Xata: Postgres with data branching and PII anonymization
Relaunching Xata as "Postgres at scale". A Postgres platform with Copy-on-Write branching, data masking, and separation of storage from compute.
By:
Tudor GolubencoPublished:
Reading time:
8 min readHere at Xata, we’ve been quietly busy (re)building a new PostgreSQL platform from scratch. We've incorporated everything we learned from operating a Postgres data platform for over four years, combined with feedback from our customers and our analysis of the gaps in the current market.
The result is an entirely new Postgres service that:
- Has instant Copy-on-Write branches with data.
- Includes data anonymization so that developer branches don’t accidentally contain PII.
- Is cloud-agnostic, installable in your own AWS/GCP/Azure account, or even on-prem.
- Separates storage from compute with a distributed storage system accessed over NVMe/TCP.
- Offers a performance/cost ratio that is very competitive at scale.
We'll dive into the technical details shortly, but let's first talk about who this Postgres platform is for.
Postgres at scale
Our goal is to address the challenges teams face when using Postgres at scale. When we say "scale", we don't only mean technical dimensions like data volume, number of CPUs, GB of RAM, or vertical/horizontal scaling capabilities. While these are included in our definition of "at scale", we also mean organizational challenges such as:
- Zero-downtime requirements when applying schema changes or major version upgrades.
- Testing database changes or training AI models on realistic data sets that resemble the production data, but without any PII or sensitive data in them.
- Fast, cost-efficient ephemeral environments for developers.
- Security and compliance for companies that deal with sensitive data.
Let’s start by looking at staging and dev use cases, and then we’ll be talking about prod use cases as well.
Staging and dev use cases
Copy-on-Write branches are a great way to quickly spin up preview or development environments with production data, even when dealing with very large datasets. But on their own, they come with two major limitations:
