From DBA to DB Agents
Discover how a PostgreSQL DBA’s decade of expertise evolved into designing Xata’s AI-powered Postgres agent, automating monitoring and observability.
By:
Gulcin Yildirim JelinekPublished:
Reading time:
14 min readI recently gave a talk titled “What Years of DBA Experience Taught Me While Building an LLM-Based Postgres Agent” at Diva: Dive into AI, a conference organized by the Kadin Yazilimci (Women Developers) community in Istanbul. As one of Kadin Yazilimci’s co-founders, I’m proud to have launched Diva in 2023 and to see it grow each year. Xata has proudly sponsored the conference for the past two years (yay!) and preparations for Diva 2026 are already underway thanks to our amazing volunteers. Stay tuned!

Diva: Dive into AI, July 2025, Istanbul
After more than a decade working with PostgreSQL, first as a DBA and now building LLM-based infrastructure tools, I’ve learned a few things worth sharing. This post is the blog version of my talk where I walk through how we built an AI-powered Postgres agent at Xata and the DBA lessons that shaped it. If you’d rather skip the reading and jump straight to the presentation, you can find it here.
My journey with Postgres
I started my journey with PostgreSQL in 2012 when the DBA’s job was still deeply hands-on: tuning queries manually, meticulously planning upgrades, setting up reliable backups and working closely with developers to help them write better queries. While a lot of tooling has improved, the instincts we developed back then are still extremely useful today, especially when building systems to automate some of that work.
The world of the classic DBA
Back then when people asked me “What does a PostgreSQL DBA do?”, my answer was something like:
- Install and configure Postgres
- Monitor metrics, logs and system health 24/7
- Manage backups and recovery plans
- Tune queries and indexes for performance
- Handle upgrades and migrations
- Manage locks and complex schema changes
- Automate repetitive tasks with scripts and tooling
It was a role that required both deep database knowledge and broad systems awareness. Database administrators would sit in the same room (remote work was unheard of) with system administrators and were solely responsible for the database. There was no such thing as “Managed Postgres”; you installed your own PostgreSQL, handled every upgrade, maintained it yourself and kept track of everything. Over time, this specialized role began to evolve.
The first shift: DevOps and automation
Paradigm shifts occur when the dominant paradigm under which normal science operates is rendered incompatible with new phenomena.
Change in science and technology is inevitable and no knowledge ever truly disappears, it simply transforms and evolves. As Thomas Kuhn noted in The Structure of Scientific Revolutions, paradigm shifts occur when new phenomena make old approaches incompatible. For DBAs that shift arrived with the rise of DevOps culture which brought new roles like Platform Engineering and Site Reliability Engineering.
Technologies like Docker and Kubernetes quickly became part of our daily vocabulary. While creating virtual machines (VMs) used to be considered innovative compared to physical servers, over time container-based architectures and platforms like Kubernetes became the new standard. This transformation has allowed infrastructure to become more flexible, scalable, and easier to manage automatically.
Ansible’s Playbook concept
The software automation and orchestration tool Ansible introduced the idea of defining configuration as data through YAML files. This approach helped popularize concepts like Infrastructure as Data and Infrastructure as Code, making infrastructure management more predictable and repeatable.
At the core of Ansible is the Playbook, a file that contains one or more Plays. Each Play has a list of Tasks, and each Task typically calls a Module to perform a specific action. Playbooks help organize tasks in a structured way. When things grow bigger, Roles help you organize Playbooks into reusable, modular components.
Suddenly, we could manage hundreds or thousands of systems in a consistent and automated fashion. I was a big fan of Ansible and my first ever PGConf.EU talk was on “Managing PostgreSQL with Ansible” in 2015, in Vienna. At the time I was working at 2ndQuadrant and had started automating my daily tasks with Ansible, writing YAML and some Python. Eventually, this became my full-time job and I began working on the (now open-source) Trusted Postgres Architect (TPA) project and my title evolved into a Site Reliability Engineer from a DBA.
Old ways of ensuring uptime
So, how did we actually keep systems up an running? If you’ve ever worked in Ops or as an SRE, this will sound familiar. In his blog, “Are AI agents the future of observability?”, Tudor explains it well:
- Collect heaps of metrics, logs, and traces (the famous three pillars of observability).
- Set up monitors with warning and alert thresholds. Sometimes combined with ML-based anomaly detection.
- Define on-call schedules for 24/7 coverage. If a monitor hits the alert threshold, an on-call engineer gets paged.
