Neon vs Supabase vs Xata: Postgres Branching Compared
Compare how Neon, Supabase, and Xata handle Postgres branching. Covers copy-on-write vs schema-only approaches, with architecture diagrams.
By:
Alex FrancoeurPublished:
Reading time:
13 min readIntroduction
As head of product at Xata, I’ve had a front-row seat into the recent (r)evolution of Postgres and the rise of database branching these last few years. Functionally, this capability mirrors the branching behavior in git allowing you to quickly clone or fork your data and schema alongside your application feature branch. With modern development practices and the speed at which agents are being adopted to build applications, the ability to branch a database has moved from a nice-to-have to a must-have.
Multiple platforms have emerged to tackle this, each with a unique approach. Neon popularized the idea of copy-on-write branches in Postgres, letting teams spin up full data copies in seconds. Supabase integrated database branching with git workflows, providing full-stack preview environments for every feature branch. With our new PostgreSQL platform at Xata, we’ve reimagined branching from the ground up to address the limitations we saw in existing solutions.
In this blog series I’ll compare the features, architecture and cost for Xata, Neon, and Supabase implementations. Because I go into a bit of detail, I’ll start each section with a comparison table and TL;DR for those of you that want the cliff notes.
Features
In this section, we’ll compare the different database branching and related features that each platforms supports.
TL;DR
All three platforms recognize the value of database branching, but they differ in both features and philosophy.
Feature | Xata | Neon | Supabase |
|---|---|---|---|
Branching types | Full schema + data (copy-on-write) branches | Full schema + data (copy-on-write) branches | Schema only branches |
PII and sensitive data | Built-in anonymization masking of PII and sensitive data | Masking possible through extensions or scripts | Masking is possible through seed scripts |
Isolation and creation time | Fully isolated and instant branches regardless of data size | Fully isolated and instant branches regardless of data size | Fully isolated and branch creation time dependent on seed scripts |
Merging schema changes | Built-in, zero-downtime merge of branch schema back to production | No built-in merge back to production, requires external tooling | No built-in merge back to production, requires external tooling and leans on code-as-truth |
Deployment flexibility | Managed cloud offering, BYOC and on-premise supported, built on open-source solutions | Managed cloud service only, core offering open source managed by you | Managed cloud service only, core offering open source managed by you |
Redundancy and HA | At both Postgres level and at storage level | At storage level only | At Postgres level only |
Compatibility | Unmodified Postgres | Modified Postgres | Unmodified Postgres |
Here’s a more in-depth overview of how Xata, Neon, and Supabase compare in these feature categories.
Branching types
Xata and Neon support instant copy-on-write branching that duplicates both schema and data. This means a new branch starts as a complete copy of the parent database’s data without physically copying it. Supabase’s branching, on the other hand, is currently schema-only. New branches include the schema and run migrations, but no data is copied from the parent. Supabase currently requires you to provide a seed script for the data. That could be random sample data or pulled from an existing database.
PII and sensitive data
Xata’s pipeline removes PII before branches exist. We use pgstream to replicate production into an internal staging replica, applying masking / anonymization rules during the initial snapshot and every subsequent WAL change. Because the replica already contains only scrubbed data, any branch you spin off that replica inherits the same protection automatically with no risk of an engineer seeing real emails or SSNs or PII ever leaving your prod environment.
Neon and Supabase have no built-in masking. Neon users typically install the open-source pg_anonymizer extension on a staging database and script a pg_dump → pg_restore workflow. It works whether production is on Neon or elsewhere but still requires exporting sensitive data out of production first. Supabase offers schema-only branches, so teams either rely on synthetic seed data or build a similar dump/anonymize/import process themselves.
Isolation and creation time
On all platforms, branch creation is effectively instant and the child branch is fully isolated from the parent. In Xata and Neon, this is achieved by copy-on-write at the storage layer. The new branch initially references the same data, and only deviates when writes occur. This means branch creation time does not depend on database size at all. A 1 TB database can be branched instantly on both Xata and Neon. A branch in Supabase depends on how fast migrations run and seed data loads. You pay the cost of applying DDL and inserting seed rows, which can take minutes to hours depending on your setup. Once created, changes in a branch don’t affect the parent.
Merging schema changes
Branching is only half the battle, eventually you want to merge changes to your schema back to the parent branch. Xata provides an integrated schema migration workflow that works with branches to facilitate zero-downtime schema changes (leveraging pgroll). Neither Neon nor Supabase offer an out-of-the-box solution for merging branch changes. With Neon, you typically apply schema migrations to the primary database manually (or with your migration tool / ORM) after testing in a branch. Supabase’s model relies heavily on your git workflow. When you merge your code branch to main, any new database migrations in that branch are automatically run on the production database.
