Behind the scenes: Speeding up pgstream snapshots for PostgreSQL
How targeted improvements helped us speed up bulk data loads and complex schemas.
By:
Esther Minano SanzPublished:
Reading time:
6 min readThe last few pgstream releases have focused on optimizing snapshot performance, specifically for PostgreSQL targets. In this blog post, we’ll walk through the key improvements we made, share the lessons we learnt, and explain how they led to significant performance gains. But first, some context!
What is pgstream?
pgstream is an open source CDC(Change Data Capture) tool and library that offers Postgres replication support with DDL changes. Some of its key features include:
- Replication of DDL changes: schema changes are tracked and seamlessly replicated downstream alongside the data, avoiding manual intervention and data loss.
- Modular deployment configuration: pgstream modular implementation allows it to be configured for simple use cases, removing unnecessary complexity and deployment challenges. However, it can also easily integrate with Kafka for more complex use cases.
- Out of the box supported targets:
- Postgres: replication to Postgres databases with support for schema changes and batch processing.
- Elasticsearch/Opensearch: replication to search stores with special handling of field IDs to minimise re-indexing.
- Webhooks: subscribe and receive webhook notifications whenever your source data changes.
- Snapshots: capture a consistent view of your Postgres database at a specific point in time, either as an initial snapshot before starting replication or as a standalone process when replication is not needed.
- Column transformations: modify column values during replication or snapshots, which is particularly useful for anonymizing sensitive data.
For more details on how pgstream works under the hood, check out the full documentation.
🔍 The Original Implementation
The snapshot phase is a critical part of logical replication. It captures a consistent view of the source database to initialize the target and needs to complete reasonably fast without putting too much strain on the source. Otherwise, onboarding existing databases, especially large or busy ones, becomes slow, disruptive, or outright unfeasible.
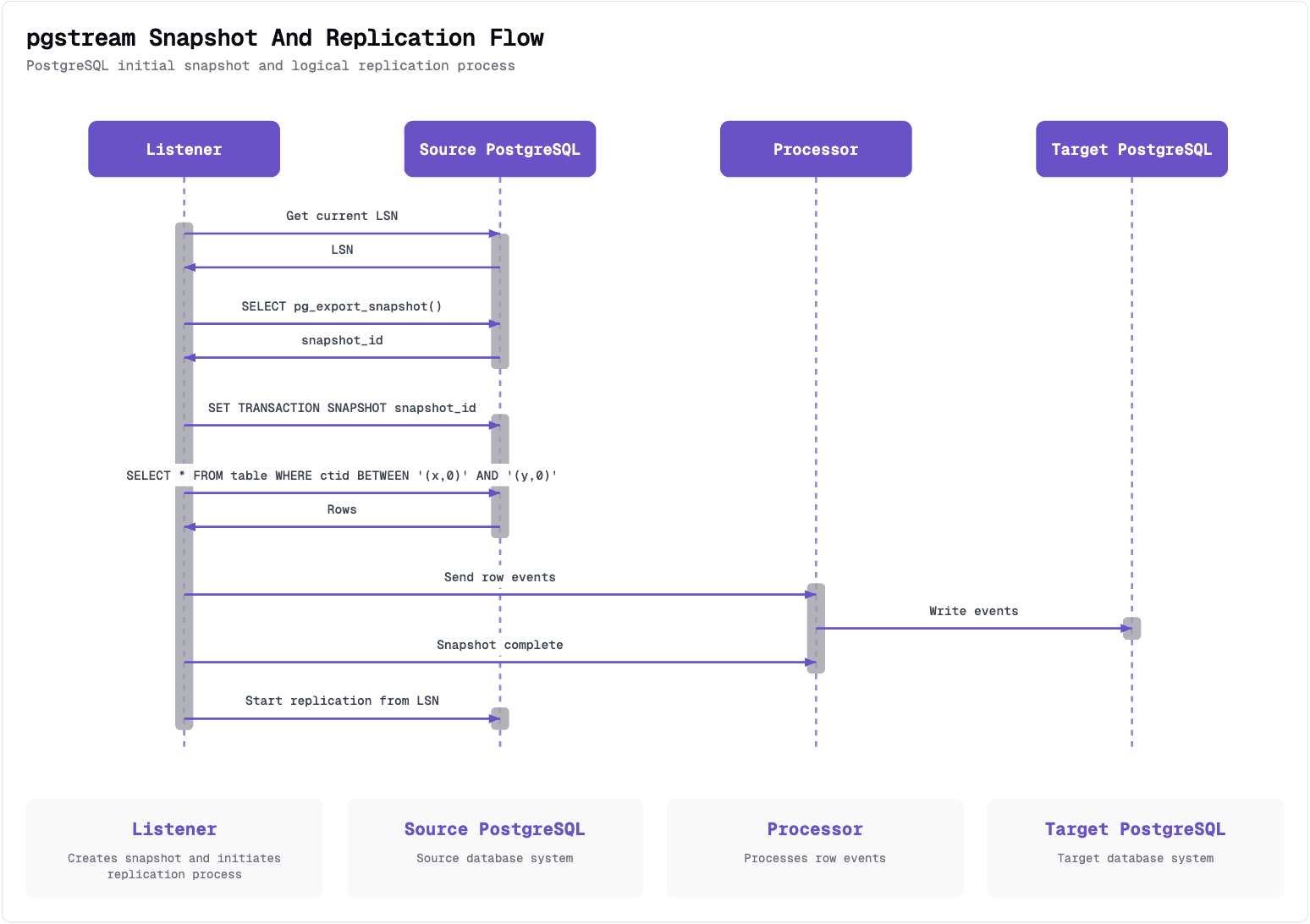
The snapshot process involves four main steps:
- Capturing the source PostgreSQL database schema