- Create dashboards in a visualization tool to quickly review many related metrics at once and notice correlations.
- Use playbooks, table-top exercises, chaos testing, postmortems, incident management tools to improve the confidence of the on-call engineers.
- Define, communicate, and measure your service objectives and agreements (SLO, SLA) in order to guide alert thresholds and give engineers some leeway.
Most companies implemented similar processes because they worked but at a cost. Observability tooling often became one of the largest infrastructure expenses and weekend or nighttime on-call shifts were some of the most stressful parts of an SRE or platform engineer’s job.
I lived with a pager for most of my career (until about four years ago). While I believe on-call duty is a powerful teacher, showing where systems fail, where customers struggle and where to focus improvements, it is also undeniably stressful.
I often think about how robots are used in environments too dangerous or inhospitable for humans: mines, caves, underwater or even in space so humans can oversee their work from a safe distance. I see on-call duty in the same light for our industry. Wouldn’t it be great if we could delegate night shifts, weekend shifts or even all shifts to something that doesn’t need sleep or family time? Do we really need to wake a human for something the system could detect, investigate and resolve on its own?
How an AI agent can help
Let’s imagine a scenario where you’re woken up, none of your daytime colleagues are around and you’re facing an issue you’ve never seen before with a critical system for a major customer. Depending on where you are in the escalation chain, you might be the first one paged or there might be another engineer before you who has already investigated, gathered some info and handed it over to you and now you’ll have to digest all of that and see what you can do next. Or maybe this is a handover from the previous shift and you’re taking over a pile of issues at different stages: waiting on customer info approval, running scripts to see what went wrong, grepping logs, reading through ticket comments or hopping on a call while connecting to another client environment.
You’ve never faced this specific issue before but likely some of your colleagues have. If you could quickly find that information in an internal knowledge base, you might solve this problem much faster. The reality, though, is that the relevant details are often scattered across multiple sources: a post-mortem from a past incident, a buried comment in a long ticket thread or a Slack conversation in a channel you don’t even have access to. And at 3 am, when you’re low on motivation and cognitive power but still bound by a service level agreement, that’s not easy.
Now imagine, an AI agent on-call 24/7, escalating to humans only when necessary. Before paging you, it would investigate incidents using team-written playbooks, past incident records, and recent code changes and if needed generates its own playbook by searching the web, checking dependency status pages and consulting documentation. In self-recovering cases, it simply monitors until stability is confirmed. For low-risk fixes (like scaling up a resource) it could act automatically. Risky or uncertain cases would trigger a human page but with a ready-made summary of the situation, likely root cause, and suggested actions. Finally, it would document the incident for future reference. Would not it that be better for all the parties involved in the incident?
The big idea
We’ve talked about how the traditional DBA role has evolved with many of the DBA responsibilities now falling on (relatively newly) formed platform and SRE teams but the need for deep Postgres expertise hasn’t gone away. So we asked ourselves: What if we could bottle up a DBA’s years of experience into an LLM-powered agent not to replace them, but to scale their expertise across hundreds of clusters, anytime?
That’s exactly what we’re doing with the Xata Agent. Beyond its built-in general knowledge, it’s equipped with tools and playbooks from top Postgres experts and we’re battle-testing it daily on tens of thousands of active databases. Each incident improves a playbook or adds a new one, many of which work with any Postgres installation. We’re building a community library of these under an Apache license and inviting contributions. SREs can even write their own “infrastructure software” in plain English telling the agent which tools to run and when.
Designing the Xata Agent
We originally built Xata Agent as an internal tool to manage our many Postgres clusters following the same principles a human DBA would: analyze SQL, study logs and metrics, and reason about them using an LLM.
At its core, the Xata Agent is built around three concepts:
Playbooks: The operational “recipes” that define how to detect, diagnose and resolve issues. The Agent comes with a handful of pre-built playbooks that cover common PostgreSQL scenarios but we also but we also recognize that every company, business and database is unique. That’s why we support custom playbooks, giving you the ability to create your own, fork one of ours, or even generate them from natural language. This is the first step in building a library of workflows tailored to your environment. Looking ahead, we’re working on custom tools via MCP and envision an agent that can author and refine its own playbooks over time.