Deployment flexibility
Xata can be run as a managed cloud service, in your own cloud (BYOC) or on-premises. Our new platform is cloud-agnostic. This optionality means you can keep data in-house or in-region for compliance purposes. It also allows you to use your existing cloud credits or pre-committed spend. The platform is built entirely from open-source solutions. Neon is a fully managed cloud service with its core technology open-sourced. Supabase is also a managed service with its core service open-sourced. Both solutions can be run in a self-managed fashion if you are willing to run, manage and support the infrastructure yourself.
Redundancy and HA
Xata offers double the protection at both the Postgres and storage layer with a Postgres replica set handled by CloudNativePG and an replicated storage cluster. If either a compute pod or an entire zone fails, a new pod mounts the same copy-on-write volume and traffic resumes in seconds with no data loss. Neon concentrates its HA logic in the storage engine. WAL is synchronously streamed to Safekeepers across zones and rebuilt by the Pageserver, so the data is always durable. If a stateless compute endpoint dies you just spin up another one, but in-flight sessions are dropped. Supabase has simple Postgres semantics with each branch having its own VM/container. You can add a read replica or enable PITR, yet fail-over and cold-start behavior remain per-branch responsibilities, making HA simple but largely self-managed.
Compatibility
Xata’s platform runs vanilla PostgreSQL with no proprietary forking, it supports all Postgres extensions and features out of the box. In contrast, Neon’s approach involves a custom storage engine and components, meaning they maintain a modified Postgres backend to integrate with that system. As a result, extensions that assume low level disk access might require modifications. Similar to Xata, Supabase operates standard Postgres, so most extensions that don’t conflict with their platform can be used. From a developer’s standpoint, all three should feel like Postgres, but when you’re 100% compatible you’ll never hit a weird edge-case of “oh that extension isn’t supported”.
Architecture
Underneath the hood, Xata, Neon, and Supabase employ very different architectures to achieve database branching. The design decisions at this level have big implications for performance, reliability, and cost.
TL;DR
Here’s a quick overview of the different ways each platform approached branching in PostgreSQL.
Platform | Architecture | Branch creation | Pros | Cons |
|---|---|---|---|---|
Stateless Postgres pods in Kubernetes via CNPG | Controller writes a new block-index, CoW at block level | 100 % vanilla PG, BYOC/on-prem, NVMe-class latency, built-in PII masking | Requires dedicated storage cluster, scale-to-zero in active development | |
Stateless compute streams WAL to Safekeepers to Pageserver | New timeline at an LSN, CoW at page level via WAL | Instant branches/PITR, scale-to-zero, active OSS community | Extra network hop means higher tail latency, overage costs, no managed BYOC | |
One full Postgres + Auth + Edge stack per branch | Forks schema, runs migrations, optional manual seed script | Simple “just Postgres”, whole backend cloned (auth, storage, funcs) for branches | Schema-only by default, heavy per-branch resources, cold-start after auto-pause, slow & costly to copy large datasets. |
That’s the 10,000 foot view, let’s go a bit deeper.
Xata
Xata’s new platform uses a decoupled storage and compute architecture similar in spirit to Aurora, but with a critical difference. We do it strictly at the storage layer, without modifying Postgres itself. On the compute side, we run unmodified PostgreSQL instances in containers orchestrated by Kubernetes, using the CloudNativePG operator for high availability and failover. On the storage side, we’re using a distributed block storage cluster accessible over NVMe-oF (NVMe over Fabrics).
