pgroll is on a roll! We hit 5k stars on Github
Pgroll is an open-source, zero-downtime, reversible schema migration tool built exclusively for Postgres. We’ve reached 5k stars on GitHub!
By:
Gulcin Yildirim JelinekPublished:
Reading time:
9 min readI joined Xata in August 2024 (almost a year ago now!) and pgroll quickly became the project I ended up being involved with the most, mainly because I think it resonated with me the most. I worked as a Postgres DBA from 2012 up until 2017 or so. As many others would agree, database schemas are not static; they keep evolving as the projects evolve, mature, and change over time. The change is unavoidable but it also comes with some big implications, as most commands (I am looking at you, ALTER TABLE) related to schema changes (DDL commands) require an ACCESS EXCLUSIVE LOCK.
I would have loved pgroll on the days I had to execute DDL changes without worrying about causing downtime. I think pgroll's main promise lies in how it organizes these changes to minimize lock contention and reduce the risk of downtime. That alone would have been enough for me to try and integrate pgroll. But that's not the only thing, there is a software pattern called expand/contract and that's what we implement in pgroll. Thanks to this, you can actually serve both the current/old version of client applications and also the one you're upgrading to. This way, users won’t really notice what's happening in the background, as we keep updating the data (backfills) both ways. You can gradually upgrade the application and either complete the migration or reverse it if you don't like it for some reason.
This is pgroll in a nutshell but there is much more to it and we recently released v0.14. If you're interested, there is a nice blog post covering the latest changes included in the release.
However, today I'd like to celebrate a milestone we've achieved: we passed 5000 stars on Github! While that number alone may not fully reflect the success of the project, it’s a clear signal that people are using pgroll, appreciating our efforts and that definitely calls for a celebratory blog post!
A token of appreciation
As is customary, here’s that nice image showing the stars ⭐
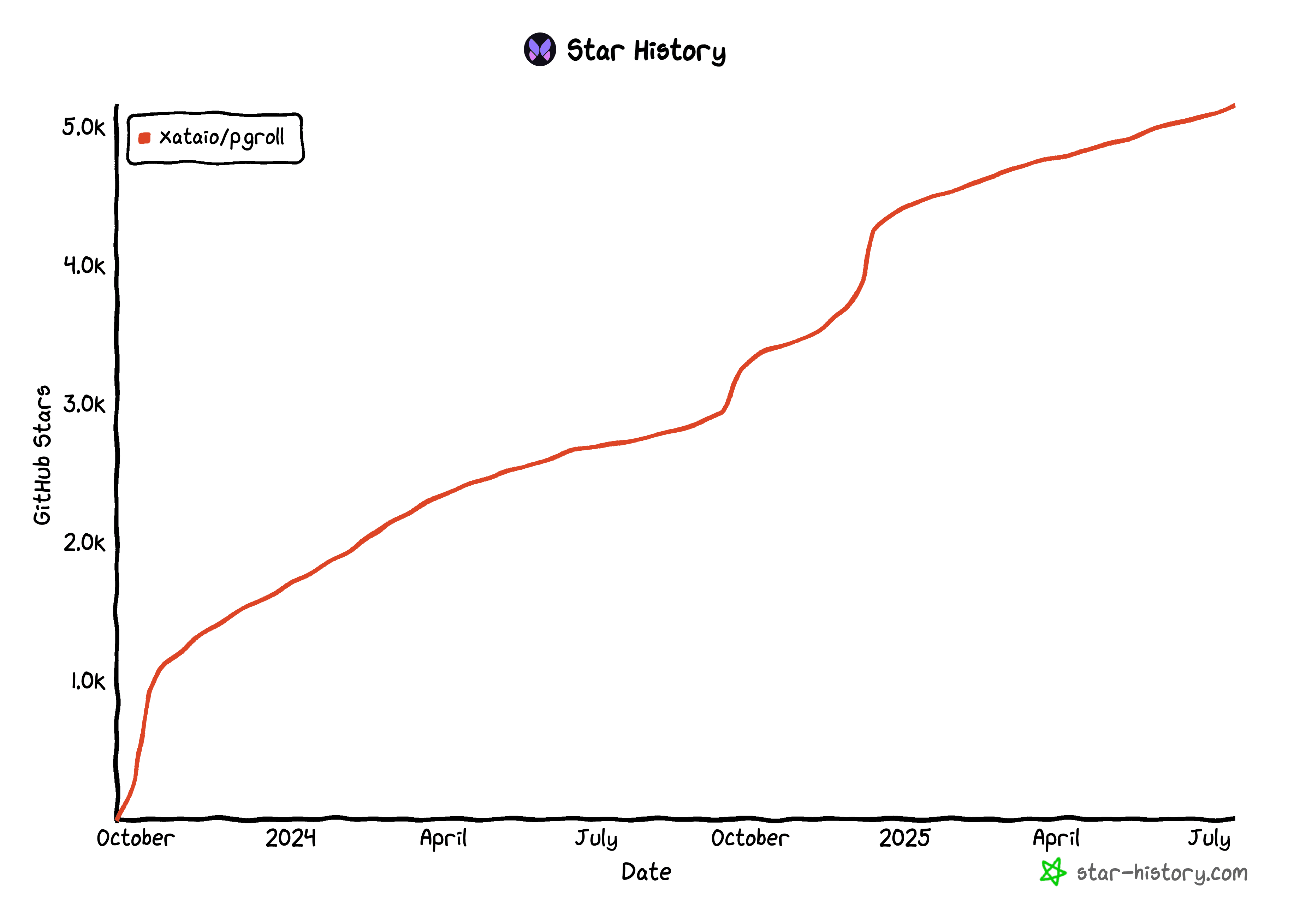
⭐ 5000 stars on GitHub, thank you for the love!