- Restoring the source schema into the target PostgreSQL database
- Reading data from the source PostgreSQL database
- Writing that data into the target PostgreSQL database
Let’s take a closer look at how we originally implemented each part.
Schema
PostgreSQL schemas can get pretty complex, with lots of different elements to account for. While pgstream captures a simplified version of the schema to support DDL replication, that view isn’t detailed enough to rely on for full database snapshots. Instead of reinventing the wheel, we decided to lean on pg_dump/pg_restore, the trusted native tools that already handle this job well. Their flexible options let us fine-tune exactly what kind of schema dump we need, depending on the situation.
Reads
pgstream uses PostgreSQL’s transaction snapshot mechanism to get a consistent, read-only view of the database. This stable snapshot allows for parallelism at multiple levels: it enables concurrent table snapshots and even intra-table parallelism by scanning partitions or row ranges via the ctid. Since ctid reflects a row’s physical location, we can use it to perform efficient and deterministic range queries, no indexes needed.
The level of parallelism is configurable, so users can tune the trade-off between speed and resource usage to suit their environment. This design takes inspiration from systems like DuckDB and PeerDB, which use similar techniques to achieve fast, low-impact snapshots.
Writes
The initial implementation of the PostgreSQL writer batched multiple row events (i.e., INSERT queries) into transactions. It would flush a batch either when a configured batch size was reached or after a timeout. Maintaining the order of operations is important in a replication scenario, so batching helped reduce I/O while preserving that order.
⚠️ The Problem
We quickly saw that snapshot performance was lagging, especially compared to how effortlessly pg_dump/pg_restore handled the same databases. While those tools are finely tuned for PostgreSQL, our goal was for pgstream to be a real contender: just as fast, but with bonus features like column transformations and built-in schema replication. So, we rolled up our sleeves and went performance hunting. 🏹
After releasing better observability tools in v0.6.0 🔭, the culprit became obvious: the bottleneck was in the write path.
