Going down the rabbit hole of Postgres 18 features
PostgreSQL 18 brings async I/O (2-3x faster sequential scans), native UUIDv7, OAuth 2.0, virtual generated columns, and stats that survive upgrades.
By:
Tudor GolubencoPublished:
Reading time:
17 min readLast week, Postgres 18 has been marked as stable. The highlights are fundamental features like the Async IO infrastructure and the Oauth 2.0 support, performance optimizations like the btree skip scan, and highly anticipated features like the native UUIDv7 support.
But with over 3000 commits contributing to the release, there are many other changes beyond the highlights that you might want to know about. We set to go through as many changes as possible, and we ended up covering about 30 features in this long blog post (almost 5000 words).
New Postgres versions are exciting! But upgrading is scary. Xata gives you instant database branching so you can test and merge major changes fearlessly.
Get access →
If there’s no way you’re reading all this, I don’t blame you, so here is an attempt at a TL;DR:
- Async IO is a fundamental change with a lot of promise, but it’s only used in some situations for now, so the full benefits might not yet show up in your use-case.
- There are a few changes in default behavior (e.g. VIRTUAL for generated columns), but overall it should be an easy upgrade, without (or with minimal) impact to your application code.
- There are tons of improvements in each of the following categories:
- Developer convenience (uuidv7, RETURNING old/new, virtual generated columns, temporal db).
- General operations (faster upgrades, oauth, vacuum, extension management).
- Performance optimizations for particular cases (btree indexes, planner improvements).
- Observability/monitoring (per process stats, EXPLAIN improvements).
I do recommend reading the whole thing if you have time, though, because there are many interesting details. We’ve included code examples and snippets from the commit messages.
Async IO
Up until this version, Postgres used synchronous IO (think of read() and write() system calls) and relied on the operating system to hide the cost of synchronous IO. It did use posix_fadvise, a system calls that “hints” to the OS how the application plans to access the file. By introducing asynchronous IO (AIO), Postgres gets two main benefits, which I’m summarizing from the AIO readme:
- more direct control over sending IO requests in parallel and earlier, to minimize waiting for IO.
- support for Direct IO, which can copy between the storage and the Postgres buffer pool using DMA, so without keeping the CPU busy