- By design, the branches contain exactly the same data as the parent database, including private PII/PHI or any other sensitive data. This often violates compliance requirements and risks exposing data to developers.
- When it comes to schema changes, branching-out solves only half of the problem. The other half is merging back in. Copy-on-Write branches don't provide a mechanism to safely apply the changes you tested in a branch back to your production environment.
Fortunately, we've been working on these exact problems for quite some time now, through two open-source projects:
- pgstream - PostgreSQL replication with DDL changes, now also with masking/anonymization.
- pgroll - Zero-downtime, reversible, schema changes for PostgreSQL.
The new Xata platform combines these projects with Copy-on-Write branches, creating a complete, safe, and consistent developer workflow for PostgreSQL.
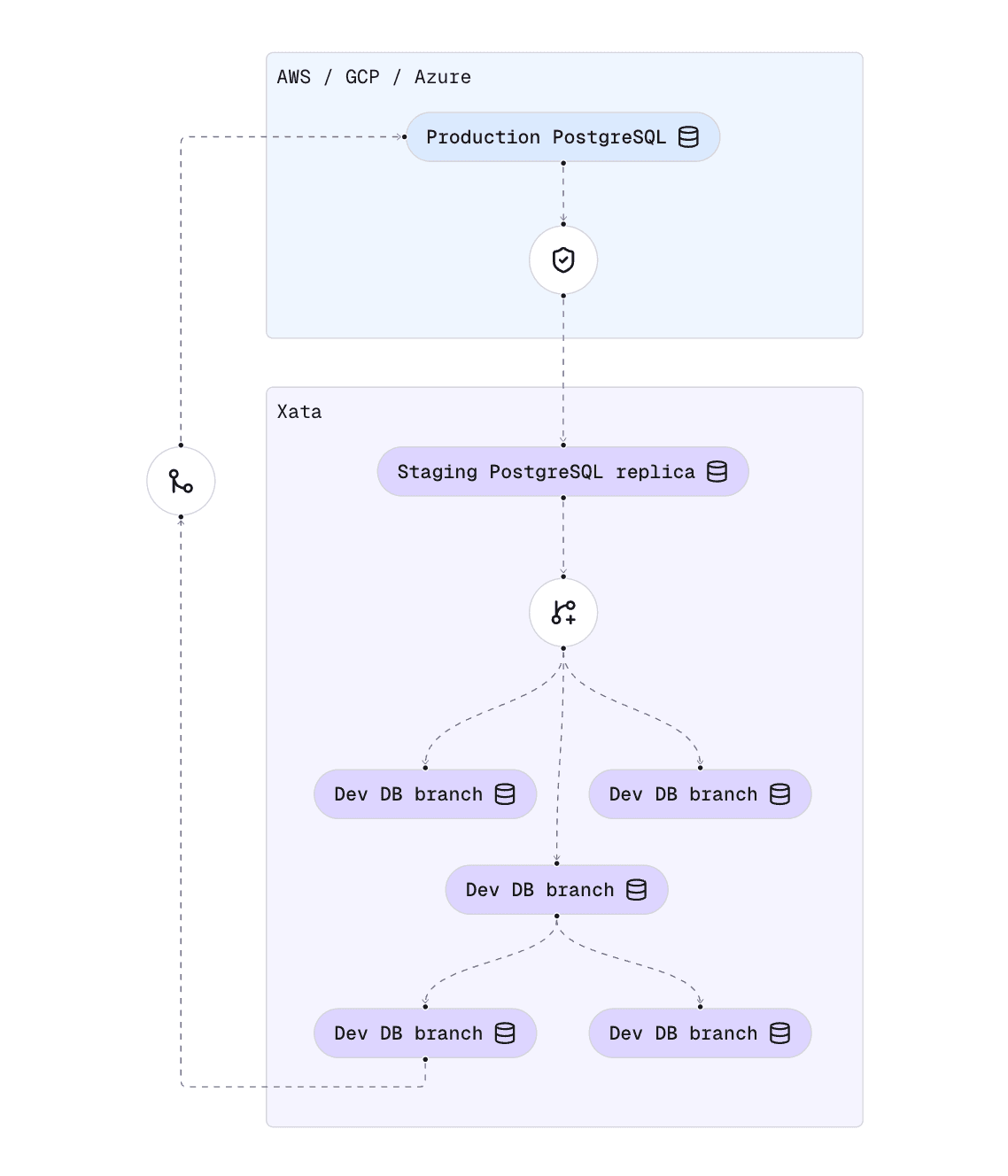
The best part is that you can use Xata even if you are not looking to change your production Postgres service. Xata works with and improves your existing PostgreSQL service, whether it's AWS RDS, Amazon Aurora, GCP CloudSQL, Azure Database, or even self-hosted Postgres.
At a high level, adopting Xata looks something like this:
- Your production database stays exactly as it is, no changes necessary.
- We create a “staging replica” on the Xata platform.
xata clone, powered bypgstream, copies and anonymizes the data on the fly.xata branch createlets you to create instant dev branches from the staging replica. These branches contain realistic, anonymized versions of your production data.- Optionally, use
xata roll, powered bypgroll, to test schema changes and safely apply them with zero-downtime to production.
If you don't want to send any data out of your production environment, even if anonymized, you don't have to: we have a BYOC (Bring Your Own Cloud) deployment model where all staging and dev branches run in your AWS/GCP/Azure/other account or even on-prem. More about that later.
Prod use cases
While you can get the Xata benefits without running your production on our platform, doing so gives you cost savings, better performance, and other wins in terms of flexibility, extensions, and support.
