Introducing Xata OSS: Postgres platform with branching, now Apache 2.0
Xata core is now available as open source under the Apache 2 license. It adds copy-on-write branching, scale-to-zero compute to Postgres.
By:
Tudor GolubencoPublished:
Reading time:
7 min readXata is a cloud-native Postgres platform with the following highlights:
- Fast branching using Copy-on-Write at the storage level. You can “copy” TB of data in a matter of seconds. Except they are lightweight copies that happen instantly and take very little extra disk space.
- Scale-to-zero functionality, so inactive databases don’t cost you compute. Together with the previous point, this makes Postgres branches almost free.
- 100% Vanilla Postgres. We took a bit of a different path compared with Neon or Aurora: we run vanilla Postgres without any modifications. The branching functionality happens at the underlying storage layer (tech details below).
- All the production grade requirements: high availability, read replicas, automatic failover/switchover, upgrades, backups with PITR, IP filtering, etc
Xata’s customers use it in two major ways:
- For creating preview and testing environments quickly and with real data.
- As a fully-managed PostgreSQL service to run the production database.
The first use case is becoming particularly more popular with the advent of coding agents. Producing the code is now fast and cheap, but validating it with realistic production workloads still takes a long time. Synthetic or seeded data just doesn’t cut it for finding performance issues and subtle corner-case data bugs. Copying production data with pg_dump is slow and risky. Keeping many dev instances up and running for a long time is very expensive.
A solution with copy-on-write branching and scale-to-zero is the ideal solution for these types of issues.
With the new open-source distribution of Xata, any engineer in any organization can deploy Xata and without concerns related to adding a new vendor or having to worry about licensing.
For the second use case, organizations are now able to use Xata as their internal Postgres service. This is particularly useful if your organization needs a variety of instance sizes (e.g. a few large databases, many small ones, database per PR, etc.).
Copy-on-write: a short intro
To understand the Xata architecture, let’s start at the lowest layer and the go up.
The idea of copy-on-write (CoW) is not new. It has been widely used in databases, file systems, and operating systems. It typically looks like something like this:
Data is split into blocks and the location of each block is stored in a special metadata “index” block. Instead of accessing data directly, the program finds the location of the block in the index before accessing it.

When a copy is created, only the index block is copied initially. This new index block points to the same data blocks as the original. This is what makes the copy operation so fast, the index block is typically tiny compared to the full data size.
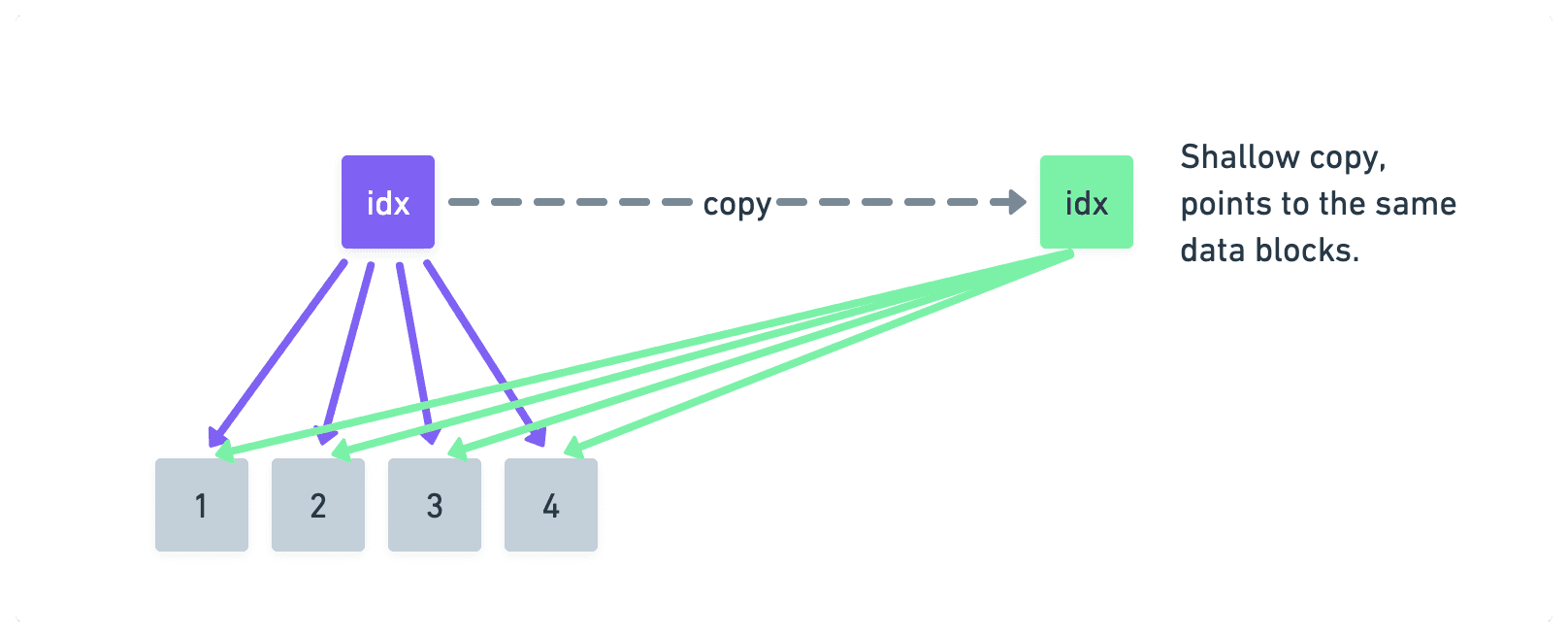
As long as only reads are received by both copies, this arrangement works. As soon as either of the two copies receives write, the copy happens (hence the name copy-on-write). But instead of copying all of the data, only the block that received the write is copied.
.png&w=3840&q=75&dpl=dpl_GFrdNEt6nnPv2yRSYbmjddFuyHys)
If the blocks are relatively small, the copy is almost invisible and induces no significant overhead. This is because, for example, Postgres only writes full pages, even if you only changed a single byte.
If in the end all blocks are written to, all blocks will be eventually copied. However, in many practical cases, a lot of blocks are not written at all after the initial creation, which means that this scheme has the potential to save a lot of storage space.