These ultimately result in better performance and lower resource utilization. It is expected to be especially beneficial for network attached storage that supports a high degree of parallelism. At Xata we use NVMe-over-Fiber, which is a sweet-spot use cases for AIO, so we’re particularly excited for this.
While the AIO framework is introduced, it’s not used yet everywhere, so expectations need to be managed for now. This blog post from Tomas Vondra contains the best performance overview that I’ve seen.
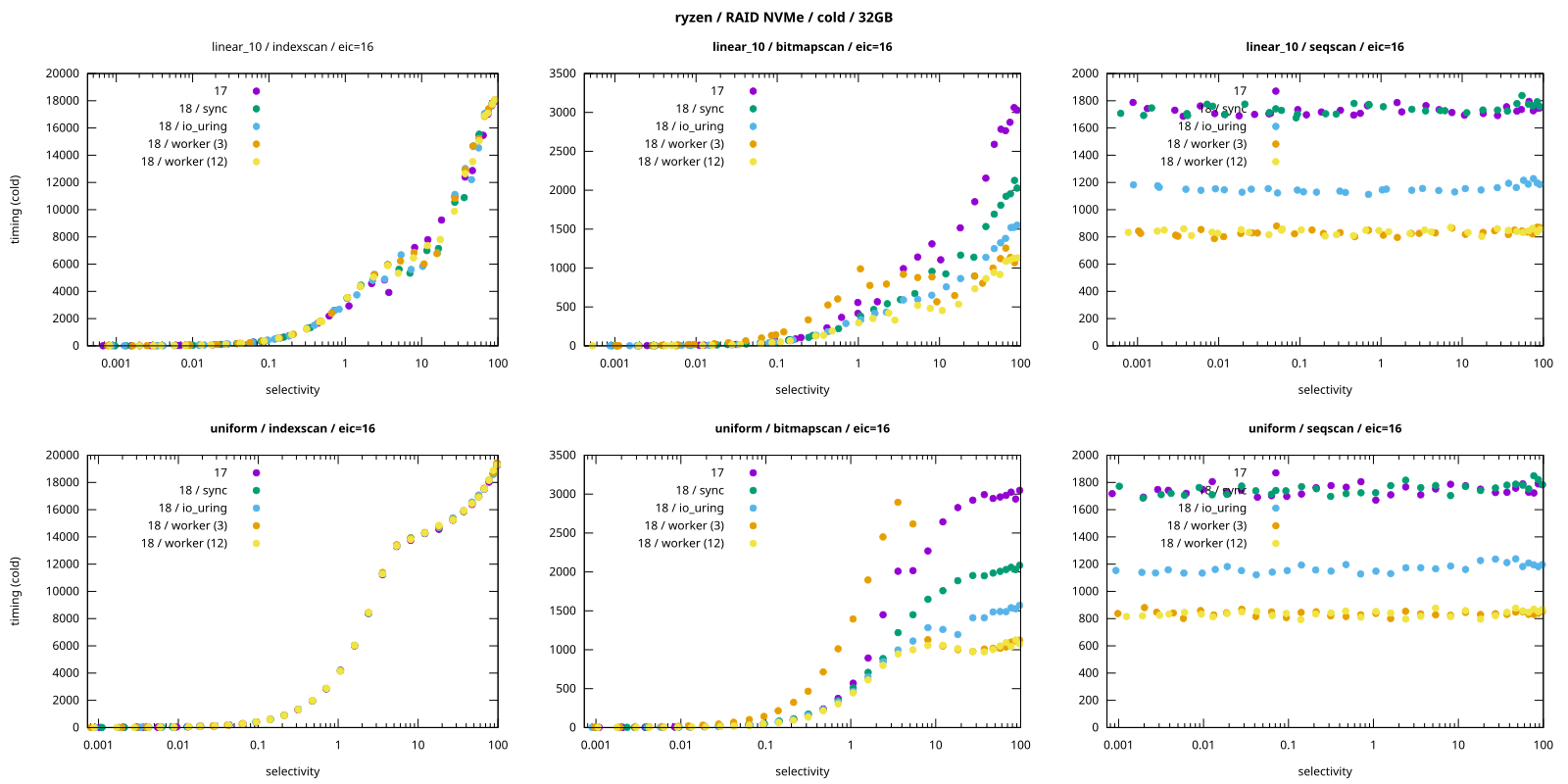
Source for the image is a blog post by Tomas Vondra
In short:
- Sequential scans show 2x or 3x improvement!
- Index scans show no improvement.
- Bitmap scans show some improvement but also regressions in performance when used with low
io_workers
In addition, AIO should already reduce the overhead of background maintenance tasks.
OAuth 2.0
OAuth support means that there is now a good and standard way to avoid those shared long-term passwords. Instead you can get interactive access to Postgres using your SSO provider, and applications can authenticate with Postgres using OAuth workflows.
In practice, a Postgres connection string might look something like this for interactive logins:
And applications can use tokens via a connection string like this:
We are looking at adopting this for Xata in the near future as an alternative to static passwords.
Improvements for developers
If you are using PostgreSQL from a developer perspective, this is the section that you’ll likely be most interested in.
UUID v7
How to generate PKs is a favorite dev debate topic, and now there’s an easy go-to. Before Postgres 18, you could use the native UUID type with UUID v4, but that came with a performance penalty because UUIDv4 are not monotonic which means they affect index locality and they don’t compress well. These issues are solved by UUIDv7, which are sortable and embed the current time at the beginning.
Since the UUIDv7 spec allows for some freedom in implementation here are the Postgres specific details, taken from the commit message:
In our implementation, the 12-bit sub-millisecond timestamp fraction is stored immediately after the timestamp, in the space referred to as "rand_a" in the RFC. This ensures additional monotonicity within a millisecond. The rand_a bits also function as a counter. We select a sub-millisecond timestamp so that it monotonically increases for generated UUIDs within the same backend, even when the system clock goes backward or when generating UUIDs at very high frequency. Therefore, the monotonicity of generated UUIDs is ensured within the same backend.