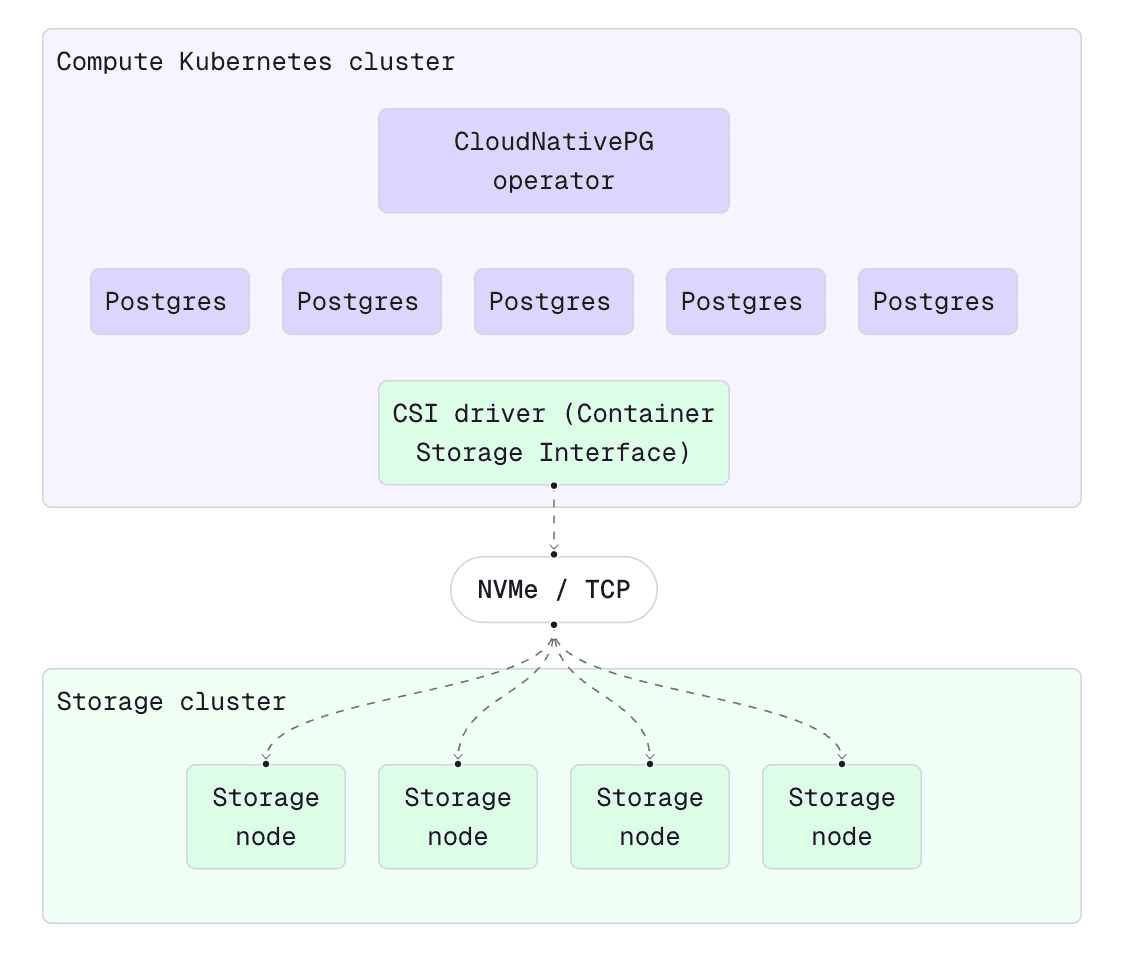
In practical terms, when a Xata Postgres instance writes to disk, it’s writing to a virtual NVMe volume backed by our storage cluster. That storage cluster handles replication, durability, and importantly copy-on-write branching at the block level. We mount and unmount these virtual volumes dynamically for each branch and database.
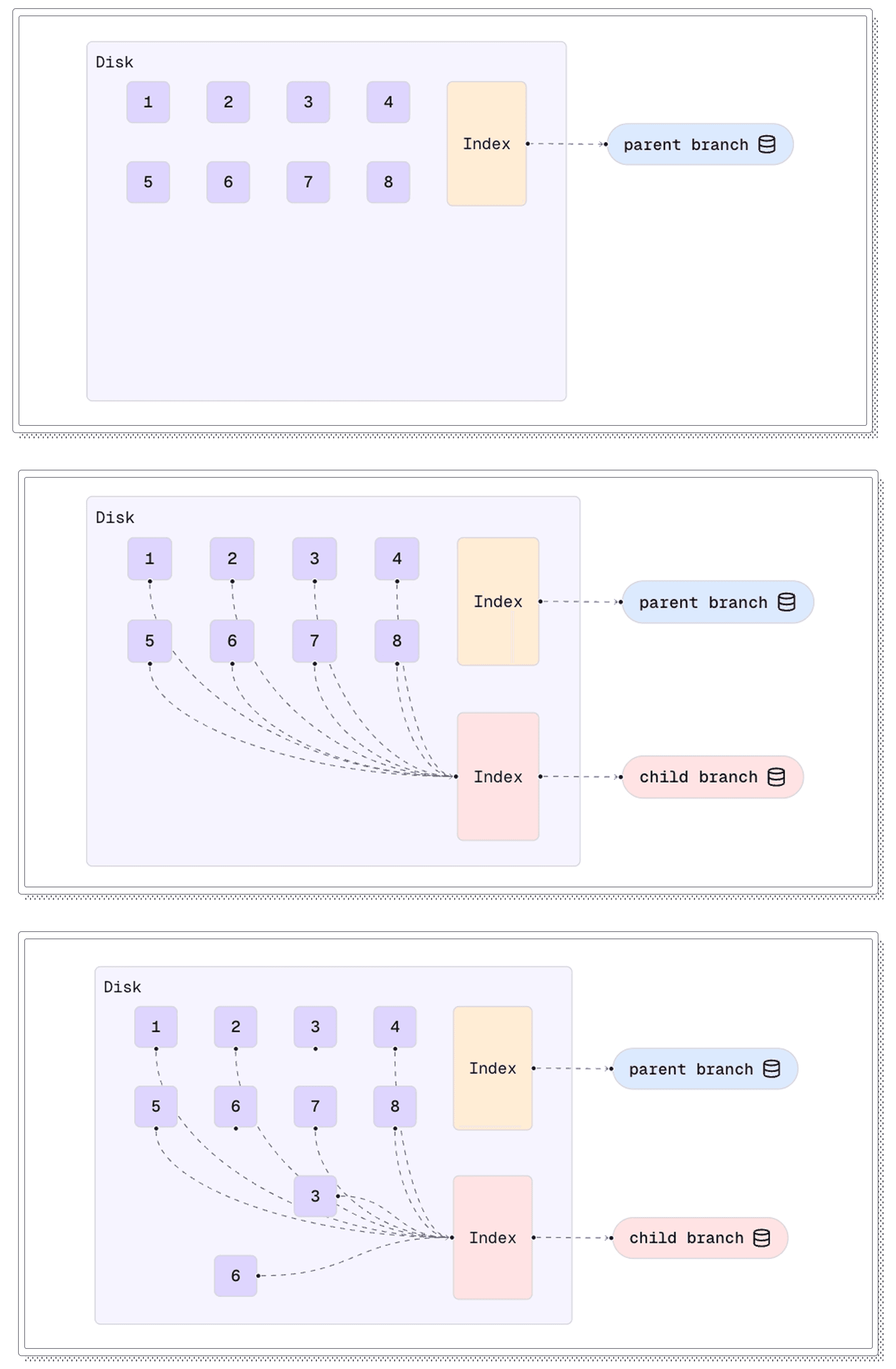
The copy-on-write mechanism works roughly like this. Our storage cluster breaks the database into chunks (data blocks). When you create a new branch, it creates a new metadata index that initially points to all the same data blocks as the parent. No actual data is copied, so it’s instantaneous. If neither the parent nor child branch makes any writes, they remain two “views” of the same underlying data. When a write does occur, the affected chunk is copied and written to a new location, and the child’s index now points to that new chunk. The parent keeps pointing at the original chunk. This is textbook copy-on-write (CoW). Only diverging data is duplicated, and only at first write. Most chunks remain shared as long as they aren’t modified, saving a ton of space when branches are short-lived or only lightly edited (which has become quite a common use case with AI agents). Here's a quick visual representation of that flow:
The benefit of Xata’s approach is that it behaves exactly like a normal Postgres instance, because it’s just Postgres, with CoW branching and elastic storage behind the scenes. We didn’t have to fork or alter Postgres to do this, and instead innovated at the storage layer and in orchestration. Our Postgres instances see what looks like a very fast disk. The heavy lifting of making that disk CoW-capable, highly redundant, and network-accessible is handled by the distributed storage layer. We chose this path so that we maintain 100% Postgres compatibility (extensions, planner behavior, etc.) and can take advantage of the huge ecosystem and community.
From a performance standpoint, Xata’s storage architecture is built for low-latency and high throughput. The storage nodes bypass the kernel using user-space drivers via SPDK (Storage Performance Development Kit) to squeeze every drop of performance from NVMe drives. Data is synchronously replicated across nodes with an erasure-coding scheme for fault tolerance (think RAID, but distributed at cluster level). In plain English: it’s fast and durable. We’ve benchmarked it and, even with a network hop, observed throughput and latency very close to well-tuned local-NVMe setups and markedly faster than typical cloud block storage (e.g., EBS/RDS) or modern serverless solutions. We plan to publish these benchmarks soon.
