, it can be used to call webhooks whenever there is a data (or schema) change in a Postgres database. This means that whenever a row is inserted, updated, or deleted, or a table is created, altered, truncated or deleted, a webhook is notified of the relevant event details.
In this article we're going to dive into the pgstream webhooks functionality, including more advanced topics, like sending the old and new values, TOAST support, and schema changes support.
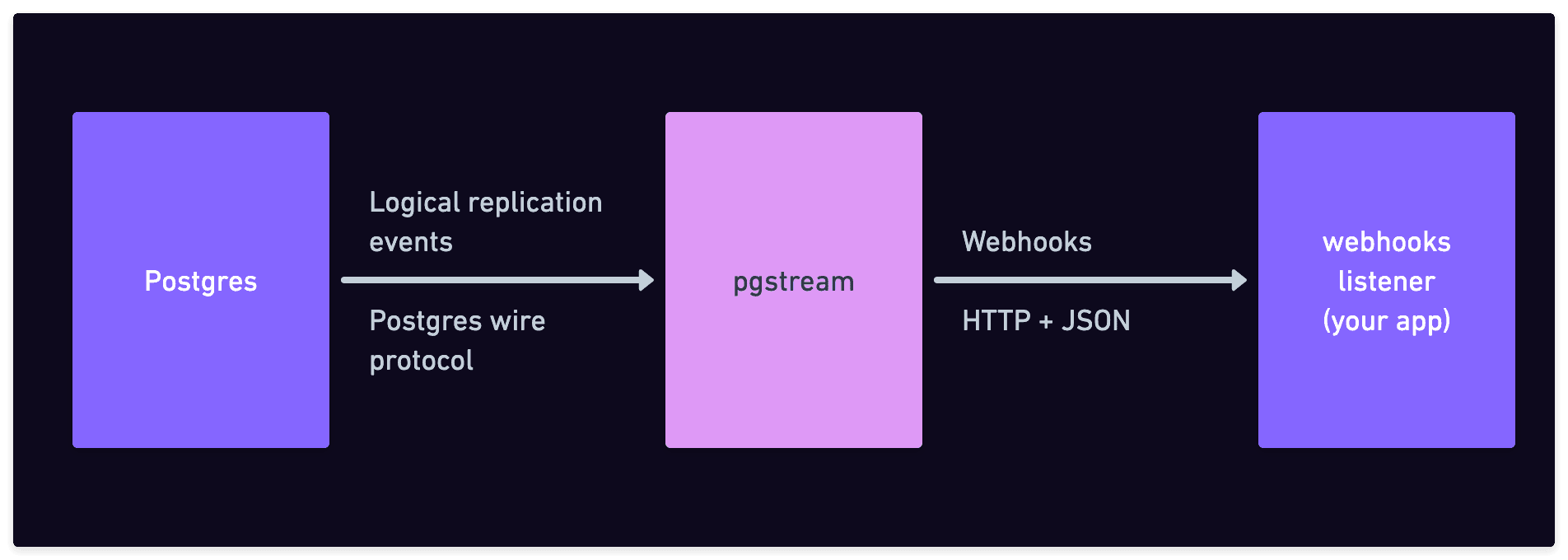
Postgres webhooks with pgstream
Preparation
For this tutorial we need a Postgres instance that has logical replication enabled and the wal2json output plugin loaded. There are a number of ways to do this, but we're going to use the docker-compose file from the pgstream repo:
And then start the Postgres instance:
Then, in a new terminal window, you can connect to it and create a simple table to play with:
At the psql prompt:
Let's now install pgstream. One option is to build it from source, since we already have the repo cloned:
The above assumes you have Go installed. If you don't, check out the other installation options.
Next step is to initialize pgstream, like this:
This creates several tables managed by pgstream, which are grouped in a schema called pgstream.
Configuration
The pgstream repo comes with a pg2webhook.env configuration file for this purpose. Its contents are:
PGSTREAM_POSTGRES_LISTENER_URL indicates which database the pgstream listener should connect to. PGSTREAM_WEBHOOK_SUBSCRIPTION_STORE_URL is used as a metadata db to store the registered subscriptions and their configuration. In this example, they are both set to the same database, but you can use different databases or instances if you prefer. More details can be found in the readme configuration section.
You are now ready to start pgstream like this:
The webhooks listener
We now have pgstream ready to go, but we need something to receive the webhooks. This is normally your application, or a lambda function, or similar. pgstream comes with a sample webhooks listener written in Go. You can start it like this:
This starts a server on port 9910 that simply logs any JSON payload that is received under the /webhook path.