The read side was already following a tried-and-tested model for performance, but the write logic was initially geared toward low-throughput replication - not bulk data loads.
⚙️ The Solution
Once we confirmed that writes were slowing us down, we started looking at ways to improve write performance just for snapshots, without impacting the replication writer.
Bulk Ingest
During a snapshot, we’re only issuing INSERT statements, and we disable triggers to prevent foreign key checks, so we don't need to worry about row order. That gave us some flexibility to explore better write strategies for insert-heavy loads.
PostgreSQL supports several ways to insert data:
- Individual
INSERTstatements (original approach)
- Batch
INSERTstatements
COPY FROM(supports formats like CSV and binary)
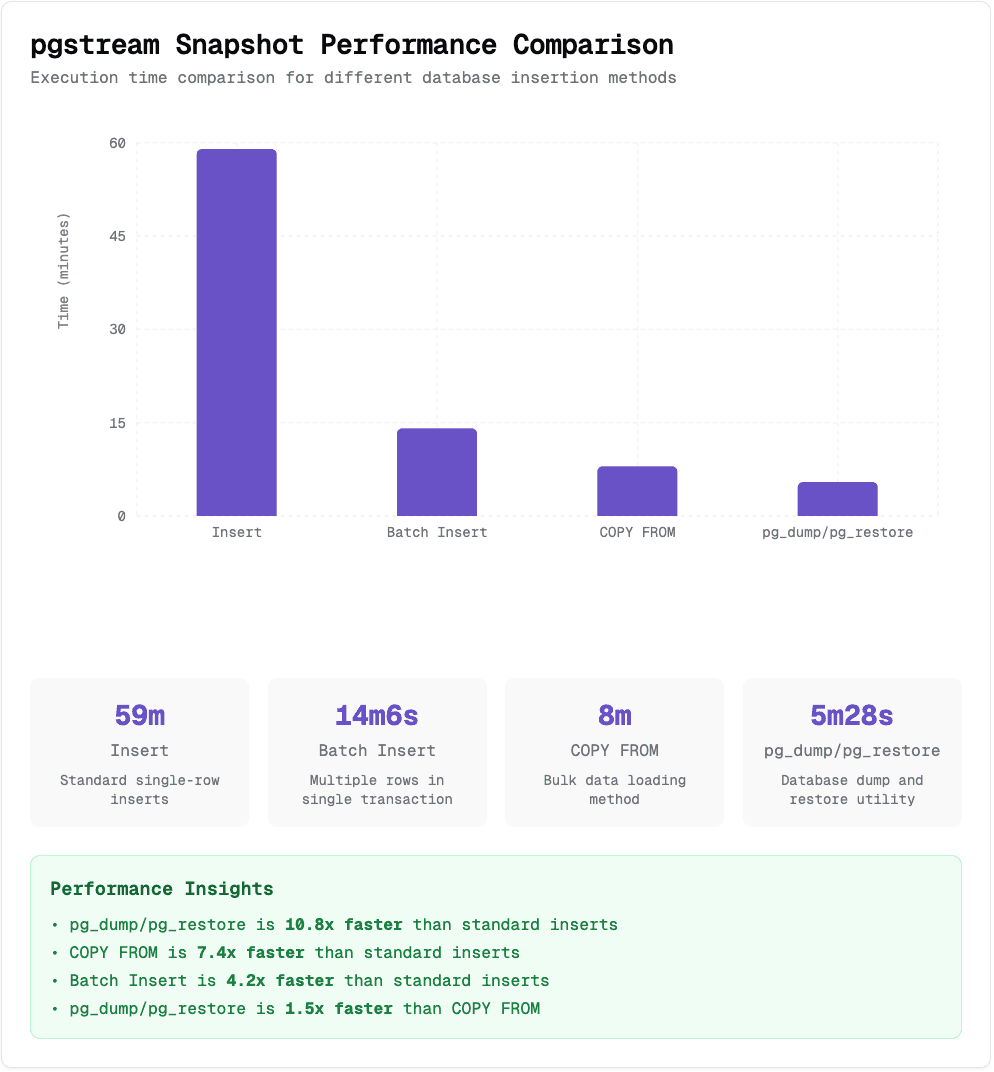
This TigerData blog post benchmarks these methods and—spoiler alert—COPY FROM is by far the fastest for bulk inserts.