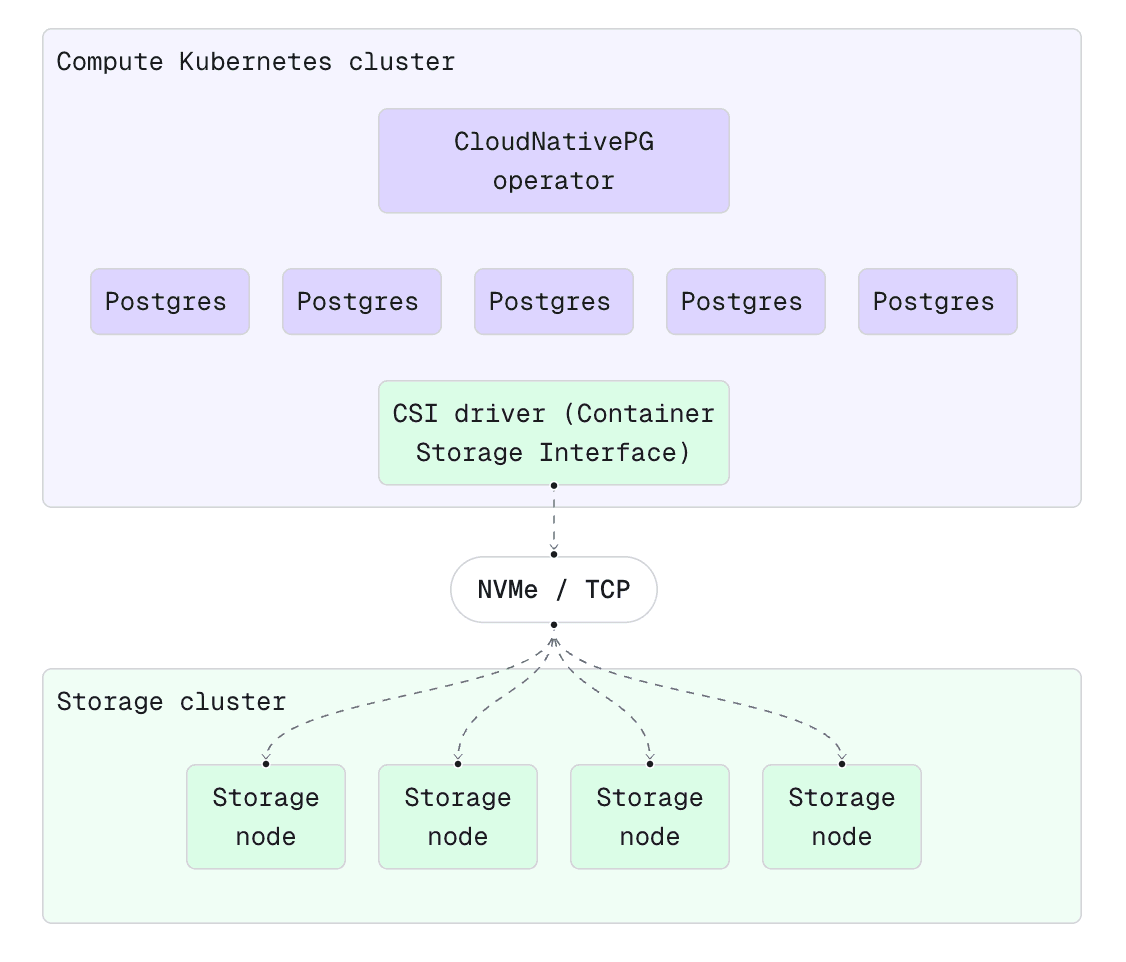
Xata uses an architecture that separates storage from compute. This brings benefits like:
- Scaling compute and storage separately.
- Storage has its own redundancy, increasing durability.
- Pay only for what you use in terms of storage, without needing to overprovision.
- Storage simply grows automatically and unbounded, without the risk of running out of disk space.
While services like Amazon Aurora and Neon also separate storage from compute, the Xata implementation is different because it is done strictly at the storage layer. This means that we didn’t have to modify Postgres at all. We simply run vanilla Postgres, and therefore have 100% Postgres compatibility, and mount logical volumes from our distributed storage cluster over high-performant NVMe over Fabrics (NVMe-oF).
We’ve kept our pricing model simple:
- Compute: Pay based on how much CPU and memory your instances have, per hour.
- Storage: Pay per GB-month.
This makes it easy to compare directly with Amazon Aurora, and our benchmarks show that we get slightly better performance at a much lower price point. The bottom line is that you can get up to 80% cost reduction when comparing our Pay As You Go plan with Aurora On Demand.
In terms of flexibility, because we don’t do any modifications to the Postgres code base, we can easily run any extension that you might require, including custom ones. We’re also happy to work with you to quickly approve and deploy new extensions as needed.
And if you're concerned about data governance, compliance, or latency, our Bring Your Own Cloud deployment model lets you run the full Xata platform in your own cloud account—or on-prem. This gives you full control while reducing network latency and avoiding bandwidth charges.