There are other metrics that show people are finding value in pgroll, other meaningful signals that our work is resonating with the community. One of them is the number of issues opened by people outside of Xata: 35% of currently open issues were created by folks not affiliated with Xata. We have 24 contributors listed on Github and 12 of them are also non-Xata folks. Of course contribution sizes vary but we're happy for every bit of feedback we get!
Speaking of feedback, one of the best and probably easiest ways to get it is by attending conferences, even more so if you're giving talks. This year, I was lucky enough to attend several conferences to present my talk, "Anatomy of Table-Level Locks in PostgreSQL". The talk is based on a two-part blog series I wrote earlier (part 1 and part 2), and I wrap up with a 5 to 10-minute introduction to pgroll. These experiences gave me a great visibility into what people expect from a schema migration tool, especially one built exclusively for Postgres.
I’ve collected the feedback and wanted to share it here, as it might be useful not just for other pgroll users but also for anyone interested in how people use Postgres with various tools and what they expect from them. The points I’ve listed are specific to pgroll, but they also provide context on how people interact with Postgres, what their setups look like, and how we might improve their development workflows.
Limitations of using views for multi-schema support
pgroll works by creating virtual schemas using views on top of the physical tables. This allows for performing all the necessary changes needed for a migration without affecting the existing clients.
In the Integrating pgroll into databases that use views issue, my colleague Noémi explains:
pgrollgives access to multiple schema versions by hiding tables behind views. At the moment,pgrolldoes not have a way to provide access to multiple versions of the same view.
Open questions
- Is this something we want to support?
Views are not materialized, so changing them does not qualify as an "unsafe" or tricky migration. The only use case I see for view support is when two application versions use the same view, but with different base query. So providing two versions of the same view could be useful.
- How to tell apart old and new version of the view?
We can add a new view to the new schema, similarly to tables.
While I was digging for issues that mentions views, I encountered Constraints not visible in latest migration schema and the final verdict is that to solve the problem mentioned in the issue, we would have to abandon the usage of views. So I wonder, what other limitations might people have based on our design choice of utilizing views? Let us know!
Is schema change history easily accessible?
pgroll stores its data in the pgroll schema. In this schema, it creates a dedicated migrations table to store migration history for each schema in the database.
And yes, pgroll makes it easy to access your complete schema change history. By running pgroll pull you can export all applied migrations into .yaml files. You can also export migrations in JSON format using --json.
If the target directory doesn’t exist, pgroll will create it. If it’s empty, all migrations are pulled from the database. If it already contains some files, only the missing migrations will be added.
So to summarize: pgroll tracks every migration applied to a schema, which makes it easy to audit changes, troubleshoot issues or simply understand how the database evolved over time. By maintaining this rich migration record in the database itself, pgroll ensures that teams always have a reliable, up-to-date view of their schema's lineage.
Since we get this question often, it's a good sign that we need to improve the documentation to make this point clearer.
Limitations of utilizing search_path
pgroll creates multiple versioned schemas in your database whenever you run a migration. To ensure your application uses the correct schema version, you set the PostgreSQL search_path to the desired version (e.g., public_02_add_assignee_column). This can be done in client code, connection strings, or pipelines. The versioned schema exposes views matching the expected tables and columns for that application version.
We recently introduced pgroll latest url , which generates a connection string with the appropriate search_path set to the latest schema version. If search_path is not set, PostgreSQL defaults to the public schema and your app accesses the underlying tables directly, not the versioned views.
pgroll also relies on search_path in its triggers to detect which schema version is being accessed. This can influence trigger logic during migrations.
There are some potential issues with relying on search_path in this way:
- Conflicts with existing app logic: Many applications may already use
search_pathfor other purposes leading to confusion or breaking changes when pgroll expects it to be set in a particular way. - Trigger logic:
upanddowntriggers rely on the value ofsearch_pathto determine whether a write came from the new or old schema version and decide whether they need to fire or not. This can be fragile if applications manipulatesearch_pathdynamically. - Complex multi-tenant scenarios: In some architectures, managing multiple schemas and
search_pathvalues for different app versions or tenants can be tricky.
At conferences, I expect at least one question about search_path and user feedback on Github issues has also highlighted the need for alternatives. We hear you and we've opened an issue to investigate alternatives to using search_path to distinguish schema versions.