The key is in the storage system
One thing to note is that the original and the copy need to be able to access the same data blocks. Otherwise, there’s no way to take advantage of CoW. The most simple way of achieving this is to just run both on the same server. For Postgres branching, you can do this with a CoW filesystem, like ZFS or btrfs, like this:
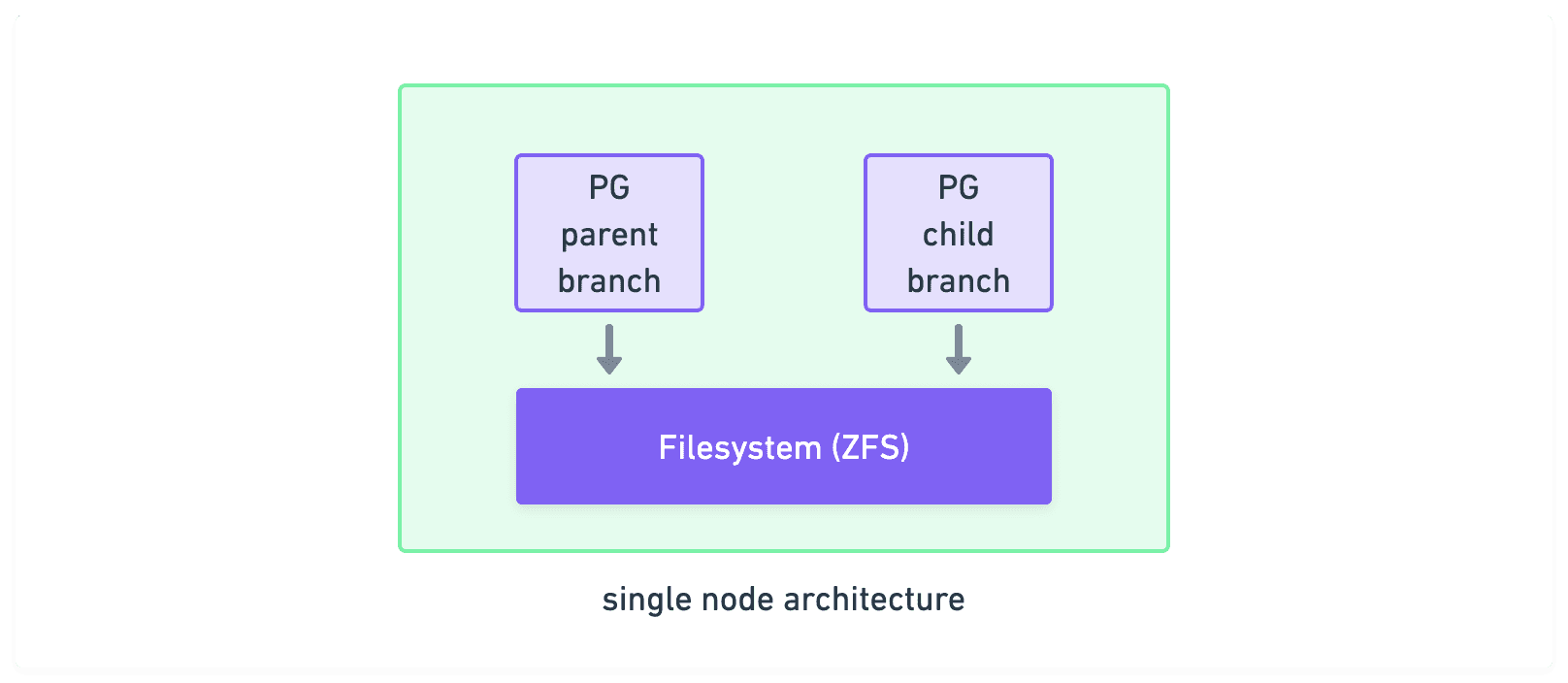
This is a good start, but it means that the parent and the child branches need to share the same CPU and RAM resources. For example, if the server has say 6 GB of RAM, and you need 2 GB for each Postgres instance, you can only run the parent and two other child branches.
This leads us to the idea of mounting the storage over the network. This way we can break free of single-node limits:
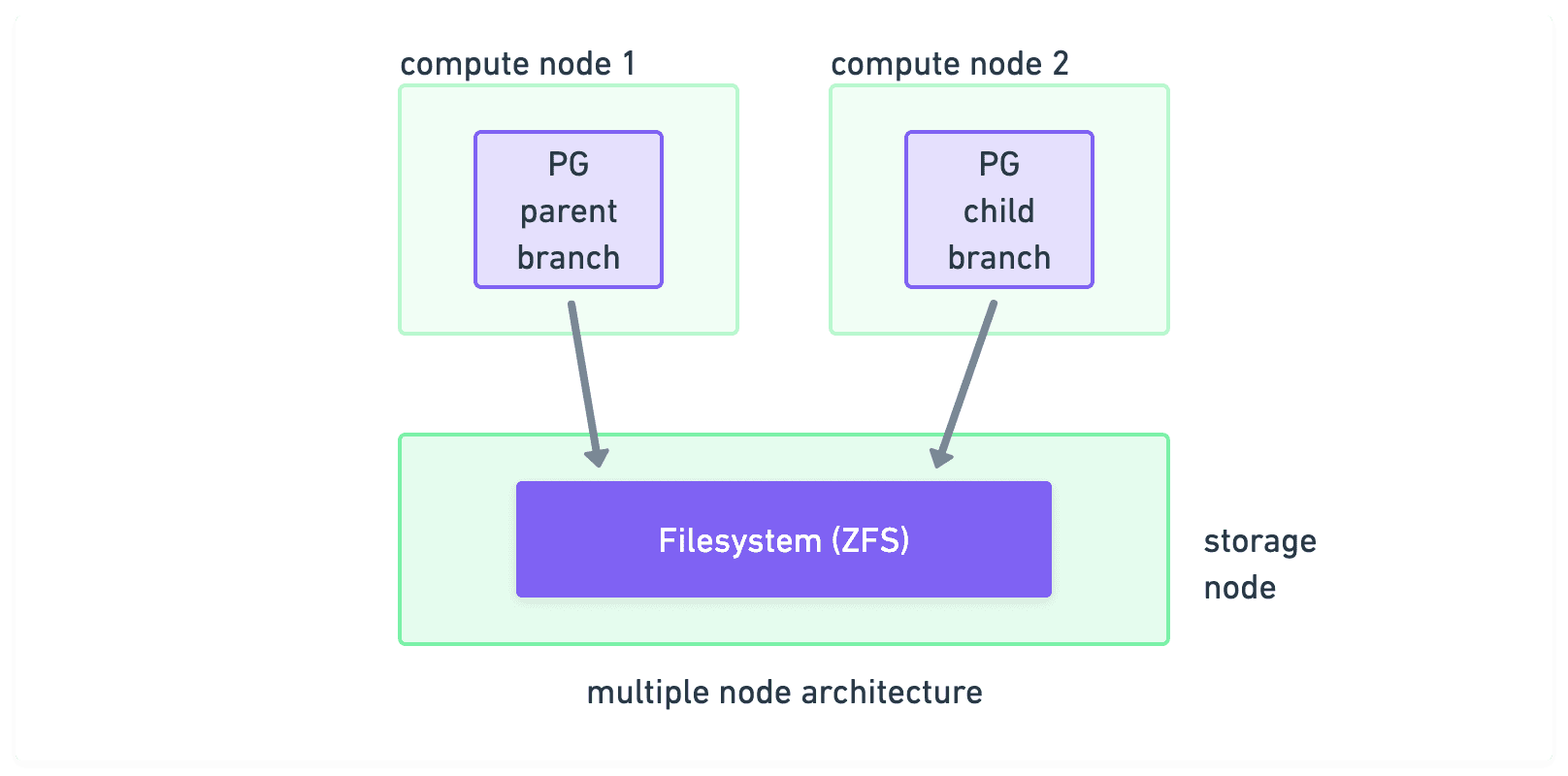
A lot can be written about the pros and cons of separating compute and storage for running databases. However, our primary use cases involve branching and scale-to-zero, and separating allows for a much more flexible compute layer.
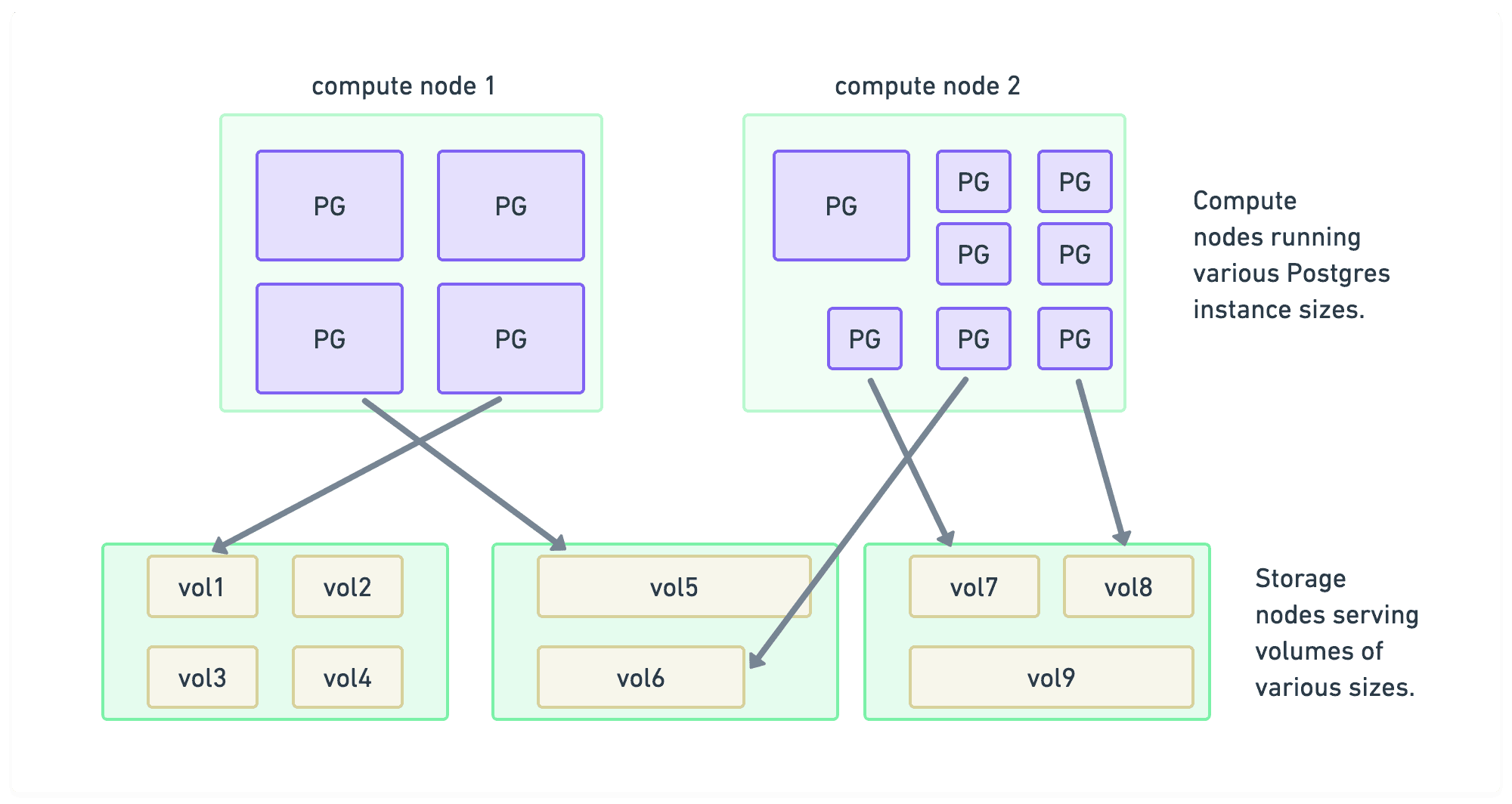
Freed up from the relatively static nature of bytes on disk, the compute layer can scale up and down with demand. We're efficiently bin-packing Postgres instances on the most optimal set of nodes.
