Inside Xatastor: ZFS + NVMe-oF for millions of Postgres databases
Read the technical details of our new distributed storage system, which is the key to scaling to a huge number of Postgres instances.
By:
Tudor GolubencoPublished:
Reading time:
8 min readAt Xata we run a Postgres service offering fast database branching and scale-to-zero. It happens to be great for enabling coding agents to work with realistic data without needing direct access to the prod DB. This way LLM hallucinations can’t oops the prod database, like we’ve seen happen more and more often lately.
There is also a new generation of dev, cloud, and AI platforms that require a database-per-tenant architecture. They often offer free tiers or inexpensive plans for which the cost of “ephemeral” (scale-to-zero) databases are a critical consideration.
This new level of demand put pressure on us to support very large numbers of databases and branches in the most cost efficient way possible. It is why, after having worked and operated several other distributed storage systems, we decided to create our own.
The new storage system is called Xatastor, and is the secret sauce of the Xata Cloud platform.
Our storage journey and learnings so far
When we started working on what became the current iteration of Xata, we knew we wanted copy-on-write branching and to use vanilla PostgreSQL without modifications. These two requirements together pretty much meant that we needed some sort of separation of storage from compute at the block device layer. In other words, some sort of distributed, software-defined, storage.
We’ve evaluated a bunch of options in the space, both open source and commercial: Ceph, LongHorn, OpenEBS, SimplyBlock, Portworx, Lightbits, and more. We initially chose a commercial solution but eventually we wanted more control over the storage system so we switched to an open-source project: OpenEBS with Mayastor.
Small side-note: even with the release of Xatastor, we continue to use OpenEBS / Mayastor in production and it is what we usually recommend for open source and on-prem installs. We found it reliable and easy to operate and I would generally recommend it for K8s native storage.
What multiple of these projects have in common, is that they use SPDK internally. SPDK is a development kit from Intel and it’s one of those rare pieces of software that you would describe with a single word: a beast. Skim through their performance reports and see that it’s capable of transporting millions of IOPS over the network with latencies measured in micro-seconds. It is what enabled us to compete with local storage in the benchmarks we did last year.
To transport bytes over the network at those speeds, SPDK uses a protocol called NVMe-over-fabrics (NVMe-oF). It is a protocol specifically designed to keep the advantages of NVMe (massive parallelism, command set matching SSDs) and export them over the network. It is quite the beast by itself. The SPDK provides its own user-space implementation of it, which enables these fancy storage solutions.
While SPDK-based solution are impressive, we’ve learned that SPDK is optimized for very high performance on a relatively small number of busy volumes. A lot of its defaults and design decisions are oriented towards that use case. Unfortunately, they tend to have issues when dealing with a very large number of volumes. A few hundreds volumes per node is perfectly fine, but reaching thousands per node is already a challenge. This ultimately results in a costly system to operate.
In short, SPDK-based solutions optimize for a small number of very busy volumes. Our main use case is the opposite: a very large number of mostly idle volumes.
Xatastor - goals
Given the learnings above, it became clear that if we were to scale to millions of databases and branches, we needed to work on a custom storage solution. With the knowledge we gained by operating the other storage engines, we had a good handle on the main tradeoffs, the failure modes, the cost implications, and the operational aspects.
We set for ourselves the following goals:
- Highly scalable in terms of volumes per storage node. We were targeting over 100K volumes per storage node.
- An inactive volume (from a scaled to zero Postgres) should take no resources at all except for disk space.
- Copy-on-write snapshots and clones features. Thin provisioning so we can charge only for actual usage.
- Built on top of proven technologies with mature tooling. Simple architecture with the minimum amount of moving parts.