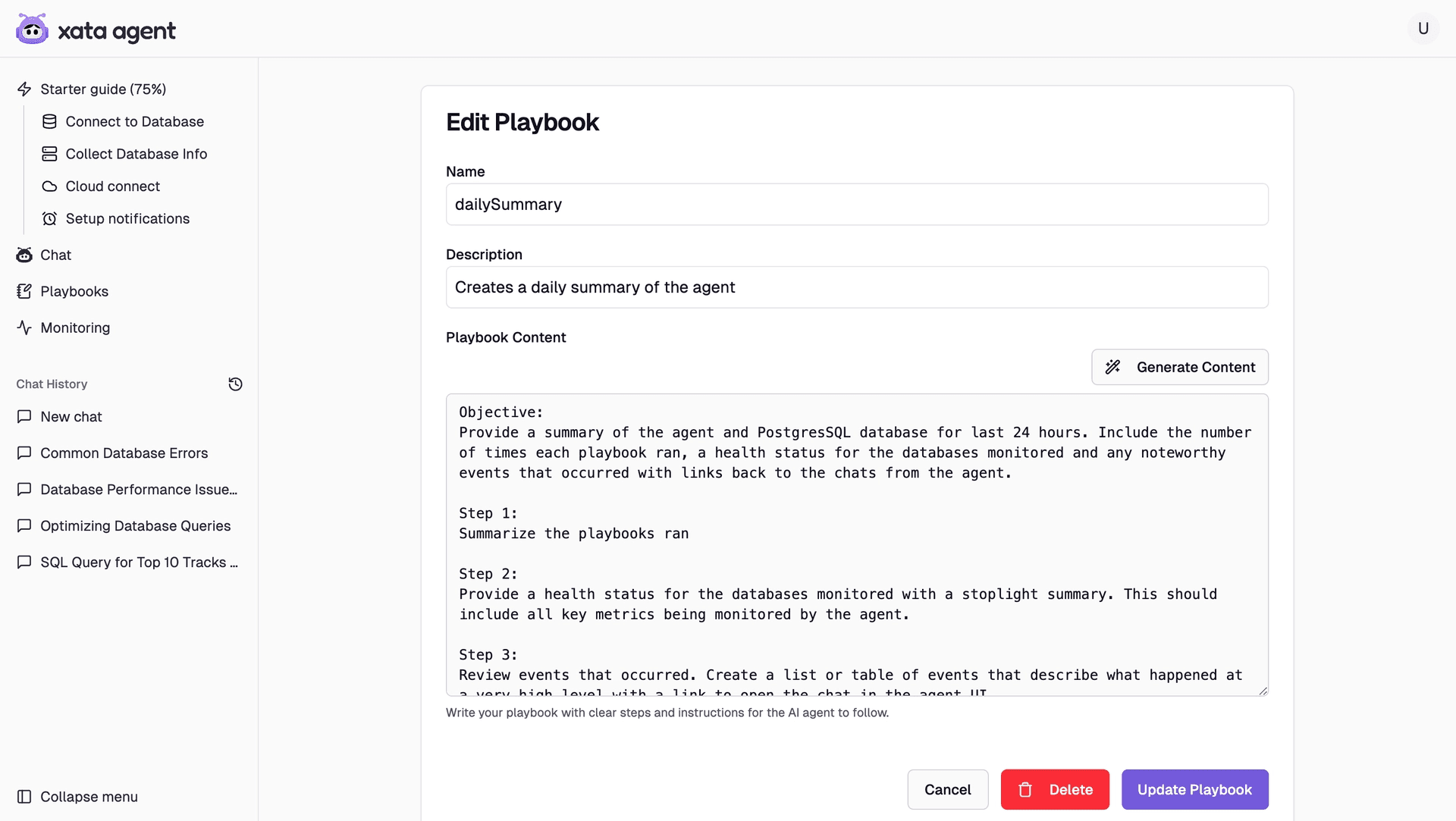
Create a custom playbook or generate one from a description
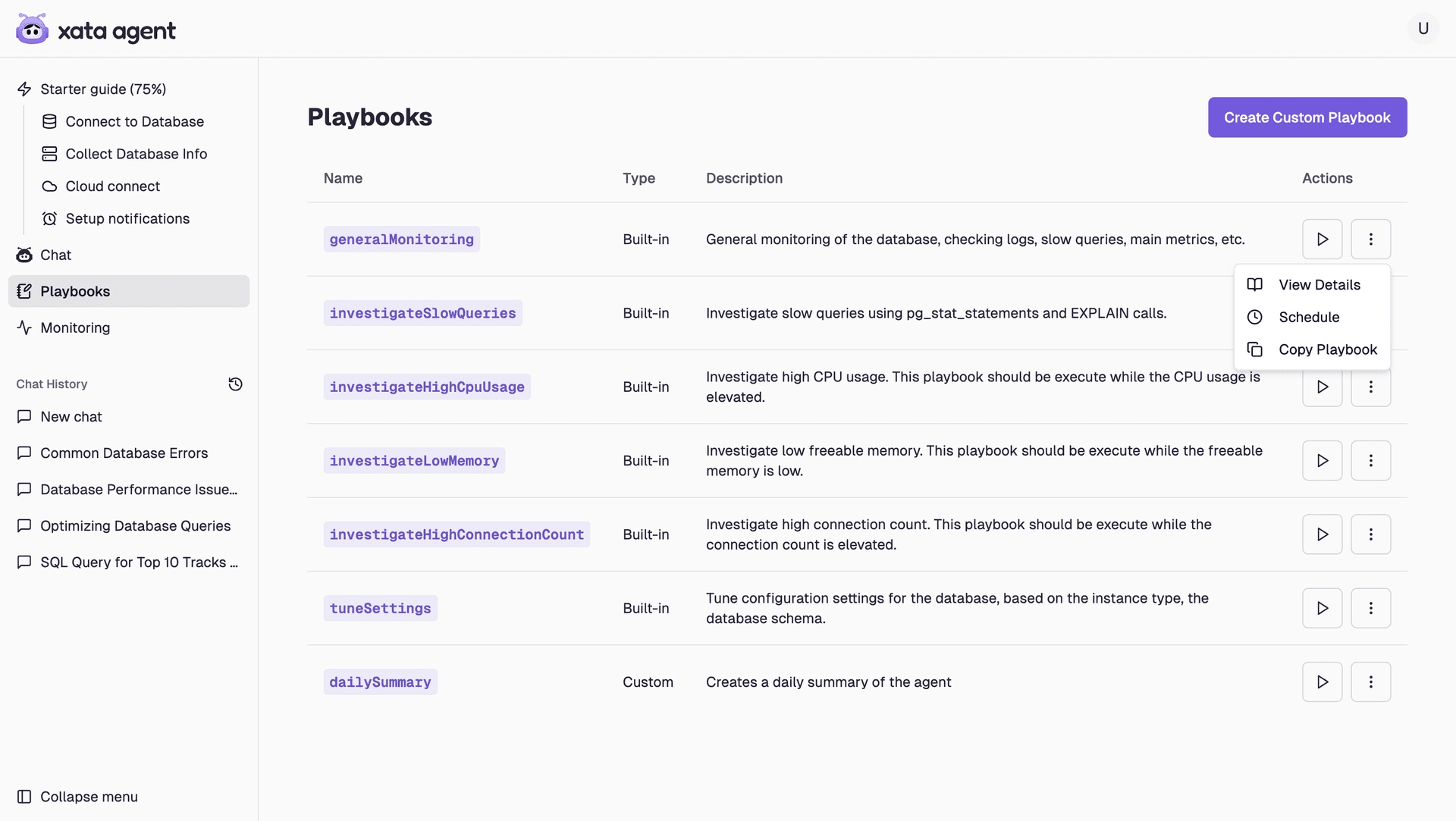
Easily fork a playbook and make it your own
Schedules: Cron-like expressions that run playbooks proactively at optimal times. Traditional DBA, SysAdmin and Platform roles have long relied on cron to schedule maintenance and administrative jobs and the Agent offers the same ability. You can schedule playbooks at specified intervals or let the Agent determine the best time to run them.
Tools: These are the building blocks the agent can call on: safe SQL checks, metrics collectors, config inspectors, log analyzers, and integrations with external systems. Just like humans relied on monitoring and admin utilities, the agent has its own toolkit. You can also extend the Agent’s toolkit with custom tools provided through integrations or MCP servers.
When you put these together, you get an agent that can reason about the state of a database, run the right playbook at the right time and use the right tools to actually fix things.
The future of the Xata Agent
Any sufficiently advanced technology is indistinguishable from magic.
Arthur C. Clarke’s famous Third Law is a great fit to describe the advancements we see with AI but as anyone in the field will tell you, none of this is actually magic. My former boss and mentor Simon Riggs used to begin his trainings with this very quote. At the end he would remind us: “None of this is magic. All of it can be learned and now you’re equipped with the knowledge to do some magic yourself.”