Storage: distributed storage system over NVMe/TCP
When it comes to understanding the new platform, the best place to start is the storage system. It’s the enabler for two of our core features: instant Copy-on-Write branching and the separation of storage from compute.
We are using a cloud-native, software-defined storage layer built for speed and resilience. It runs as a distributed cluster of storage nodes on Linux-based systems, exposing logical volumes as virtual NVMe devices. Using SPDK (Storage Performance Development Kit) and DPDK (Data Plane Development Kit), it achieves user-space storage operations with minimal latency.
For the best peformance, SPDK detaches NVMe devices from the Linux kernel, bypassing the typical kernel-based handling. It then takes full control of the device directly, handling all communication with the hardware in user-space. That removes transitions from user-space to kernel and back, improving latency and reducing processing time and context switches.
For redundancy and availability, the storage system leverages NVMe-oF multipathing to ensure continuous access to logical volumes by automatically handling failover between primary and secondary nodes. Each volume is presented with multiple active paths, allowing I/O operations to seamlessly reroute through secondary nodes if the primary node becomes unavailable due to failure, maintenance, or network disruption.
Copy-on-Write branches
One of Xata’s key features is instant branching, enabled by Copy-on-Write (CoW) at the storage layer. Here's a simplified mental model of how it works.
The storage system splits the data into data chunks. A metadata index keeps track of where the chunks are on the physical disks.
In this example, we start with a “main” branch and 8 data chunks.
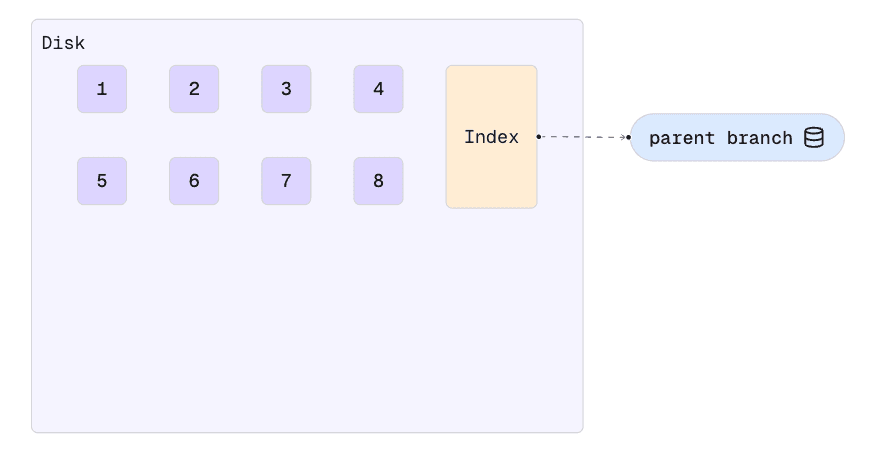
When a new branch is created, a new metadata index is created, but no data chunks are copied. The new branch’s index simply points to the existing chunks. This is why the branch operation is instant: it doesn’t (yet) have to copy any significant amount of data.
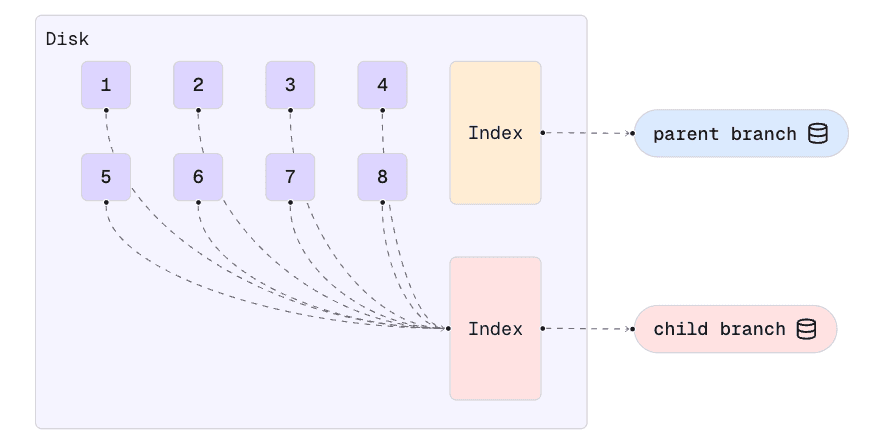
As writes are received, either by the parent or the child branch, the modified chunks are copied before the writes are processed. When this happens, each branch references its own copy of the chunk. In the following diagram, this has happened for chunks 3 and 6.
