A new trend for databases: platforms
It's about more than the data stored in your table; it's what you can do with that data.
Written by
Tudor Golubenco
Published on
February 3, 2023
Lee Robinson, of Vercel, recently wrote a blog post summarizing the 2023 State of Databases for Serverless & Edge . It’s a great overview that shines a light on what’s new on the horizon. In the trends section, listed first, we find:
Databases are increasingly becoming data platforms, including other adjacent solutions like full-text search and analytics.
Yes! That sounds a lot like Xata, we are presenting ourselves as a Serverless Data Platform and we have full-text search and analytics built-in on top of the normal transactional/relational database.
I would define a data platform as a service that offers multiple types of data infrastructure integrated in a single Cloud service. For example, Xata is offering a database service on top of the PostgreSQL + Elasticsearch/OpenSearch combination, and we integrate them deeply into a single service. We automatically replicate the data between the two, and have a common consistent API, plus offer the same developer experience (including branches), and common SDKs.
The trend is larger than just Xata, and there are a number of “database startups” that combine functionality from multiple types of stores or data infra in order to offer more convenience to their users.
Let’s look at some examples (alphabetically sorted):
- AlloyDB, from Google, combines OLTP with OLAP, and uses the PostgreSQL wire protocol as an interface.
- Grafbase is using DynamoDB internally and they plan to add free-text-search.
- MongoDB Atlas is obviously using MongoDB but it is also offering free-text-search based on Lucene.
- PlanetScale is presenting themselves as a MySQL platform. In addition to MySQL, it uses Vitess for sharding and things like migrations, and they also have added caching infrastructure to their service.
- Supabase is based on PostgreSQL but also offers blob storage and image storage services.
- Tigris Data is based on FoundationDB and are replicating the data into Meilisearch for free-text-search.
- TimeScale adds timeseries functionality to PostgreSQL.
- Upstash offers serverless Redis and Kafka with HTTP APIs for both.
There are probably more, if you have other examples or corrections to the above, let me know and I will incorporate them.
As you can see, on top of the core database functionality, it’s becoming more and more common to see things like caching / edge caching infrastructure, search engines, blob storage, OLAP functionality, and time-series support.

To understand why this trend is happening, let’s look at what business value data platforms offer their customers.
If, for instance, data is automatically replicated between the database and the search engine, or the cache is invalidated when the data changes, this reduces the amount of code you need to write and maintain. This type of code is often difficult to get right and not particularly rewarding, so most teams would be grateful if someone else handled it.
We’re seeing many companies using many (>5) data stores and to operate them means they have to understand each of them pretty deeply: when to use each one, how to configure them, how to monitor them, how to optimize them, and so on. Even if they use managed services that take some of the operational load, the inconsistencies and the need to move the data between them ultimately means a lot of work, and teams are struggling with this.
Having consistent APIs, common SDKs, and — not less important — consistent documentation across data products simplifies the job of the developer. For example, the concept of branches has recently expanded to databases for deployment previews and for managing schema changes, but you only really reap the benefits of them if they work for all your data stores.
Want to add relevancy based free-text-search to your data table? You just call another API endpoint. There’s no new infrastructure to set up, and no replication of data. The data is already indexed for search and it’s ready for you to use it. Want to add edge caching for your queries? Just add a parameter. Smart cache invalidation is done automatically.
These examples show how integrated data platforms can make developing features a lot faster.
The data platforms have an opportunity to offer new abstractions on top of existing database technology. These abstractions can be better fit for modern tech stacks. In particular, frontend engineers that normally don’t get excited about databases are now enabled to create more complex and scalable applications than ever before. Building on a data platform can feel as simple as building on top of a headless CMS.
A key aspect here is how good the integration is. AWS already offers database services of all kinds and forms but they are tragically siloed. They have different APIs, different SDKs, different quality of documentation, different ways to configure and monitor them. This makes for clunky developer experience.
Modern data platforms can differentiate themselves at the infra layer and at the DX layer.