Simple usage looks like this:
The function allows a parameter of type interval, which you can use get a UUIDv7 with a timestamp from the past or from the future. For example, this would give a UUIDv7 with a timestamp from yesterday:
And you can verify by extracting the embedded timestamp like this:
RETURNING now can specify OLD/NEW
This one might actually be my favorite feature as a developer, because I know how much code and complexity it’s going to reduce. The feature makes the RETURNING clause able to explicitly return old and/or new values by using the special aliases old and new. These aliases are automatically added to the query, unless they already defined by the query.
Here is a quick UPDATE example:
While UPDATEs like the above are the most clear use case, this also works with e.g. INSERT ... ON CONFLICT ... DO UPDATE .
Virtual Generated columns, computed on read
Postgres 18 adds a new variant of generated columns: VIRTUAL. They are computed on read, like a view, unlike the stored generated columns, which are computed on write, like a materialized view.
Here is a quick example:
One thing to be careful with: VIRTUAL is the default now, so if you restore a schema from an older version of Postgres, your generated columns will essentially switch from virtual to stored. The motivation for making VIRTUAL the default is in the commit message:
VIRTUAL is the default rather than STORED to match various other SQL products. (The SQL standard makes no specification about this, but it also doesn't know about VIRTUAL or STORED.) (Also, virtual views are the default, rather than materialized views.)
Another thing to note from the commit message: they are computed on read, but they are not quite zero-cost when it comes to storage:
Virtual generated columns are stored in tuples as null values. (A very early version of this patch had the ambition to not store them at all. But so much stuff breaks or gets confused if you have tuples where a column in the middle is completely missing. This is a compromise, and it still saves space over being forced to use stored generated columns. If we ever find a way to improve this, a bit of pg_upgrade cleverness could allow for upgrades to a newer scheme.)
Generated columns included in logical replication
Speaking of generated columns, Postgres 18 adds the ability to include them in the logical replication stream. Previously the assumption was that the follower replica can generate them again, however logical replication is used for much more than just Postgres to Postgres these days.
This is great news for CDC tools like pgstream and Debezium, who now can get the generated columns.
Temporal DB improvements
First, let’s quickly define temporal databases: they are databases that keeps track of time-varying data. Instead of storing only the latest state of information, a temporal database records not only what the data is, but the history of what the data was over its lifetime.
Postgres 18 improves the temporal DB use case by supporting WITHOUT OVERLAPS clause for primary key and unique constraints. This pushes Postgres closer to temporal database capabilities by enforcing the key temporal rule: for the same business key, valid-time periods must not overlap.
We’re working on an in-depth blog post about using PostgreSQL as temporal DB, but for now a quick example:
The above PK guarantees that the same room is not overbooked at any point in time.
In addition, foreign key constraints can now reference periods via the PERIOD keyword. This is supported for range and multirange types. Temporal foreign keys check for range containment instead of equality.
Create NOT NULL constraint with NOT VALID
This change adds NOT NULL constraints to the list of constraints that you can add as NOT VALID. What does that mean? Let’s say you have a column that currently has NULL values in it. You can’t simply add the NOT NULL constraint because it would be invalid (plus it will lock the table while Postgres verifies all values). If you first backfill the data to remove the NULLs, you risk new inserts adding more NULL values.
Instead, NOT VALID allows the following:
- Add the constraint as
NOT VALID. This is a fast operation because it doesn’t check the existing rows. But from now on, inserts must specify a not-null value for the given column. - Backfill the data to remove all NULLs.
- Validate the constraint. This is done without locking the table for reads and writes (technically there is still a lock, but doesn’t block reads or writes).
Here is a sample session:
Small plug: pgroll is an open-source project of ours that helps you do all sorts of schema changes without locking and makes schema changes easily reversible.
NOT VALID FK constraints on partitioned tables
Another win for schema change operations, with similar benefits to the above, foreign key constraints on partitioned table can be declared NOT VALID. For example, if events is a partitioned table, with data referencing an accounts table, the following works:
And the validation can be checked partition by partition, which is convenient if you want to further minimize locking.