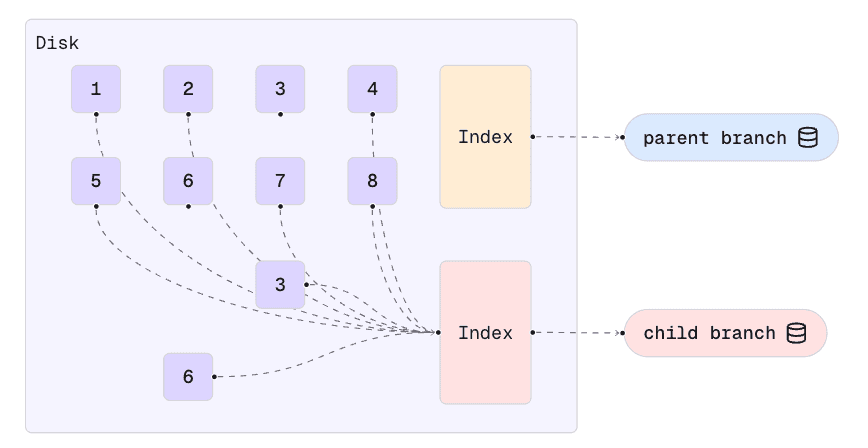
Note that all other chunks are still not duplicated. This is why it’s called Copy-on-Write: the data chunks are only copied when the first write in them is processed.
Assuming that relatively few chunks are written after the branch operation, this can result in significant disk space savings between development branches.
Compute: Kubernetes and CloudNativePG
On the compute side, we keep things fairly standard: we deploy the Postgres instances on Kubernetes via the CloudNativePG operator. CloudNativePG is one of the most stable, feature rich, and popular operators for PostgreSQL on Kubernetes. The operator provides the base for many of the production concerns: high-availability via synchronous replication, read-replicas, scaling up and down, minor version rolling upgrades, backups, and so on.
This means that our data plane is cloud agnostic and we can deploy anywhere there is a Kubernetes cluster. It enables our Bring Your Own Cloud (BYOC) deployment model, in which we deploy the Xata plane in your cloud account or your data center.
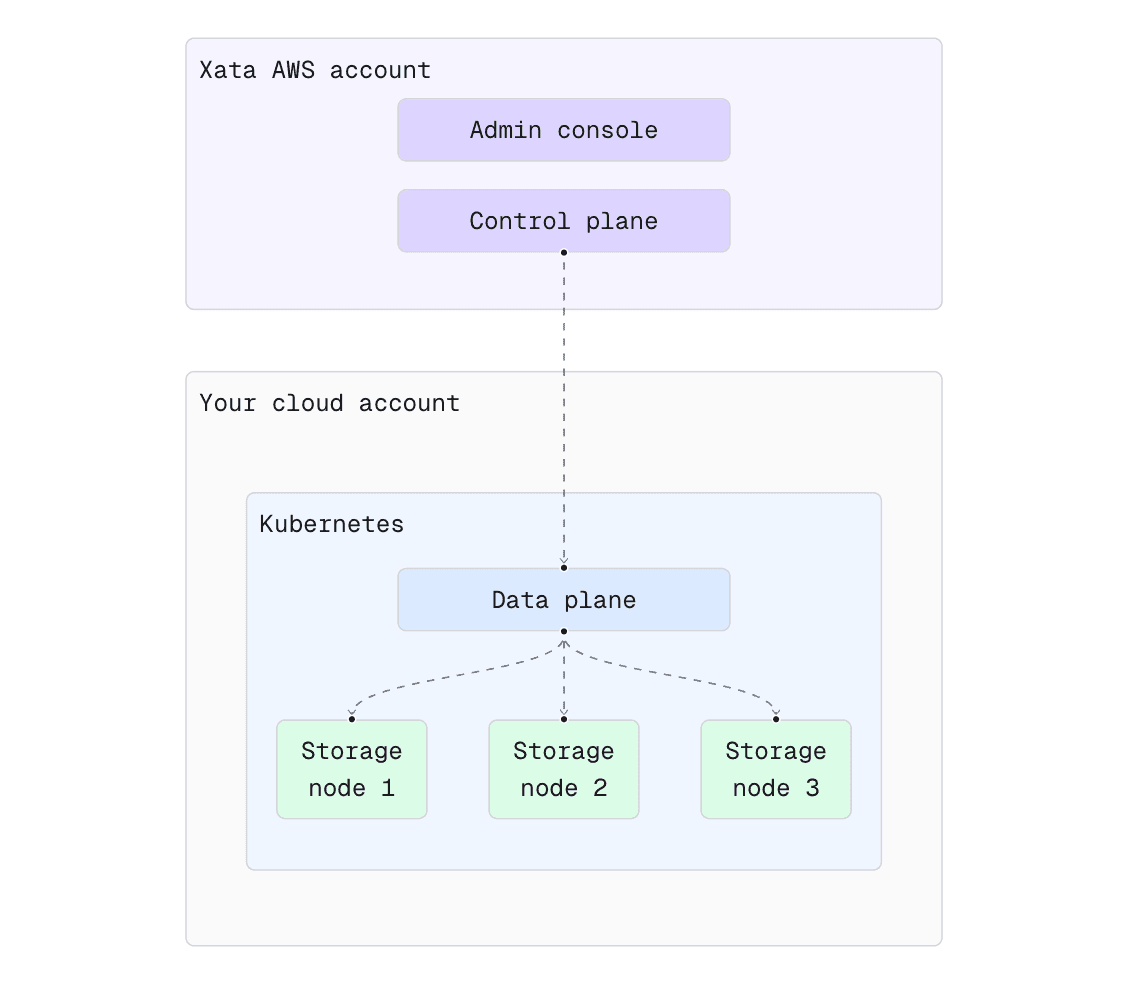
Besides offering the best security and compliance posture, BYOC means that you can use the credits and discounts from your Cloud provider to run the infrastructure used by Xata. It also means that the Postgres nodes are running in your VPC, minimizing latency and bandwidth costs.
Postgres optimization and tuning with the Xata Agent
As we said we’re keeping the compute layer standard, and we’re running vanilla versions of Postgres. This means that all your favorite tools will just work with it.
It also means that we can make use of another open-source project of ours, the Xata Agent, to monitor, diagnose, and optimize the PostgreSQL instances. The Xata Agent is an LLM-powered agentic expert in PostgreSQL.