So where do we go from here? Our vision is to move beyond “assistive” workflows into something closer to a self-optimizing database.
Here are a few areas we’re actively building toward:
- Approval workflows via GitHub: The agent can propose changes (like schema optimizations or query rewrites) that go through a pull request, so humans stay in the loop while letting the agent do the heavy lifting.
- Custom workflows through MCP servers: We’re making the agent extensible so teams can define their own observability and recovery workflows in natural language.
- Safer operations: By introducing guardrails and “gated workflows,” the agent can handle higher-risk actions in controlled, auditable ways.
Database agents are having a moment
We're not alone in thinking about this space. There's a growing market of database tools and agents, each tackling different parts of the lifecycle. Some focus on development, some on observability and some on analytics. But to my knowledge, very few focus on DBA-type of workflows.
Here’s what others are doing:
- Neon reports that more than 80% of its databases are now auto-created by AI agents, and they provide their own MCP server for integrations.
- Supabase has rolled out AI Assistant v2 inside the dashboard, helping with schema design, SQL generation, debugging and even policy recommendations.
- ClickHouse is experimenting with analytics agents (ClickHouse.ai) and conversational query agents (AgentHouse) plus an internal LLM (“Dwaine”) for company-wide insights.
Why now? The growing market
The timing isn’t accidental. The database market is booming, estimated at about $70B in 2024 and projected to nearly double by 2030, reaching between $130B and $185B. That kind of growth reflects just how central databases have become and Postgres in particular has emerged as the backbone of AI-native workflows from vector search to real-time analytics.
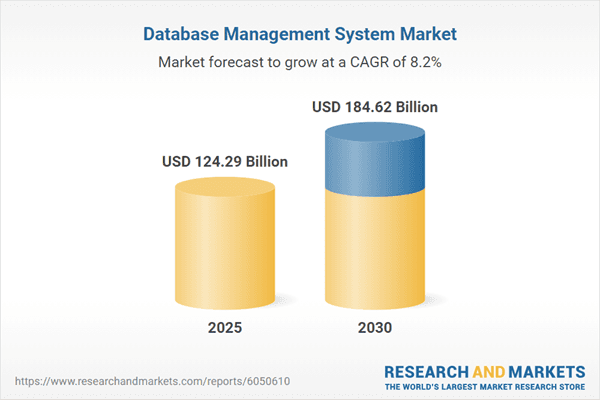
The DBMS market is projected to grow at a CAGR of 8.24% from US$124.291 billion in 2025 to US$184.623 billion by the end of 2030.
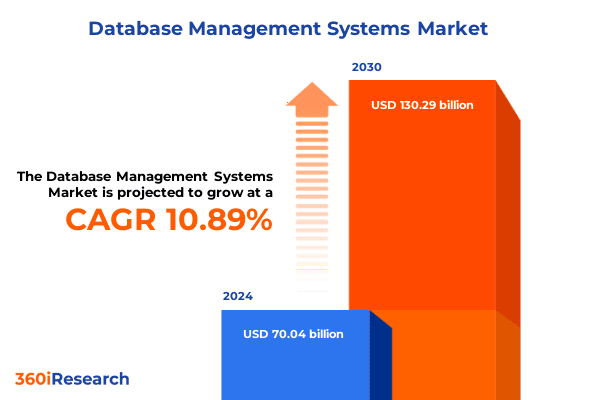
The DBMS market size was estimated at USD 70.04 billion in 2024 and expected to reach USD 77.49 billion in 2025, at a CAGR 10.89% to reach USD 130.29 billion by 2030.
At the same time, engineering teams have less time and fewer people. Development cycles are shorter, cloud bills keep growing and monitoring tools have become overly complex. All of this makes AI agents a natural fit, we need smarter tools to keep up with the pace of modern systems.
Testing an AI agent is not like testing normal code
One of the first lessons we learned is that you can’t test an LLM-based agent the same way you’d test a piece of traditional software.
With regular code, once a function passes its unit tests, you can be reasonably confident about its behavior until the code changes. But with LLMs, outputs can shift when prompts, context or the underlying model version changes. That means we need a different approach.
This is where evals come in.
An eval is like an integration or system test, but tailored to LLM behavior. It traces the agent’s reasoning step by step and compares outputs against expected outcomes. For example, if the agent is supposed to diagnose a slow query, we run evals to see if it still produces the right root cause and safe suggestions after a model upgrade.