New protocol version
Postgres 18 increments the version of the wire protocol for the first time since 2003! It’s also the first time when the minor version number is incremented. The new version is 3.2, and the description contains the reason for the version bump:
The secret key used in query cancellation was enlarged from 4 bytes to a variable length field. The BackendKeyData message was changed to accommodate that, and the CancelRequest message was redefined to have a variable length payload.
If you’re curious why it’s version 3.2, and not version 3.1, the answer is on the same page linked above:
Reserved. Version 3.1 has not been used by any PostgreSQL version, but it was skipped because old versions of the popular pgbouncer application had a bug in the protocol negotiation which made it incorrectly claim that it supported version 3.1.
The libpq client library still uses version 3.0 by default for now, until the upper layers (e.g., drivers, poolers, proxies) add support for the new protocol version. This, and the fact that the breaking change is small, means we shouldn’t see compatibility issues caused by the new version.
Improvements for operations
Faster major version upgrades
Major version upgrades are another topic that we’ve been putting effort into here at Xata. Postgres 18 brings several promising improvements in this space.
First, pg_upgrade should generally be faster, especially when you have many database on the same cluster, or more generally, lots of objects (tables, views, sequences, etc.). This is because it now has a framework to do multiple “jobs” in parallel and because it’s smarter about avoiding unnecessary work and fsyncs.
Secondly, pg_upgrade now also transfers the statistics from the previous version, which means the planner will have post-upgrade the critical information it needs to do it’s job optimally. This reduces the risk of a performance hit after the upgrade.
What I find particularly cool about this, is that the statistic transfer is actually done by pg_dump, which now gets the --no-statistics and --statistics-only options. So you can use this in other situations as well, for example, for Blue-Green deployments via logical replication.
Easier extension management in K8s environments
There is a new extension_control_path config setting that allows on to control where Postgres is looking for extensions. This addition was proposed by the CloudNativePG project, with the end goal of making declarative extension management easier/possible for Kubernetes operators.
Before this, because the images need to be immutable, the only really viable solution was to build custom images with the subset of extensions that you need. Now it will be possible to use a minimal image and instead mount image volumes with other extensions.
It’s another feature that we’ll be taking advantage at Xata, ultimately resulting in better security and more flexibility in adding new extensions.
VACUUM improvements
Postgres 18 comes with several vacuum-related improvements.
This one softens the cost of aggressive vacuums. Aggressive vacuums are needed when Postgres realizes that there is a risk of transaction wraparound, so it knows it needs to freeze old tuples (rows) quicker.
To amortize the cost of aggressive vacuums, Postgres 18 eagerly scans some all-visible but not all-frozen pages during normal vacuums. This means more work during normal vacuum, but much better at avoiding the worst case scenarios.
Postgres 18 also changes the calculation for the insert threshold to not contain the frozen pages, which means that it will be generally be more frequent on insert heavy-table.
Observability of vacuums also gets better, as there is now a new setting called track_cost_delay_timing for collecting timing statistics for cost-based vacuum delay. Note that this parameter is off by default, as it will repeatedly query the operating system for the current time, which may cause significant overhead on some platforms. Luckily Postgres comes with a handy tool pg_test_timing so you can know if enabling on your architecture is a good idea.
Improvements for observability / monitoring
EXPLAIN improvements
Postgres 18 comes with several small improvements to the EXPLAIN statement.
Notable is that BUFFERS is now the default when running EXPLAIN ANALYZE . The commit message explains (pun intended) the rationale in changing the default:
The topic of turning EXPLAIN's BUFFERS option on with the ANALYZE option has come up a few times over the past few years. In many ways, doing this seems like a good idea as it may be more obvious to users why a given query is running more slowly than they might expect. Also, from my own (David's) personal experience, I've seen users posting to the mailing lists with two identical plans, one slow and one fast asking why their query is sometimes slow. In many cases, this is due to additional reads. Having BUFFERS on by default may help reduce some of these questions, and if not, make it more obvious to the user before they post, or save a round-trip to the mailing list when additional I/O effort is the cause of the slowness.