It combines reasoning models with tools giving the model access to the metrics, logs, active queries, statistics, and settings of your Postgres instance. The Agent helps you optimize your queries and help you tune your Postgres instance.
Xata Lite: Free Postgres for builders and AI agents
If you are an existing customer or free user of Xata, you might be wondering what will happen to the classic Xata platform that you are using now. In short: it is renamed to Xata Lite, it gets a new website, but otherwise remains unchanged both in terms of functionality and pricing.
Xata Lite uses a shared Postgres clusters implementation, which allows us to offer Postgres with a very generous free tier. As of right now, the current underlying Postgres service for Xata Lite is Amazon Aurora, but we will be migrating it to use Xata instances ourselves.
The separation between the two platforms looks like this:
- Are you looking for a simple, serverless, no-frills Postgres hosting for your side project, prototype, non-profit or vibe coded app? Xata Lite offers a generous free tier and per-storage pricing.
- Are you a Startup, Scaleup, or Enterprise that is running Postgres at scale? Then the new Xata Postgres platform brings you all the benefits outlined by this blog post.
How to get started
We are currently gating access to the new Xata Platform as we onboard our first major customers. However, the platform is production-ready, we just want to focus on providing the best possible experience for a limited number of customers.
If you’d like to explore whether Xata can help you, please request access here. We’ll reach out to you to discuss next steps.
If you just find Postgres at scale interesting and you’d like to follow along, you can find us on X, BlueSky, or LinkedIn.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.