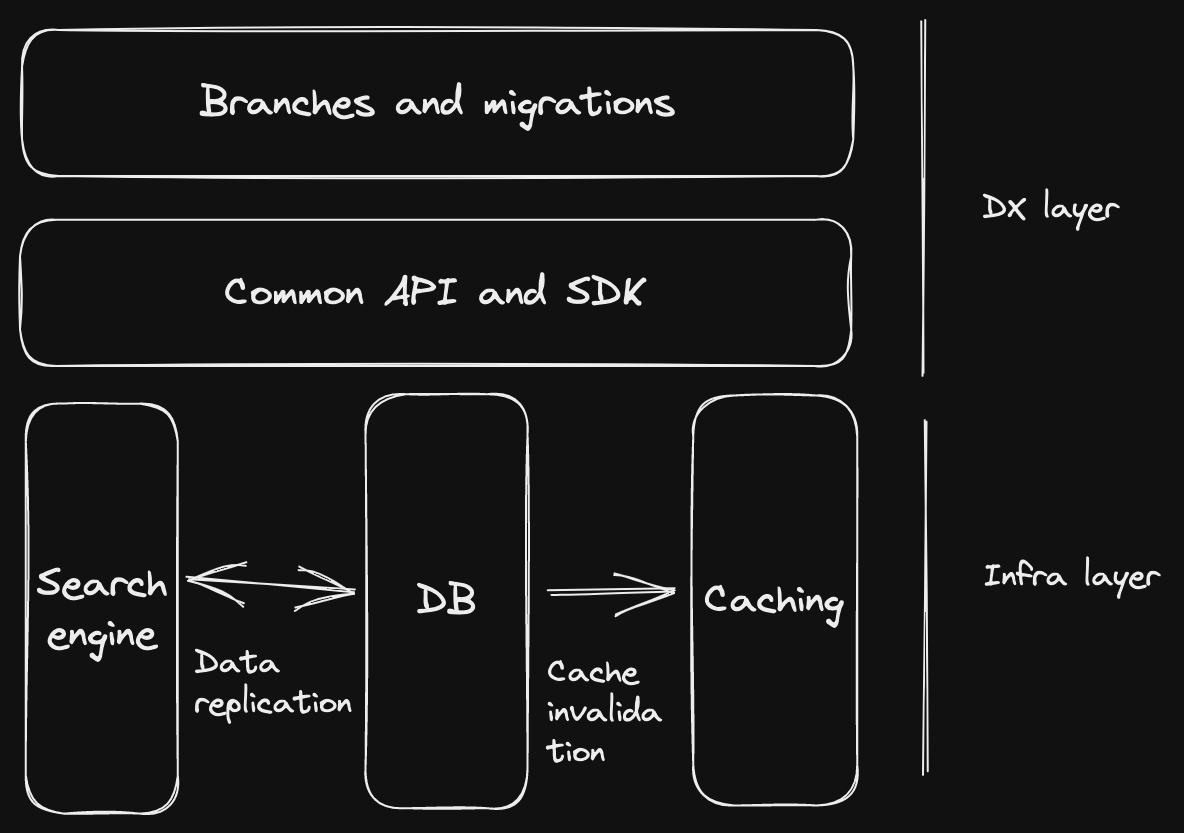
At the infra layer, data platforms can simplify the developers life by offering functionality that normally requires custom code. A few examples:
- keep data in sync between the DB and the search engine
- automatic cache invalidation when the data in the DB changes
- automatically delete files in the blob storage when the associated DB rows are deleted
- replicate data across regions globally
At the DX layer, data platforms can offer:
- API, SDK, and docs consistency
- better developer workflow via branches, safe migrations, and deploy previews
- less required configuration
Will this trend continue to grow? Time will tell, but we think it will.
If you’ve read this far, you might want to check out Xata, the scalable serverless database with built-in search that supports branching and works well with your existing TypeScript and Github workflows.
Start free,
pay as you grow
Xata provides the best free plan in the industry. It is production ready by default and doesn't pause or cool-down. Take your time to build your business and upgrade when you're ready to scale.
- Single team member
- 10 database branches
- High availability
- 15 GB data storage
- Single team member
- 10 database branches
- High availability
- 15 GB data storage
Copyright © 2025 Xatabase Inc.
All rights reserved.