Besides the above, EXPLAIN includes more and improved information: memory/disk usage for Material nodes, index search counts, number of disabled nodes, and more.
More statements in pg_stat_statements
Another improvement that will help with observability: statements like CREATE TABLE AS and DECLARE CURSOR now assign query IDs to inner queries created by them. The benefit of this is that those queries will now show up in e.g. pg_stat_statements , because a query id is required for that.
Logging of lock acquisition failures
This change introduces a new configuration parameter: log_lock_failure. If enabled (it’s off by default), a detailed log message is produced when a lock acquisition fails. Currently, it only supports logging lock failures caused by SELECT ... NOWAIT.
The log message includes information about all processes holding or waiting for the lock that couldn't be acquired, helping users analyze and diagnose the causes of lock failures.
Per process statistics
This change improves the stats infrastructure to be able to keep per-process statistics, available during the life of the process. The commit message explains how it works:
This adds a new variable-numbered statistics kind in pgstats, where the object ID key of the stats entries is based on the proc number of the backends. This acts as an upper-bound for the number of stats entries that can exist at once. The entries are created when a backend starts after authentication succeeds, and are removed when the backend exits, making the stats entry exist for as long as their backend is up and running.
The first user of this new infrastructure is a new function: pg_stat_get_backend_io() which collect IO stats for a particular backend/process. Example usage:
Tracking connection establishment durations
Postgres 18 adds the option to log the time spent establishing the connection and setting up the backend until the connection is ready to execute its first query. The log message includes three durations:
- The total setup duration (starting from the postmaster accepting the incoming connection and ending when the connection is ready for query)
- The time it took to fork the new backend
- The time it took to authenticate the user
To enable this, you need to add setup_durations to the log_connections configuration parameter.
Performance improvements and optimizations
Index optimization: B-tree skip scan
Let’s say you have a multi-column index like (col1, col2, col3). Before Postgres 18, an index like this would be used efficiently only if the the leftmost columns are specified in the condition. So all of these would use the index:
But these would typically not use the index:
This is because multi-columns indexes store the key ordered by the tuple (col1, col2, col3) and therefore can use any prefix of it.
Postgres 18 has the ability to use the index efficiently also in those last two examples. The way it works is that it jumps between col1 values and reads the relevant portions of each “section” of the index.
This works better if col1 is low cardinality, because then it can skip the most. So when defining the multi-column indexes it makes sense to put the lower-cardinality columns first.
Here are a few relevant passages from the well documented commit:
Teach nbtree multi-column index scans to opportunistically skip over irrelevant sections of the index given a query with no "=" conditions on one or more prefix index columns. When nbtree is passed input scan keys derived from a predicate "WHERE b = 5", new nbtree preprocessing steps output "WHERE a = ANY(<every possible 'a' value>) AND b = 5" scan keys. That is, preprocessing generates a "skip array" (and an output scan key) for the omitted prefix column "a", which makes it safe to mark the scan key on "b" as required to continue the scan. The scan is therefore able to repeatedly reposition itself by applying both the "a" and "b" keys. […] Testing has shown that skip scans of an index with a low cardinality skipped prefix column can be multiple orders of magnitude faster than an equivalent full index scan (or sequential scan). In general, the cardinality of the scan's skipped column(s) limits the number of leaf pages that can be skipped over.
SQL-language functions use the plan cache
This helps queries in SQL functions to be inlined better. From the commit message:
In the historical implementation of SQL functions (if they don't get inlined), we built plans for all the contained queries at first call within an outer query, and then re-used those plans for the duration of the outer query, and then forgot everything. This was not ideal, not least because the plans could not be customized to specific values of the function's parameters.
Self-Join Elimination
The Self-Join Elimination (SJE) feature removes an inner join of a plain table to itself in the query tree if it is proven that the join can be replaced with a scan without impacting the query result.
This optimization, which reduces a form of redundancy, essentially results in better planner estimations and less work for the next layers and . Particularly partitioned tables benefit from it, because the potential for partition pruning can be identified earlier.