Clarifying up/down migrations and their impact on performance
My guess is that the naming is confusing, so let's first talk about what an up and down migration actually is. In pgroll, up and down expressions are closely tied to triggers that maintain data consistency during schema changes especially when introducing breaking changes like new constraints or column types.
When you declare a migration operation (such as an alter_column), you provide both up and down SQL snippets, which pgroll uses to generate these triggers programmatically and attach them to the appropriate tables.
Up triggers have two roles. They are used at migration start to do the initial backfill of the new column, and once the migration has started and applications are writing to the table, they are used to migrate data coming into the old column into the new one. The logic for these triggers is defined by the up expression in your migration operation. For example, if you add a new column with a NOT NULL constraint, the up trigger will copy values from the existing column to the new one and apply any necessary transformation defined in SQL or PL/pgSQL.
Down triggers work in the opposite direction. When you’re rolling back a migration or updating data in the new schema version, the down trigger ensures that changes made in the new column are also propagated back to the old column. The logic here is defined by the down expression in your migration operation.
Let's talk about performance impact as this comes up often:
- Write amplification: Every data change during the active migration period may result in multiple writes due to triggers. This can slightly slow down write-heavy workloads, but pgroll batches backfills to minimize lock time and keep performance high.
- Consistency: Triggers ensure data consistency between schema versions, allowing old and new clients to interact with the database safely during migrations.
We actually have a guide that explains up and down migrations in more detail if you’d like to learn more.
Experiences with long running migrations
In the context of pgroll, a migration running "too long" typically means the migration's expand phase which includes backfilling columns, creating new views, and setting up triggers, is taking an extended time to complete. This could be due to:
- Large volumes of data to backfill (e.g., adding a
NOT NULLcolumn to a table with millions of rows) - Slow DDL operations due to resource contention
- Triggers and batching not keeping up with incoming writes
- Unexpected database load or locks
There are also people who’d like to benefit from testing their applications during this phase, while they have access to both versions at the same time, and deliberately choose to stay in this phase longer.
So what are the risks?
- Increased write latency: As triggers propagate changes to both old and new columns, write operations may get slower. In extremely busy databases, this could become significant.
- Prolonged dual-schema operation: The longer the migration runs, the longer the database maintains two versions. This can complicate application logic, monitoring and troubleshooting.
- Potential for lock contention: Although pgroll minimizes locks, some schema changes (especially involving indexes or constraints) may still cause contention. If the migration runs too long, even short locks may accumulate and impact other operations.
We have the pgroll status command, which displays the migration state for each schema whether there are "No migrations", a migration is "In progress", or it's "Complete". During backfills, we show information about the current batch being processed, the number of rows handled so far, and even estimate how much longer the backfill will take. You can also see when the backfill is complete and when the entire migration finishes. We also support dynamic adjustment of lock timeouts with the --lock-timeout flag.
That said, there’s still room to improve the experience. Support for pausing and resuming migrations could help with unexpected load spikes. There was also a great idea from a user to implement a dry-run workflow for migrations to estimate duration and resource usage before running it on production, an idea we're exploring on our new platform.
CI/CD integration – is manual intervention required?
The simple answer is no. In most cases, no manual intervention is needed. All pgroll commands can be automated and they are idempotent. You can run all steps init, start, complete and rollback from scripts. You can also use pgroll status to query the migration state and make decisions in your pipeline.
Conclusion
As pgroll grows, we’ll keep listening closely to the community. The feedback we receive continues to shape our roadmap. Some of the ideas shared with us are already in progress, and others are under active discussion. It’s been a rewarding year working on pgroll and I’m genuinely excited about where we're heading next.
If you haven’t tried pgroll yet, now’s the perfect time. And if you have: your feedback, contributions, and success stories are what keep us rolling forward (had to make one word joke 😄).
We’ve also brought pgroll into the Xata platform with a simple xata roll command, making safe schema changes even easier. If you’re curious to see how this works in practice, you’re welcome to join our private beta and explore what’s possible.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
pgroll 0.14 - New commands and more control over version schemas
pgroll 0.14 is released with several new subcommands and better control over how version schema are created.
pgroll v0.13.0: Start using pgroll on existing databases with the new baseline feature
The new baseline feature in pgroll v0.13 makes it easy to start using pgroll on databases with existing schema and keep your schema histories clean.
pgroll v0.12.0: create command, verbose mode & idempotent migrate command
pgroll v0.12 includes usability improvements like the new create command, verbose mode and idempotent migrate command
pgroll v0.11.0: YAML migration support, pgroll.migration table improvements & more
pgroll v0.11 includes support for YAML migration files, a fix for the bookkeeping of pgroll, and smaller usability improvements.
Anatomy of Table-Level Locks in PostgreSQL
This blog explains locking mechanisms in PostgreSQL, focusing on table-level locks that are required by Data Definition Language (DDL) operations.
Anatomy of table-level locks: Reducing locking impact
Not all operations require the same level of locking, and PostgreSQL offers tools and techniques to minimize locking impact.