In practice, it might looks something like this:
There are many ways to mount storage over the network. From good old NFS, to sshfs or WebDAV. They each have their own ideal use cases. For running databases with high performance, NVMe over fabrics (NVMe-of) stands out.
NVME-of has a stable implementation in the Linux kernel and is designed for high performance. It is capable of driving hundreds of thousands of IOPS over the network, which is exactly what Postgres needs.
Because it was important to us to be 100% vanilla PostgreSQL, with no significant modifications, a storage engine exposed over NVMe-of was the clear choice for us.
On the shoulder of giants
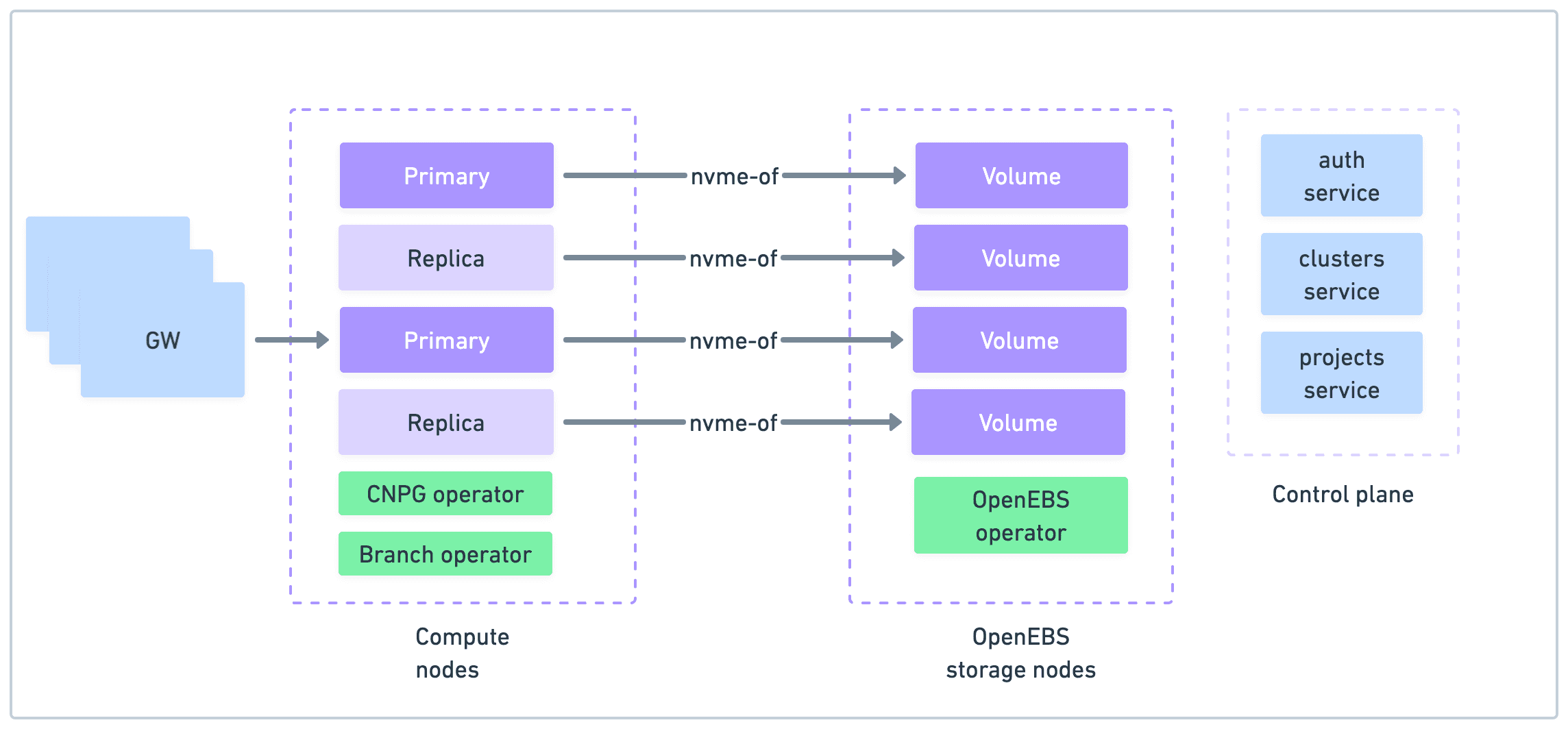
Looking deeper into the technology behind this effort, Xata is built on top of two mature cloud-native open source projects:
- CloudNativePG is a Postgres operator for Kubernetes. It handles most of the typical production concerns: high-availability, failover/switchover, upgrades, connection pooling, backups, etc.
- OpenEBS, is a a cloud native storage project, offering both local storage (i.e. local NVMe disks) as well as a replicated storage engine (also called Mayastor).
The Xata OSS project doesn’t just put these two technologies together, it builds a set of new components to work on top and along them.
More precisely, Xata adds:
- SQL gateway, responsible for routing, IP filtering, waking up scaled-to-zero clusters, serving the serverless driver over HTTP / websockets, etc.
- Branch operator managing all resources related to a branch.
- Clusters and projects services for the control-plane and REST APIs
- Auth service, based on Keycloack for API keys
- CLI that makes use of the REST API
- Scale-to-zero CNPG plugin for automatically hibernating branches on inactivity
All these components are now open source in the Xata repository. We also remain committed to our popular and long standing OSS projects::
- pgstream offers PostgreSQL replication with DDL statements and anonymization
- pgroll offers zero-downtime, undoable, schema migrations for PostgreSQL
When NOT to use Xata open source
You might be wondering how will we be making money if we just open sourced our platform. First, we should say that we didn’t open source quite everything. We have kept some components in our private repository:
- code for deploying and securing multi-organization, multi-region, and multi-cell installations.
- our own “Xatastor” storage engine. It similar to OpenEBS/Maystor but we developed it for the exact needs of the agentic workloads. We’ll be talking more about it in a future blog post.
In addition to technical features, it’s a matter of convenience: Even with a platform like Xata, operating a large fleet of Postgres clusters can be a challenge. Your time might be better utilized on your core business offerings.
This is why there are some cases were we actually recommend against using Xata open-source, for example:
- You only need a single Postgres instance. Xata is running on top of a Kubernetes cluster and it would be overkill for a single instance. You can either self-host Postgres on your own, or use a managed Postgres service, like Xata Cloud (coming soon).
- Offering a public Postgres-as-a-Service to offer your own users and customers. While the Apache 2 license allows this use case (nor do we have any intention to change it in the future), we don’t recommend using it like this because the OSS version does lack some security features related to adversarial multi-tenancy. If you are looking to offer PGaaS to your users and customers, likely our BYOC option is what you need. Book some time with us to discuss it.
Conclusion
Starting now, the core Xata platform is open-source under the Apache 2 license. If you are looking to deploy it inside your organization, we’d love to help, so don’t hesitate to reach out via GitHub issues or email.
Also, this is only the beginning of what's new at Xata. We have some exciting announcements happening over the next few weeks to share all of the important Postgres offerings we've been working on this year. Keep up with the announcements on X/Twitter, BlueSky, and LinkedIn.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Xata is now open source
Xata is an open-source Postgres platform for agent scale. Instantly create isolated databases with copy-on-write branching at low cost.
Xata: Postgres with data branching and PII anonymization
Relaunching Xata as "Postgres at scale". A Postgres platform with Copy-on-Write branching, data masking, and separation of storage from compute.