Because the Xata stack has been built with a cloud-agnostic architecture that is out-of-the-box Postgres on Kubernetes with a self-contained storage layer, we can offer Bring-Your-Own-Cloud deployments with minimal lift. Our control plane can launch the Postgres compute nodes in your cloud account or bare metal servers, attaching to the Xata storage cluster over the network. The data stays in your environment and never traverses the public internet. This is a big advantage in enterprise scenarios where this level of scrutiny matters.
Neon
Neon can be credited for building the first open-source storage-compute separation design for Postgres. They implemented it by building a bespoke storage engine for Postgres. In Neon’s architecture, when a Postgres compute node runs, it does not write to local disk. Instead, it streams all its WAL (write-ahead log) to a service called Safekeepers. Safekeepers are like a durable WAL buffer. They accept the WAL entries and replicate them across availability zones to ensure they’re not lost. Meanwhile, another component called the Pageserver is responsible for actual data storage. Pageservers consume the WAL stream from Safekeepers and apply it to a database page store. They keep recently used pages in memory and also store data on disk or in cloud object storage as the source of truth.
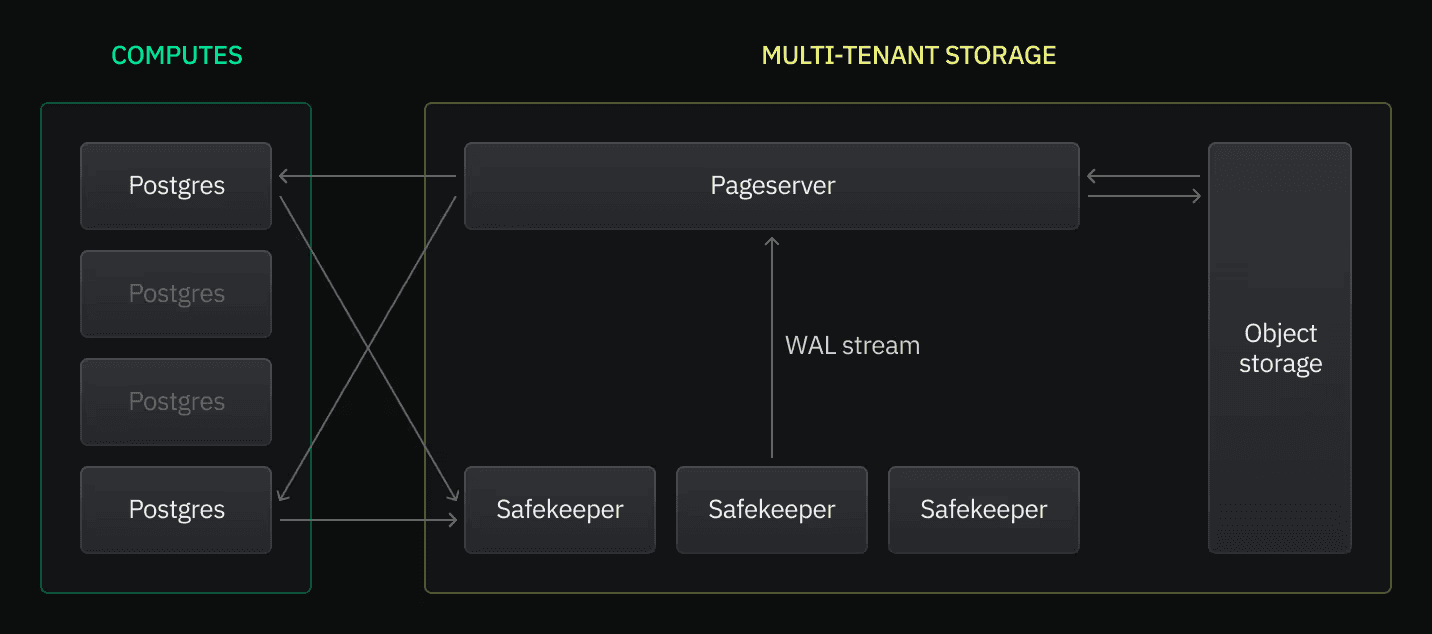
Diagram taken from Neon’s architecture documentation.
