Schema changes and the Postgres lock queue
Learn how schema changes can cause downtime by locking out reads and writes and how migration tools can avoid it by using lock timeouts, along with backoff and retry strategies.
By:
Andrew FarriesPublished:
Reading time:
5 min readSchema changes are hard. They're hard because there are multiple different failure modes, some of which require knowledge of how the underlying RDBMS system works, especially with regard to object locking.
Broadly speaking, there are two classes of breakage that can occur when applying database migrations:
- Migrations that make incompatible changes to the schema, breaking client applications.
- Migrations that lock a database object for an unacceptable amount of time, causing the application to become unavailable as reads and writes start to fail.
The first kind of breakage is perhaps more widely understood and discussed, but the second kind is just as important to consider when running migrations against production systems.
Today we're going to talk about the second type of breakage: how long running queries together with DDL statements can lock out reads and writes from a table, causing application downtime.
An example
Let's understand how a seemingly innocent schema change can cause application downtime by locking out reads and writes to a table.
Setup
Let's create a table and insert some data into it. The amount of data doesn't matter as we'll use pg_sleep to simulate long-running queries.
Access share locks
A SELECT statement acquires an ACCESS SHARE lock on the table. This lock type is the least aggressive of the Postgres lock types and doesn't conflict with any other locks besides ACCESS EXCLUSIVE locks.
Let's see it in action by using pg_sleep to simulate a long-running SELECT query.
This statement acquires an ACCESS SHARE lock on the users table and holds it for 30 seconds per row. While the statement is executing, let's look at the pg_locks table that records information about the locks held by different processes:
The output should look like this:

An access share lock on the users table
Our SELECT statement has acquired an ACCESS SHARE lock on the users table. This lock doesn't conflict with any other lock types (apart from ACCESS_EXCLUSIVE) so it should be possible to run another SELECT statement while this one is still executing:
This statement executes directly, without having to wait for the first SELECT statement to release its lock on the users table.
Access exclusive locks
Many Postgres DDL statements attempt to acquire an ACCESS EXCLUSIVE lock on the table they are modifying. This lock type is the most aggressive and conflicts with all other lock types. Such DDL statements will block indefinitely until they are able to acquire their lock.
As before, let's simulate a long-running query that acquires an ACCESS SHARE lock on the users table:
Now let's see how a DDL statement blocks while trying to acquire an ACCESS EXCLUSIVE lock on the same table:
This ALTER TABLE statement attempts to acquire an ACCESS EXCLUSIVE lock on the users table but is unable to do so until the SELECT statement completes and releases its ACCESS SHARE lock.
So far, so good. What's the problem here? The DDL statement can simply wait patiently until it's able to acquire its ACCESS EXCLUSIVE lock, right? The problem is that any other statements that require a lock on the users table are now queued behind this ALTER TABLE statement, including other SELECT statements that only require ACCESS SHARE locks.
This means that the table is effectively blocked for reads and writes until the ALTER TABLE statement completes. SELECTs and UPDATEs will queue up behind it, unable to execute. If there is a long-running query that prevents the ALTER TABLE from acquiring the lock, then reads and writes will be blocked for the duration of that query.

The long running query (1) causes the DDL statement (2) to block, with the SELECT (3) and INSERT (4) statements queued behind it
The pg_locks table doesn't help us to visualize the lock graph of which statements are blocked on which others. To do that we can use the pg_blocking_pids function in combination with pg_backend_pid to find the process ID of the blocked processes. Using the process ids in the above screenshot we obtain:
Which can be visualized as the following graph:
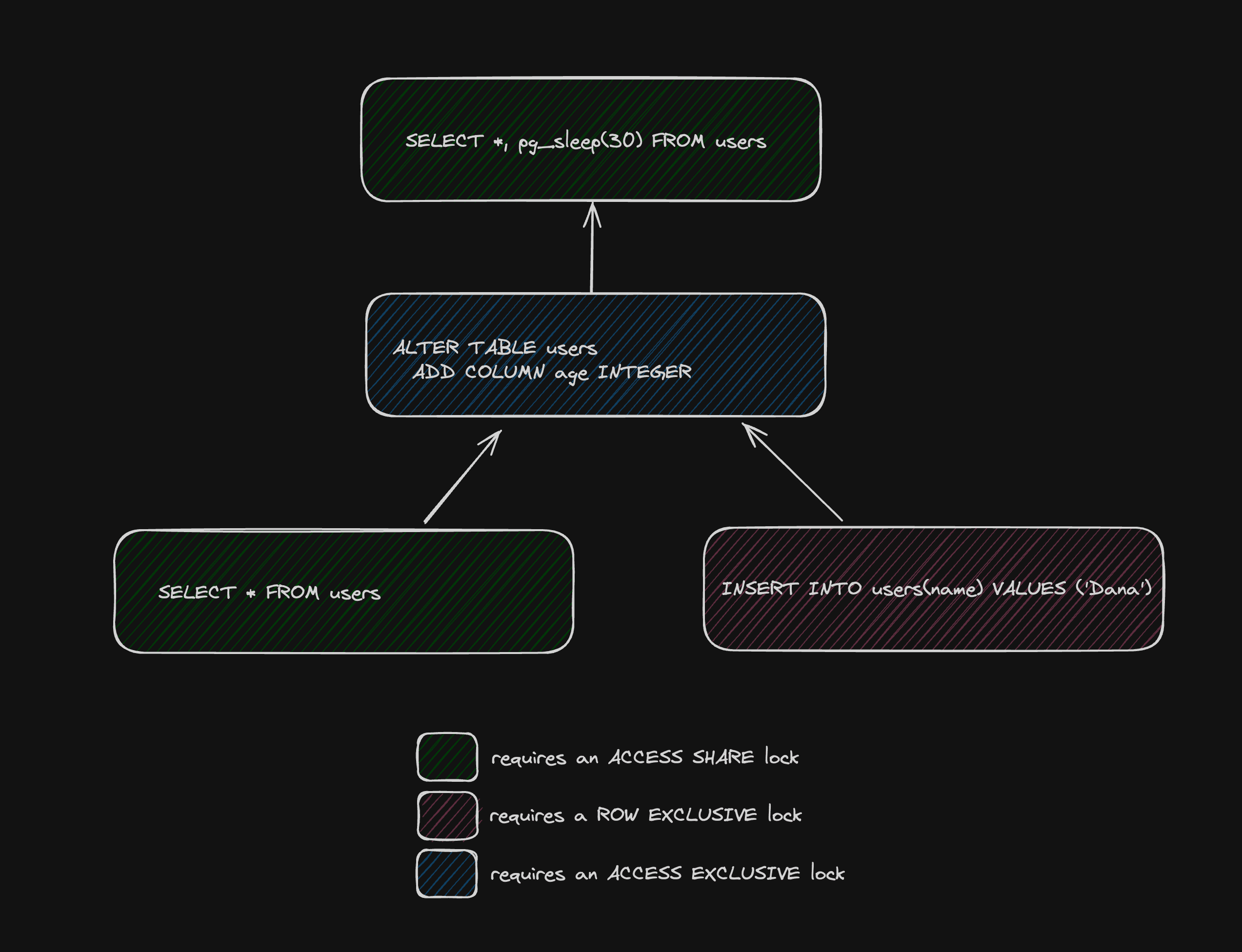
The lock tree: the ALTER statement is blocked on the long-running SELECT. The bottom two DML statements are queued behind the ALTER statement
The SELECT and INSERT statements are queued behind the ALTER TABLE statement, which is in turn blocked behind the long-running SELECT statement. This means reads and writes are locked out of the users table until the ALTER TABLE statement acquires its lock. Depending on the duration of the long running SELECT statement, this could mean application downtime as read/write operations against the users table are unable to proceed.
Postgres lock_timeout setting
Postgres provides the lock_timeout setting to control how long statements should wait to acquire locks before giving up.
By setting a lock_timeout on the ALTER TABLE statement it's possible to prevent other queries from queueing behind it for an unacceptable length of time:
In one session run:
As before, this statement holds an ACCESS SHARE lock on the users table for 30 seconds per row.
In another session:
In a third session:
After 1 second, the ALTER TABLE statement fails with an error like below:canceling statement due to lock timeout
Once the ALTER TABLE statement has failed, the SELECT statement from the third session is unblocked and executes directly.
DDL statements in migration sessions should always set lock_timeout to an appropriate value for the application; values of less than 2 seconds are common. This ensures that reads and writes won't queue behind a blocked DDL statement and cause application downtime.Backoff and retry
With lock_timeout set appropriately like this, it's possible to ensure that DDL statements like ALTER TABLE don't lock out reads and writes from the affected table. However, when a statement exceeds its lock_timeout the statement fails. Postgres does not provide any mechanism by which such statements can be automatically retried. Retrying lock acquisition becomes the responsibility of the person or process running the DDL statement.
With pgroll, our migration tool for Postgres, such lock acquisition failures are automatically retried with an exponential backoff strategy. This means that:
- The risk of DDL statements blocking reads and writes is reduced, due to the use of
lock_timeout. - If lock acquisition fails, the DDL is automatically retried and should eventually succeed.
However you make schema changes to your Postgres database, it's important to consider how long running queries together with DDL statements can block reads and writes to a table. Setting lock_timeout on DDL statements is a good first step, but it's also important to consider how to handle lock acquisition failures.
Conclusion
At the top of the post, we identified two common failure modes for database migrations:
- Schema changes breaking client applications.
- Unintended downtime due to DDL-induced table locks.
pgroll is a migration tool for Postgres that attempts to address both of these failure modes. Its 'headline feature' is its ability to make two versions, old and new, of a database schema available to client applications. This mitigates the risk of schema changes breaking applications. We've previously blogged about this here, and the topic is well-covered in the official pgroll docs.
In this post we've seen another migration failure mode: how DDL statements, if they are unable to acquire their locks, can cause reads and writes to queue behind them and how a good migration tool should handle this scenario with correct use of lock_timeouts together with backoff and retry.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Anatomy of Table-Level Locks in PostgreSQL
This blog explains locking mechanisms in PostgreSQL, focusing on table-level locks that are required by Data Definition Language (DDL) operations.
Anatomy of table-level locks: Reducing locking impact
Not all operations require the same level of locking, and PostgreSQL offers tools and techniques to minimize locking impact.