We implemented both batch INSERT and binary COPY FROM, then tested them against the IMDb dataset (21 tables, ~9GB). Using 4 tables in parallel with 4 workers each, the results clearly showed that binary COPY FROM was the way to go.
Deferred index creation
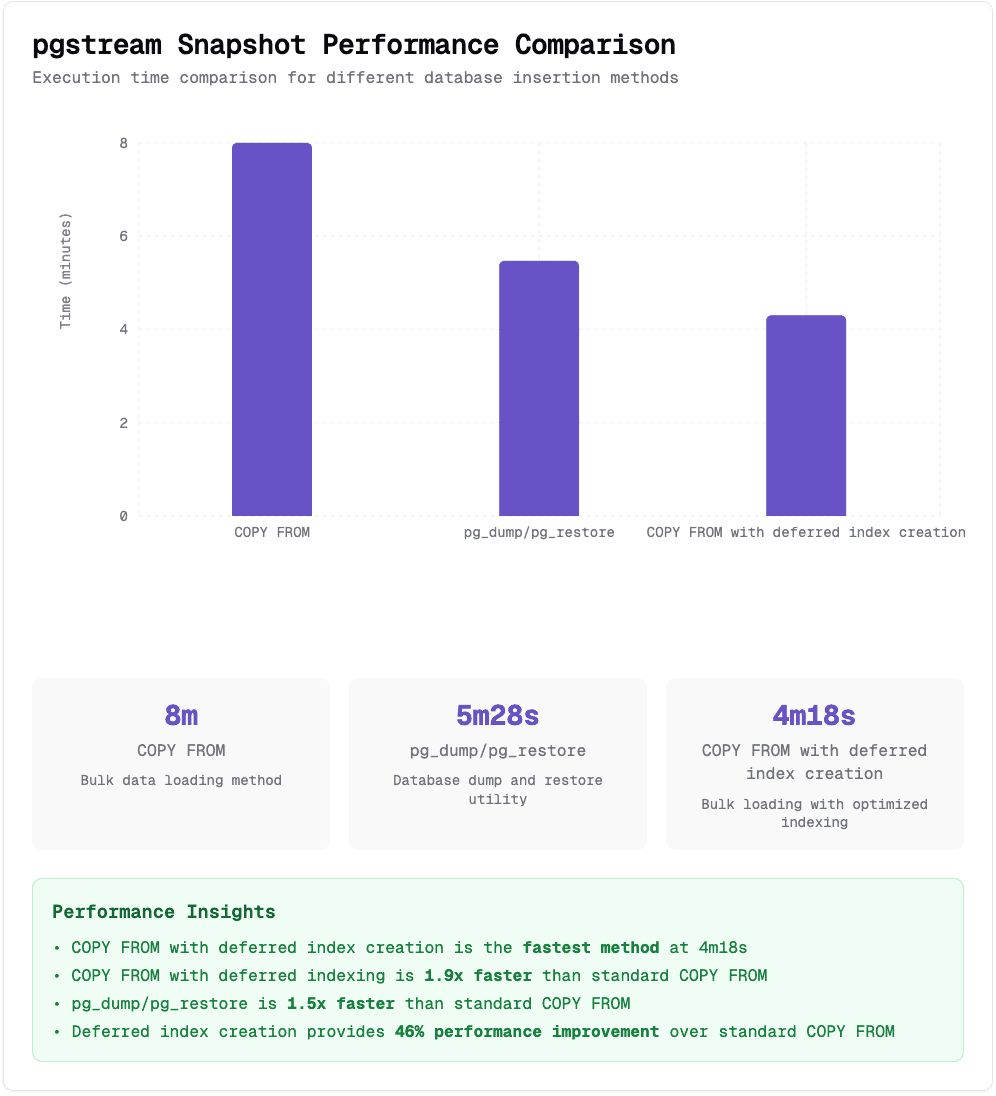
With faster inserts in place, we ran tests on more complex schemas. That’s when we noticed something: the gains were less impressive on databases with lots of indexes and foreign key constraints. In fact, we were still a bit slower than pg_dump/pg_restore, although getting close.