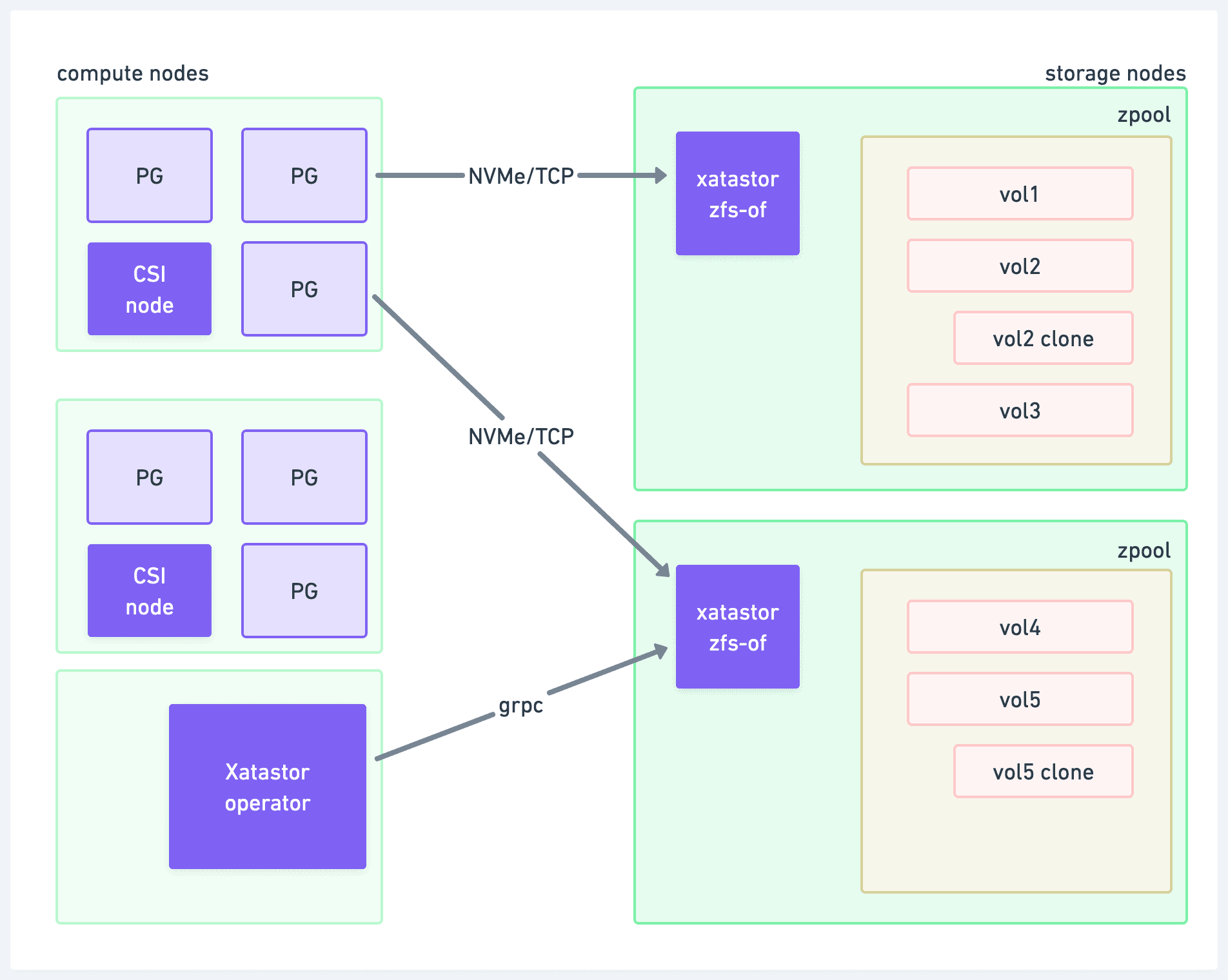
Xatastor - exposing ZFS zvols over NVMe-oF
In short, Xatastor is implemented like this:
- ZFS pools of volumes (zvols) exist on the storage nodes.
- Our own user-space implementation of NVMe-oF exposes them over the network.
- Our Xatastor Kubernetes operator serves as the control plane.
Let’s go through each of the key components.
ZFS pools of volumes (zvols)
Interestingly, we don’t actually use ZFS as a filesystem, but rather only the bottom layer of zvols. A zvol exposes a ZFS dataset as a block device (e.g. /dev/zvol/pool/name). Since we mount these over the network, the client is responsible for the filesystem and mounting. We happen to use XFS as the filesystem. This means that Postgres and the compute pods are completely unaware of the ZFS layer.
Zvols offer a lot of the key functionality that we want:
- Snapshots and clones
- Thin provisioning
- Data integrity via checksums
- Compression
Equally important, ZFS is highly scalable when it comes to the number of volumes. A single node can store hundreds of thousands of volumes, snapshots, and clones.
At high scale, a few operations need care. For example, zfs list becomes slow with many datasets, and we need to run it (or its equivalent) on startup. Because we need the startup to be as fast as possible so we can do zero-downtime upgrades, we work around this by maintaining our own metadata store.
ZFS also has very mature tooling for administration, monitoring, moving volumes between storage nodes, and so on. This simplifies our operations significantly.