How does Neon achieve branching? They use a non-overwriting storage format in the pageserver. Essentially copy-on-write at the page/version level. When you create a branch in Neon, under the hood it’s like creating a new timeline starting at a specific WAL LSN (log sequence number). The pageserver doesn’t duplicate all pages for the new branch; it just starts a new sequence of WAL for it. Initially, the branch shares all history with its parent until a divergence occurs. Only when new WAL comes in (writes on the branch) do new page versions get written. This is effectively the same outcome as Xata’s copy-on-write, just implemented via a logical WAL timeline mechanism rather than at the block device layer.
One effect of Neon’s approach is that the Postgres compute nodes are stateless. If a compute node crashes or is stopped (say due to inactivity), you can later spin up a new compute node, point it at the appropriate timeline (branch), and it will retrieve whatever pages it needs from the pageserver. This is how Neon achieves scaling to zero and fast cold starts. The database state persists in the pageserver/S3, and a compute node can be brought up on demand to service queries, then shut down when idle.
The trade-off is that Neon’s architecture introduces additional indirection and complexity in the performance-critical data path (WAL network hops, page retrieval on cache miss). In other words, there is some inevitable overhead compared to a single-node Postgres with network attached storage. Particularly for very write-heavy workloads or very random OLTP reads that can’t all fit in memory. For many developer and test workloads, this overhead is might be acceptable. At larger scale or sustained high throughput, data retrieval might observe higher tail latencies due to that extra network/storage indirection. This additional complexity is one of the disadvantages of running a modified version of Postgres.
Supabase
Supabase’s approach to branching is the simplest conceptually. Each branch is just a new Postgres instance (plus the accompanying services) created from scratch. When you create a branch in Supabase, the platform essentially provisions a new Postgres container (or VM) for that branch, sets up a blank database, runs your migration + seed scripts to create the schema and to populate data.
Diagram taken from Supabase’s documentation.
There is no special storage magic here like copy-on-write. If you want a branch to have production-like data, you have to script it. Today, that means writing a seed.sql that inserts sample rows or copying a subset of data from prod through your own processes. At the moment, Supabase explicitly does not clone your data into the branch.
Because each branch is a full Postgres instance, they are fully isolated at the OS level (not just at data level). Aside from shared control plane components, one branch’s activity can’t impact another’s performance since they don’t share underlying storage or CPU. This is good for isolation, but it means branches are heavier weight. Supabase mitigates cost by auto-pausing these preview branches when not in use. Unless the branch is marked as persistent, you’ll incur a cold start after it’s been idle for > 5 minutes. You can mark any branch as persistent and flip between ephemeral and persistent options.
Supabase branching is leveraging the standard Postgres stack and as a result, the performance on a branch is the same as performance on any Postgres instance of that size. There’s no extra overhead of remote storage or CoW bookkeeping. The trade-off is that branch creation is much slower if you wanted to copy large amounts of data. In practice, Supabase expects you to only seed a small amount of data that is enough for simple tests. That is fine for testing logic and migrations, but it’s not adequate if you want to, say, test a complex query on a full-size dataset or train your latest model on production-like data. In those cases, Xata’s or Neon’s approach of branching the actual data shines.
Because each Supabase branch is a standalone Postgres, if your production DB is, say, 50 GB, and you wanted a full copy for staging, you’d need another 50 GB in storage for the branch. Xata and Neon would not double your storage unless you modified all that data in the branch. So for storage-intensive scenarios, Supabase’s model can be costlier.
Conclusion
Database branching isn’t a checklist feature, it’s a fresh take on how you should operate and interact with a database.
- Xata treats branches as light, block-level snapshots, so large teams can clone production-sized datasets safely and predictably.
- Neon re-architects Postgres for serverless elasticity and instant branches.
- Supabase keeps things familiar, favoring full stack branches with additional microservices around Postgres.
Features and architecture tell only half the story. What does this look like in the real world and how do these choices impact pricing and cost for customers? In part 2 we’ll translate architectures into invoices, walking through each pricing model and common branching scenarios.
If you’re a Postgres user and are branch-curious, I invite you to give Xata a try. We’re currently in private beta and onboarding new teams on a daily basis. You can sign up for early access here. Feel free to pop into our Discord to ask any questions or simply say hi.
In Part 2, we dive into the price differences between the three solutions across a variety of real-world scenarios. Read the follow up blog here.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Xata: Postgres with data branching and PII anonymization
Relaunching Xata as "Postgres at scale". A Postgres platform with Copy-on-Write branching, data masking, and separation of storage from compute.
PostgreSQL Branching: Xata vs. Neon vs. Supabase - Part 2
Take a closer look at PostgreSQL branching by comparing Xata, Neon, and Supabase on architecture, features, and real-world costs.