The reason? pg_dump/pg_restore postpones index and constraint creation until after the data load. This avoids the overhead of updating indexes and validating constraints during inserts.
Since the snapshot process doesn’t require validating foreign keys or check constraints mid-import, we borrowed this pattern. We isolated index/constraint/trigger creation and moved it to after the data load. Testing against the same IMDb dataset showed a significant win; pgstream snapshots were now faster than pg_dump/pg_restore!
Automatic Batch Configuration
Now that we had solid ingest performance, we turned to improving the snapshot configuration itself.
Originally, the read side partitioned tables using a configurable number of rows per batch. But that approach has a problem: not all pages (which are relied upon for the ctid range scan described above) have the same number of rows. For example, if one table has 10 rows per page and another has 1000 rows per page, a batch size of 10000 rows per batch would retrieve 1000 pages for the first table and 10 for the second. That leads to wildly inconsistent memory usage and performance.
To fix this, we changed the config to specify data size per batch instead of number of rows per batch. Internally, we compute the average page count for each table and adjust the batch size accordingly, so every batch reads a consistent amount of data.
While this tweak didn’t lead to massive performance gains, it made snapshots more predictable and better at handling mixed workloads with different table shapes.
We considered doing something similar on the writer side, but since we’d already met our performance goals, we decided to pause there and revisit if needed.
📊 Benchmarks
With all the improvements in place, let's review the results for a couple of different sized datasets, using pg_dump/pg_restore as baseline.
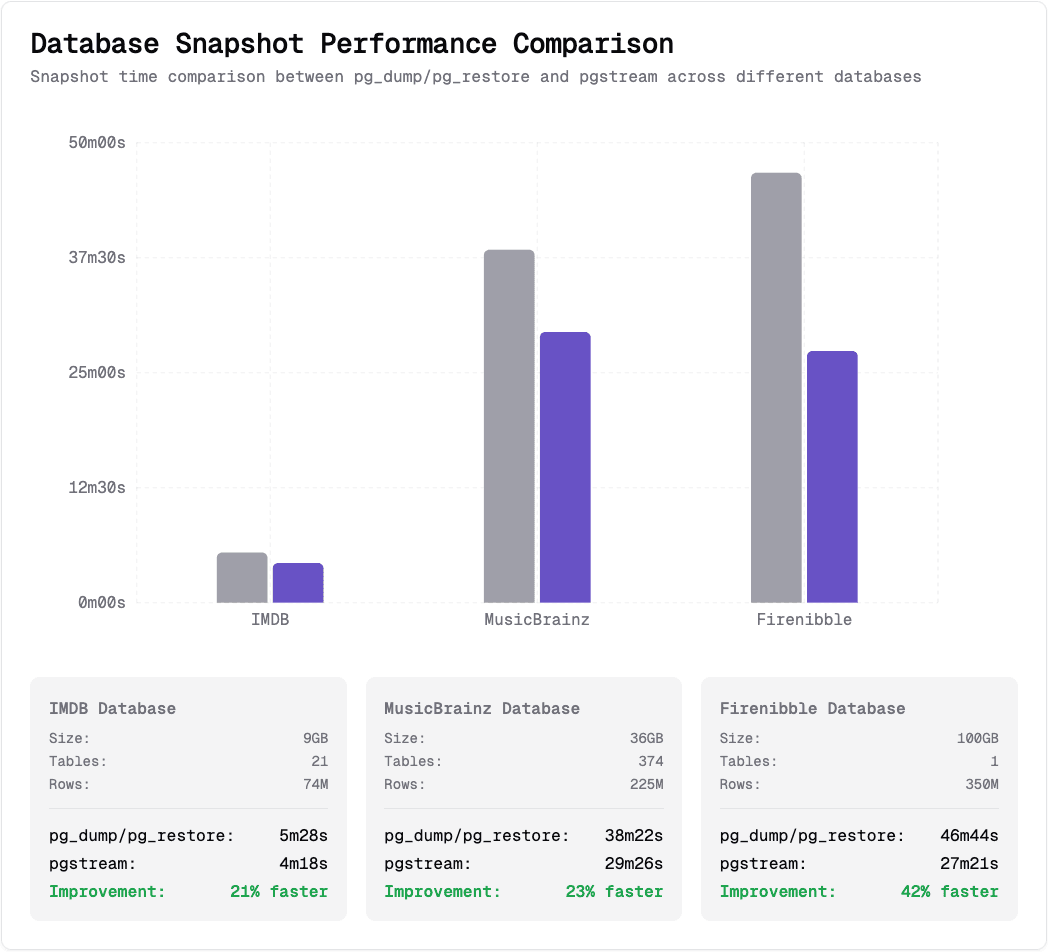
Datasets used: IMDB database, MusicBrainz database, Firenibble database.
All benchmarks were run using the same setup, with pgstream v0.7.2 and pg_dump/pg_restore (PostgreSQL) 17.4, using identical resources to ensure a fair comparison.
✅ Conclusion
As with most performance wins, they can seem obvious once you know the answer - but it’s funny how often small, simple changes make a big difference when applied in the right context. For us, it came down to having good visibility into what was happening, spotting specific workload patterns, and tuning for those instead of trying to force a one-size-fits-all solution.