Implementation of the NVMe-oF protocol
Since we decided not to use SPDK, we had to create our own user-space implementation of the NVMe-oF protocol. It’s perfectly compatible with the Linux client implementation, so nothing needs to change on the client side.
From the implementation point of view, it is a Rust daemon using monoio (a thread per core) and an io_uring-based async runtime. Each worker thread owns its own TCP listener via SO_REUSEPORT, its own connection state machines, and its own buffer pool. So a connection's PDU parsing, NVMe command decode, ZFS read/write, and response framing all happen on one core with very little cross-thread synchronization on the hot path.
The little coordination that we need between the admin and the IO queues is done completely mutex-free, in order to avoid adding latency spikes in the IO queues.
The Xatastor operator
For the control plane we wanted to be as Kubernetes native as possible. There's no external metadata store: every volume, its placement, its NVMe-oF connect parameters, and its lifecycle state live in a cluster-scoped CRD (xvol) that you can kubectl get, watch, or describe like any other resource. Create, clone, snapshot, delete, and health monitoring all flow through standard Kubernetes APIs (PVCs, VolumeSnapshots, and the Xvol CR underneath).
Following the Kubernetes standards makes Xatastor fit well among the OpenEBS storage engines. From the user point of view, it is a drop-in replacement for Mayastor, which makes it easy to switch from one to another, or run them in parallel.
At the same time, having our CSI implementation allows us to implement custom workflows and a set of optimizations that enable very fast wake-up (scale to one) and branch times. But about that, we’ll have a future blog post.
Performance
The goal of Xatastor is to be a storage system that scales to a huge number of volumes with minimal cost. Our design didn’t optimize for single-volume benchmarks. We expected some performance penalties compared to SPDK-based solutions, because of ZFS overhead and the simpler NVMe-oF implementation.
However, in practice, the simpler architecture and clean implementation offset the expected overhead.
We’ll have a follow up blog post covering benchmark results, but in our tests so far Xatastor matches SPDK-based solutions on Postgres benchmarks, while requiring only a small fraction of the hardware resources.
Redundancy
So far in this blog post we haven’t written anything about redundancy. Mayastor, for example, allows storing multiple replicas of the same volume, with sync replication between them. The way this works is that the storage nodes run NVMe-oF proxies (called nexuses) to route writes between them. The nexus needs to wait for the acknowledgement from the replicas before acknowledging the write as successful. If a node is lost, a rebuild process needs to copy the data from a healthy replica to a new node.
We decided to skip all of this for a few reasons:
- Our workload is Postgres, which has its own replication mechanism via read-replicas. Our system has automatic failover in case of primary failures. This is the most trustworthy HA solution, and the right level to solve redundancy. We highly recommend all production workloads to add at least one read-replica, for more reasons than just redundancy: with replicas updates and configuration changes are rolled out via switchover, which mean significant less downtime.
- On our cloud regions, we use EBS in AWS and Persistent Disks in GCP, which provide their own internal redundancy. For non-production instances, or for prod instances that scale-to-zero, this means you get redundancy even without read-replicas.
- Write performance and cost. Redundancy at the storage layer via sync writes doesn’t come for free. It introduces write amplification, basically doubling the cost. Also, often the network bandwidth is the main constraint that we deal with, and the replication means more traffic over the network.
- Simplicity. This is maybe the biggest reason right now. Having replicas would mean a significantly more complex system, which for now we don’t think is justified for our particular use case.
Compression
We have many customers storing non-prod databases with multiple terabyte of data. An unexpected benefit of ZFS is that we can enable compression on a per volume basis. We’re seeing zvol compression of 40-50% in some cases, which translate in significant cost savings.
Conclusion
Xatastor is a cloud native software-defined storage engine that enables the level of scalability that is required in the agentic era.
If you are working on a web, cloud, or AI platform that would benefit from offering a Postgres instance (or more) per tenant, don’t hesitate to reach out.
Also: if you are an engineer that enjoys this type of system-level challenges, we are hiring!
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Introducing Xata OSS: Postgres platform with branching, now Apache 2.0
Xata core is now available as open source under the Apache 2 license. It adds copy-on-write branching, scale-to-zero compute to Postgres.
What if database branching was easy?
We usually think branching means copying the whole database. With copy-on-write, it doesn't. Let's compare workflows like seeding to DB branching.
Database branching for AI coding agents: a minimal, CLI-first setup that actually works
Learn how to enable database branching for coding agents like Claude Code and Amp Code using simple Xata CLI instructions in AGENTS.md. No complex skills required.