Without this, you risk “silent regressions”, the agent passing yesterday but failing tomorrow, with no code change on your side. If you’re interested in the topic, you can check out my colleague Richard’s blog post.
Where AI shines
One of the things AI does best is explanation. Instead of just throwing numbers at you, it can walk you through why a query is slow and what you can do about it.
In our experience, the agent is strongest in situations like these:
- Explaining why a query is slow, in natural language.
- Suggesting next steps that guide developers instead of dumping raw metrics.
- Supporting devs with SQL guidance, rewriting queries, pointing out better index usage or clarifying confusing error messages.
This is where the LLM’s ability to synthesize across logs, metrics and SQL really feels like an upgrade over traditional tools.
Where AI struggles
But there are limits. AI agents still struggle with tasks that require stateful memory like multi-step schema changes or with managing costs when LLM queries add up. Getting consistent behavior is also a challenge, remember the section on evals, the outputs can shift in ways that are hard to predict which is why evals are necessary.
In other words, AI is excellent at diagnosis and guidance, but you still want guardrails before trusting it with complex or potentially destructive changes.
The shift to autonomous agents
Back when I was giving talks on pgvector and building RAG apps with Postgres at my previous employer, I’d often ask audiences if they’d ever trust an AI agent to manage their production databases. Almost all of them said no. These days, more and more teams are starting to say yes.
Much like others, if you’d asked me two years ago “Would you trust an AI agent with your production Postgres cluster?” my answer would’ve been absolutely not. Today it’s more nuanced. With the right guardrails like sandboxing, human-in-the-loop approval workflows, careful evals agents can already help teams manage their database stack and more.
What’s really shifting is the mindset. Teams are more open to sharing operational data, self-hosted models are gaining traction for privacy and control and there’s growing emphasis on evaluating model behavior to better understand the reasoning behind actions of LLMs. Still, big questions remain: What risks are acceptable? And how much autonomy is too much? We’ll all learn more as the space matures, but one thing’s certain: the shift is already underway.
Challenges and next steps
Of course, building an AI agent for databases isn’t without challenges. Three big ones stand out:
- Privacy: To reason about issues, the agent often needs metadata like table names, log snippets or config values. When using external APIs, this raises legitimate concerns. For sensitive environments, self-hosted LLMs are a promising path forward.
- Cost: AI models aren’t free. But interestingly, we’ve found that even with premium LLMs, the overall cost is still lower than many traditional observability stacks which often balloon in price at scale.
- Safety: This is the biggest one. No one wants an agent to hallucinate or run a destructive command in production. That’s why the Xata Agent is sandboxed, it cannot run arbitrary SQL without explicit human approval. For higher-risk actions, we’re designing gated workflows where human review is mandatory.
The takeaway? These agents aren’t here to replace DBAs, SREs or developers. They’re here to make our jobs safer, less stressful and more scalable.
Looking ahead
I believe we’re at the beginning of a major shift. Database agents will soon move from being experimental side-projects to becoming first-class parts of database infrastructure much like monitoring, backups and HA are today.
And just like DevOps once transformed how we think about operations, AI agents have the potential to redefine what it means to manage data at scale.
Final thoughts
Douglas Adams once said:
Anything that is in the world when you’re born is normal and ordinary… Anything invented after you’re thirty-five is against the natural order of things.
For many, the idea of trusting an AI agent with production databases still feels “against the natural order.” I get that and I fall into that camp myself. But give it a couple of years and it might feel as ordinary as running kubectl apply.
We’re still early in that journey and that’s what makes it exciting. Thanks for reading to the very end! If you’d like to try the Xata Agent, contribute or just chat about databases and AI, I’d love to hear from you. You can always reach out to us to learn more.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Are AI agents the future of observability?
After vibe coding, is vibe observability next?
Xata Agent v0.2.0: Powered-up chat, custom playbooks, GCP support & more
Version 0.2.0 introduces a redesigned chat interface, customizable playbooks, support for monitoring PostgreSQL instances on Google Cloud Platform and various improvements across the board.
Xata Agent v0.3.1: Custom tools via MCP, Ollama integration, support for reasoning models & more
Version 0.3.1 of the open-source Xata Agent adds support for custom MCP servers and tools, introduces Ollama as a local LLM provider, and includes support for reasoning models O1 and O4-mini.
Writing an LLM Eval with Vercel's AI SDK and Vitest
LLM Evals - testing for applications using LLMs