Now we have to create a subscription so that pgstream knows to send the webhook to localhost:9910/webhook where the webhook_server.go program is waiting. We do this by calling an API which the webhook module from pgstream serves:
The above adds a line in the pgstream.webhook_subscriptions table, which is maintained by pgstream. You can verify by running via psql:
Notes:
- in the API call above, we subscribe to a particular table. If you'd like to subscribe to all tables in a schema, leave the
tablekey unset. - you can also subscribe to only some particular event types. To do this, set the
event_typeskey to an array containing the operations you want (Ifor inserts,Ufor updates,Dfor deletes,Tfor truncates).
Inserts
With pgstream and the webhooks_server.py started in different consoles, let's run the following SQL via psql:
You should see the following printed by the python program:
Things to note in the above:
- The "action" is
Ifor "insert". - The LSN (Log Sequence Number) is included. This is a unique and sorted value generated by Postgres, which you can use to order the events in case they are processed out of order.
- Each column is included with their name, type, new value, and an ID generated by pgstream (e.g.
cr2a0enjc0j00h93rdj0-2for thenamecolumn). This ID is unique for each column and can be used to follow columns across renames.
Updates
Now let's run an update statement:
The following webhook event is received:
The above is very similar to the INSERT event, with a couple of differences:
- The "action" is set to
U, for update - The
identitysub-object is now filled. It contains the primary key of the affected row. Notably, this is the value of the primary key before the update, in case the update has changed the value of the PK.
Including old values
How about including the old values in addition to the new values for UPDATEs? Yes, that's possible, using a little trick.
See how in the above UPDATE event, the "identity" contains the PK value, and we noted that this is the PK value before the update? That is because the "replica identity" for the table is set to "primary key", which is the default. However, the replica identity can be set to any unique group of columns, or to "all columns" by setting it to FULL:
If we run the update again:
We now get all values after the update, but also before the update, under the identity field:
Deletes
Let's try a simple delete as well:
The generated event:
To note:
- The "action" key is set to
D, for "delete" - The full row is included in the
identityobject. That is because we have the replicate identity set to FULL, otherwise only the PK would have been included.
Large values / TOAST
Setting the replica identity to full accomplishes one more thing: it includes the large values in the webhook events.
Postgres values over the page size (commonly 8k, after compression) are stored separately from the main table data in TOAST storage. This means they are also not included in the logical replication events by default, unless they are changed by the current UPDATE statement. This is a gotcha: you are expecting all columns to always be present, but once they reach a certain size they will be missing.
However, setting the replica identity to full solves this. To test this, try the following:
Note, however, that the TOASTed value is included only in the identity part of the event, so your application needs to pick it up from there.
At this point, you might be wondering what are the downsides of setting the replica identity to full. Luckily, we wrote a full blog post about that. In short: there are some performance impacts, more relevant for the Postgres to Postgres replication use case and less relevant for the webhooks calling use case.
Schema change events
Let's look at one more pgstream trick: receiving webhooks for schema changes, in addition to data changes.
Postgres replication events have the well-known limitation that they don't include any schema changes. This can be an issue if your application requires having an up-to-date view of the schema.
pgstream works around this limitation by installing DDL event triggers and maintaining the list of changes in a separate table, called pgstream.schema_log. Then, pgstream can subscribe to this table just like any other table.
To get schema events, we create another subscription pointing to the same webhooks listener server as before:
Now if we do a schema change:
We get an event like this:
The event is more complex, but if you look under the schema column value, you see the newly added column:
Note how you get not only the name and the type of the column, but also metadata information (is nullable, is unique, default value).
Also, the pgstream_id value is unique and fixed for this column, regardless of the name. You can verify this by performing a rename:
Conclusion
In this guide, we demonstrated how to set up and trigger webhooks based on data changes in a PostgreSQL database using pgstream. We covered the initial setup, webhook configuration, and handling basic operations like inserts, updates, and deletes.
pgstream also offers advanced capabilities, such as sending both old and new values during updates and managing schema changes. By integrating pgstream into your PostgreSQL environment, you can automate workflows, trigger real-time notifications, and build more responsive applications, whether for data synchronization, auditing, or microservices communication.
If you have any questions or hit issues with this tutorial, please open an issue in the pgstream repo or join us in Discord.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Introducing pgstream: Postgres replication with DDL changes
Today we’re excited to expand our open source Postgres platform with pgstream, a CDC command line tool and library for PostgreSQL with replication support for DDL changes to any provided output.
pgstream v0.4.0: Postgres-to-Postgres replication, snapshots & transformations
Learn how the latest features in pgstream refine Postgres replication with near real-time data capture, consistent snapshots, and column-level transformations.