The result? pgstream is now faster, smarter, and more robust when it comes to onboarding large or complex PostgreSQL databases, while still offering the flexibility of logical replication.
If you have ideas or suggestions on how we can make pgstream snapshots even faster, we’d love to hear from you! 🚀
You can reach out to us on Discord or follow us on X / Twitter or Bluesky. We welcome any feedback in issues, or contributions via pull requests! 💜
Ready to get started? Check out the pgstream documentation for more details.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
pgstream v0.7.1: JSON transformers, progress tracking and wildcard support for snapshots
Learn how pgstream v0.7.1 transforms JSON data, improves snapshot experience with progress tracking and wildcard support.
pgstream v0.6.0: Template transformers, observability, and performance improvements
Learn how pgstream v0.6 simplifies complex data transformations with custom templates, enhances observability and improves snapshot performance.
pgstream v0.5.0: New transformers, YAML configuration, CLI refactoring & table filtering
Improved user experience with new transformers, YAML configuration, CLI refactoring and table filtering.
pgstream v0.4.0: Postgres-to-Postgres replication, snapshots & transformations
Learn how the latest features in pgstream refine Postgres replication with near real-time data capture, consistent snapshots, and column-level transformations.
Introducing pgstream: Postgres replication with DDL changes
Today we’re excited to expand our open source Postgres platform with pgstream, a CDC command line tool and library for PostgreSQL with replication support for DDL changes to any provided output.
Postgres Cafe: Solving schema replication gaps with pgstream
In this episode of Postgres Café, we discuss pgstream, an open-source tool for capturing and replicating schema and data changes in PostgreSQL. Learn how it solves schema replication challenges and enhances data pipelines.
Postgres webhooks with pgstream
Trigger HTTP webhooks on every INSERT, UPDATE, or DELETE in PostgreSQL. Open-source CDC setup with pgstream, no polling required.