Detect redundant GROUP BY columns using UNIQUE indexes
This planner optimization applies where you GROUP BY a multi-column UNIQUE index. In that particular case, Postgres can simply use only one column, since the UNIQUE index ensures the groups would be equivalent.
Here is an example that benefits from this optimization:
Postgres already did this for Primary Keys, and now it expanded this optimization for any multi-column UNIQUE key. Note that the columns in the UNIQUE index need to marked as NOT NULL or the index must use NULLS NOT DISTINCT.
Reordering DISTINCT values to reduce sorting
When you use DISTINCT on multiple columns, the order of those columns in the DISTINCT clause is not significant, so the optimizer can reorder in such a way that it best matches its needs. Here is an example to illustrate:
This behavior is now the default, but it can be disabled via a new config setting: enable_distinct_reordering.
Convert 'x IN (VALUES ...)' to 'x = ANY ...' when possible
The point of this optimization is that it simplifies the query tree, eliminating the appearance of an unnecessary join. Here is an example situation:
Note the plan mentioning the ANY condition. So the equivalent SQL is:
The commit message explains why this is faster:
Since VALUES describes a relational table, and the value of such a list is a table row, the optimizer will likely face an underestimation problem due to the inability to estimate cardinality through MCV statistics. The cardinality evaluation mechanism can work with the array inclusion check operation. If the array is small enough (< 100 elements), it will perform a statistical evaluation element by element.
Case folding
Postgres 18 adds a new casefold() function which is similar to lower() but avoids edge-case problems for caseless matching. For collations that support it, casefold() handles characters with more than two case variations or multi-character case variations.
Here are some examples (taken from the mailing-list) of edge-cases that casefolding works better than lowering:
- Some characters have more than two cased forms, such as "Σ" (U+03A3), which can be lowercased as "σ" (U+03C3) or "ς" (U+03C2). The
casefold()function converts all cased forms of the character to "σ". - The character "İ" (U+0130, capital I with dot) is lowercased to "i", which can be a problem in locales that don't expect that.
- If new lower case characters are added to Unicode, the results of
lower()may change.
Faster lower(), upper()
Related to the above, Postgres 18 has faster implementation for lower() and upper() as well. The optimization consists in how the mapping tables are generated, with the following benefits (taken from the mailing-list):
- Removed storing Unicode codepoints (unsigned int) in all tables.
- Reduce the main table from 3003 to 1575 (duplicates removed) records.
- Replace pointer (essentially uint64_t) with uin8_t in the main table.
- Reduced the time to find a record in the table.
- Reduce the size of the final object file.
The commit message includes a note of other approaches considered:
Other approaches were considered, such as representing these ranges as another structure (rather than branches in a generated function), or a different approach such as a radix tree, or perfect hashing. The author implemented and tested these alternatives and settled on the generated branches.
Faster GiST index building for ranges
GiST supports a “sorted build” mode: if the input tuples are already sorted, it can build the tree much faster and with better packing. But to sort ranges efficiently, the planner/executor needs a special sortsupport function. This is added with this commit.
Array convenience functions
Postgres 18 comes with two nice convenience functions for arrays: array_reverse() and array_sort().
Quick examples for each:
json_strip_nulls() removes null array elements
The JSON function json_strip_nulls(), gets a new parameter: strip_in_arrays. It defaults to false. If true, then null array elements are removed as well as null valued object fields. JSON that just consists of a single null is not affected.
Add function to get the ACL for a database object
Postgres 18 introduces a new function, pg_get_acl(), which is useful for retrieving and inspecting the privileges associated with database objects. Here is an example:
In the above, you can see that the bar role gets read access, and the baz role gets write access.
Try it on Xata
PostgreSQL 18, including Async IO with or without io_uring, is available today on the Xata platform. If you’d like to take it for a spin, request access and make sure to mention Postgres 18 or this blog post.
Give every agentic workload its own Postgres branch
Create instant database clones with production-like data for every agent, workflow, and CI/CD pipeline.
Related Posts
Xata: Postgres with data branching and PII anonymization
Relaunching Xata as "Postgres at scale". A Postgres platform with Copy-on-Write branching, data masking, and separation of storage from compute.